


Hardware components | ||||||
| × | 1 | ||||
 |
| × | 1 | |||
| × | 1 | ||||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
| ||||||
This project is the first prize winner ($10,000) of the Adaptive Computing Developer Contest organized jointly by Hackster.io and Xilinx Inc. in the "Adaptive Intelligence of Things" category. Moreover, this project was also among the hardware winners of this contest.
This documentation includes necessary background information, a friendly explanation of the various concepts used in this project, my journey of creating this project, steps required to reproduce the results, a complete Bill of Materials (BOM), and an explanation of the code structure. It includes pointers to some of the essential parts of the code but not an explanation of every line, as it will be tedious. But the code itself is self-explanatory and well-commented.
Note: This documentation has a formal thesis like structure but it has more of an informal story-telling tone (of my thinking process and how I developed this project) rather than a formal one. Because sometimes it is fun to explain complex stuff informally. :)Abstract
In this project, a deep reinforcement learning (DRL) agent is trained and implemented on the programmable logic (PL) of Ultra96-V2 using the deep learning processing unit (DPU) and Vitis-AI (vai). The job of the agent is to hold the quadcopter’s position at a given setpoint (XYZ coordinates), to reach a given setpoint, and to be able to do the same while balancing a pole as well. The agent achieves this by controlling the quadcopter's thrust, roll, pitch, and yaw angles. The agent takes in the state of the quadcopter as input which consists of the given setpoint, current position, velocity, orientation, angular rates, and the XY position of the tip of the pole (if attached). The setpoint input to the quadcopter is given using hand gestures or a keyboard. The agent is trained using the twin delayed deep deterministic policy gradient (TD3) method, rank-based prioritized experience replay (PER), and weighted feedback from controllers in a semi-supervised setting. After training, the actor network is processed by vai-quantizer and vai-compiler to be deployed on Ultra96. The results of this project are shown in simulation and on Crazyflie 2.1 nano-quadcopter.
Why I chose this projectQuadcopters are popular among control systems, deep learning, other research communities, the photography & cinematography industry, and hobbyists. In a well-controlled fashion, they can be handy, e.g., for saving lives, delivering first aid kits in case of havoc, and other package deliveries. In the defense sector; for increasing the security of any particular area of interest. Similarly, in research, quadcopters achieve impressive performance in autonomous flight, tracking a high-speed trajectory that requires large accelerations, performing aggressive maneuvers, and working together in swarms [1], [2].
My primary motivation was creating an autonomous flight system using Xilinx’s SOC-FPGAs. I believe that autonomous flight systems are massive research and commercial markets. However, it still requires a tremendous amount of research and an investment of time and money. The benefits of this investment can be unbelievable and beyond our imagination in the next few decades. The future is all autonomous, and it is essential to head in this direction, especially in the IoT category. This project is also submitted for the IoT-based “Adaptive Intelligence of Things” category to make an initiative to attract deep learning and embedded systems practitioners towards this area.
The second motivation for me to go with this project was my true feelings for quadcopters which I developed after watching a TED talk video in 2016 by Prof. Raffaello D’Andrea and his research group at ETH-Zurich known as “Flying Machine Arena (FMA).” They showed how smart a quadcopter could be made. I was quite impressed by the video back then! And I promised myself that someday I would at least reproduce their results. xD
The third source was my suitable skill set, i.e., having 3+ years of experience, a sound background, and expertise in deep learning acceleration on Xilinx’s SOC-FPGA. My Bachelor’s Thesis was on hardware-aware training of deep neural networks and accelerating their inference on SOC-FPGAs.
Last but not least, the driving force for me was to learn and get a hands-on experience with DRL and implement something related to DRL and autonomous flight systems on a Xilinx device.
IntroductionTo understand this project's workings, a basic knowledge of calculus, control systems, python programming language, DRL, Xilinx’s SOC-FPGA, and pynq framework is required. I will provide all the necessary knowledge I gathered during this project's development. I will also add references for the reader keen to get in-depth knowledge. So, ladies and gentlemen, fasten your seat belts! And let’s start.
Quadcopter ModelFirst of all, we need to familiarize ourselves with the dynamics of the quadcopter model. There is one of the fundamental equations from calculus on which this model is based:
Here 𝑥 is the state of the quadcopter, which (in this project) is a vector consisting of current position 𝑝=[𝑥, 𝑦, 𝑧], velocity 𝑣=[𝑥′, 𝑦′, 𝑧'], orientation given in Euler angels 𝑜=[𝜙, 𝜃, 𝜓], angular rates 𝑤=[𝜙′, 𝜃′, 𝜓′], and the position of the pole (if it is attached) [𝑟, 𝑠].
Note: For simplicity we will ignore the pole attached (inverted pendulum) case for now and I will include sources for that in the references
World Frame vs. Body Frame
The state measurements are defined in two frames, i.e., the world frame and the body frame. E.g., the position and velocity are defined in the world frame. Whereas the orientation, angular rates, and pole position are defined in the body frame. The conversion of a vector from the body frame to the world frame and vice versa is done by multiplying it with the rotation matrices defined as:
Similarly, the rotation matrix for mapping angular rates 𝑤 to the approximate orientation 𝑜 is given as:
State Update
Now to update the quadcopter’s state with time, we need to find dX, which is given by:
The parameter values of the simulation are defined according to the physical model of the Crazyflie 2.0 nano-quadcopter [4].
- Quantities in bold represent vectors
- 𝑚𝑞 is the mass of the crazyflie
- 𝒈 is the gravitational acceleration vector, i.e.
[0,0,9.81]where +ve Z-axis is assumed downwards - ⊙ and ⊗ represents the dot and cross product of two vectors, respectively
- 𝑰 represents the constant inertia matrix of the crazyflie
- fdrag is the constant drag force experienced by the Crazyflie due to propellers
- fthrust is the input thrust force which given on a scale of 0-65535 for crazyflie
- ftorque is the input torque applied to the quadcopter’s body by the PID controllers to set the desired orientation
At a higher level, it can be viewed in a block diagram as:
Controllers
Thrust and torque forces are low-level control inputs. An attitude controller derives these forces based on high-level command inputs, i.e., roll, pitch, and yaw angles. The attitude controller is a simple PID controller, and its output is given by:
Where kp, ki, and kd are the PID gains tuned by hand.
Now with the attitude controller added to the simulation, the block diagram becomes:
In this setting, we can give the thrust and angle commands, and the quadcopter simulation will behave accordingly. To control the quadcopter’s position in the world frame, a position controller is added on top of the attitude controller, which can also be a simple PID controller. It takes in the desired XYZ position coordinates in the world frame and adjusts the thrust and Euler angles to move the quadcopter to the given point in space. After adding the position controller, the block diagram further becomes:
This way, we can provide a set point, and the quadcopter will reach and hold that point. This simple simulator was completed in the first ten days of the development and tested by plotting in matplotlib’s 3D plot, which was, sadly, neither fast nor beautiful and unsuitable, especially for testing on Ultra96.
Input Setpoint
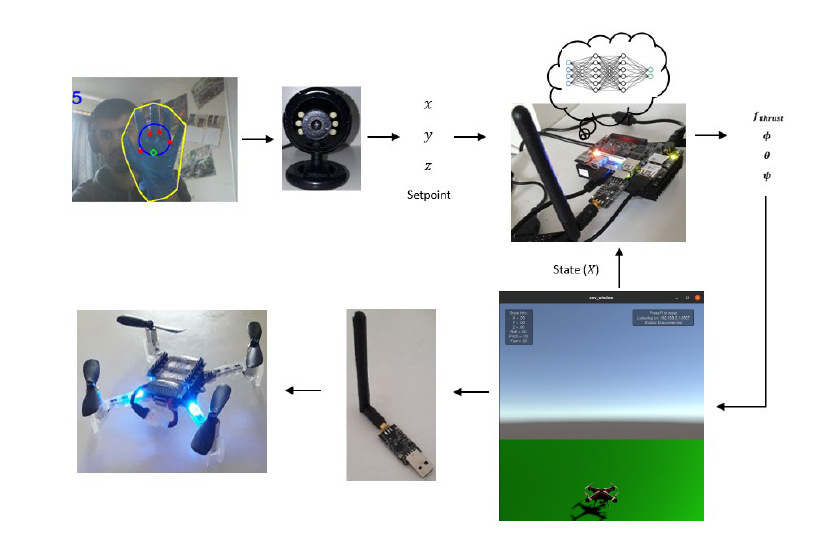
The input setpoint to the quadcopter can be given via keyboard or hand gestures. The keyboard controller is simple and uses the “w,a,s,d,i,j,k,l” keys. In contrast, the hand gesture controller identifies the open or closed fingers of the hand. To make hand detection and segmentation simple, I used color-based segmentation. By default, the hand wearing a blue-colored glove is segmented out, and the distance of the center of the hand from the center of the image, along with a gesture, is used to control the position setpoint. With no fingers open (fist), forward/backward (x-axis) and yaw rate can be controlled. Whereas with all fingers open (palm), up/down (z-axis) and left/right (y-axis) can be controlled.
The next step in developing the project was to view better what is going on inside the simulator, which is also particularly important when running on Ultra96-V2. This is done by creating a quadcopter environment model in unity 3D (personal edition), which uses C# programming language, and just passing the state information from the python simulator to the unity simulator. The state information from python to unity is passed via a high-speed network connection utilizing the ZMQ socket. Upon receiving the state from the python simulator via socket, the position (of quad and pole) and orientation are assigned to the unity model of the quadcopter.
There are two small technical details to mention. First, in unity, the positive y-axis is facing upward. So, we have to change the sign of the z-axis and swap it with the y-axis along with the corresponding Euler angles. Second, on every new connection to the unity simulator, the ZMQ socket has to be reset by pressing ‘R.’ As given in their documentation.
The quadcopter’s body used in the unity simulator is available here. The central part of the unity simulator development was to have a fast request/reply TCP socket connection and handle the state information. As an absolute beginner, it took me almost ten days and a lot of debugging to get it running smoothly.
This is the coolest but somehow difficult-to-grasp section. It requires elementary knowledge of deep learning and reinforcement learning (RL). So, what is RL? Before answering that, we should first know what it is not. RL is different than supervised and unsupervised learning. It does not have a finite dataset or labels to train on. The objective is not to fit the data by minimizing a loss function but to maximize a cumulative reward while interacting with an environment. It is unsuitable for classification or regression tasks but designed to optimize decision-making in a Markov Decision Process (MDP) framework. DRL is much more data-hungry than supervised learning.
DRL is a branch at the intersection of deep learning and RL in which a deep neural network is used as an agent that learns by trial and error. The agent interacts with the environment given in a state. It performs an action from a set of actions and observes the next state and a reward for that action. During learning, the agent’s goal is to find the state-action pairs to maximize the cumulative reward. A good starting point for learning about RL and DRL is the book “Reinforcement Learning: An Introduction” by Richard S. Sutton and Andrew G. Barto and a course by David Silver.
DRL with Quadcopter Environment
Let me now explain the core part of this project. Here, the agent is our deep neural network, which will be implemented on ultra96. The environment is a room of 10x10x5 meters having a quadcopter inside. The agent controls the quadcopter's thrust, roll, pitch, and yaw; hence, the action space is continuous. The agent's goal is to take the quadcopter to any given random setpoint in the room, e.g. [0,0,-2.5], while also balancing the pendulum (if attached). Similarly, the reward function is inversely proportional to the distance between the input setpoint and the quadcopter’s current position. During training, the agent will interact with the environment, perform random actions, and observe the next states and rewards. The environment state consists of the state of the quadcopter and the distance between the input setpoint and the quadcopter’s current position in the room. It will try to perform those actions more that take the quadcopter closer to the input setpoint, i.e., which gives greater rewards. At the end of the training, a well-trained agent can adjust the quadcopter's thrust, roll, pitch, and yaw to take it to the given setpoint, starting from any random position in the room and holding its position while hovering.
Training the agent with feedback
A natural question in the DRL framework comes into mind, i.e., why use feedback when the agent can figure everything out on its own over time? Before answering this question, let us consider a few points. As mentioned earlier, the DRL is more data-hungry than supervised learning and takes a long time to train. It has to go through thousands or millions of trials to determine the optimal state-action pairs. In literature, various works are available, e.g., [6, 7], where the agent is provided with some initial feedback to help it figure out what to do. The input can be removed after a few training steps, and the agent can find the optimal actions much faster.
Lastly, I have a weak i3 CPU machine, which can take many weeks on my poor machine ☹. So, I must figure out the fastest way to train a DRL agent. Hence, if assistive feedback is available and can significantly speed up the training process, why not simply use it to save time and resources? This feedback comes from the position controller of the quadcopter and is added as a weighted term in the optimization step. After adding feedback, I could train the agent within a few hours. Therefore, it allowed me to conduct a lot of experiments (and it took me more than a month) to figure out the perfect settings (architecture, quantization, hyperparameters, training methods, i.e., proximal policy optimization (PPO) [8], deep deterministic policy gradients (DDPG) [9, 10], TD3 [11], prioritized experience replay [12], etc.) to be used for training as well as for the deployment on Ultra96. Hurrayyyy!!! :D.
Furthermore, I believe that with a strong GPU machine, the same agent can be trained with thousands or millions of iterations to achieve the same results. Anyways, it is always a good idea to save time when dealing with the training of neural networks 😉.
Note: Other than the quadcopter environment (which has feedback), I successfully tested the agent without feedback training on a few OpenAI’s gym environments as well to make sure everything is working as expected. The training scripts are also written to support this, which you can try if you are interested, but you may have to play with a few hyperparameters for the different gym environments. One such example for OpenAI gym’s Pendulum-v0 is provided.Deployment using DPU-PYNQ on Ultra96
Finally, we are at the deployment stage. It’s been a long journey, but worth it. First, I should mention all the hardware components required. Second, for software requirements, pynq Linux v2.5 is used on the ultra96 along with the DPU-PYNQ. It provides python APIs to interact with the DPU implemented on the PL of the ultra96. To summarize the ultra96 flow (look at the Block Diagram provided in the Schematics section), the camera captures the hand gesture used to change the setpoint. This setpoint, along with the quadcopter state (from the simulator), is then given to the DPU via pynq API. The output is the corresponding actions (thrust, roll, pitch, and yaw) for that state which is then fed to the simulator, which is running on the processing systems (PS) of ultra96 and transmitted via crazy radio PA to the Crazyflie (if connected). The unity simulator is also connected via the ZMQ socket to show what the simulator is doing. One crucial point to be noted is that we do not have state feedback from the Crazyflie, but we are using an estimate of the state from the simulator. To get the complete state feedback from Crazyflie, Bitcraze loco positioning system is required (which costs about $1800). With the loco positioning system and accurate feedback from Crazyflie, we can have much better and more accurate results on Crazyflie. But even without the feedback from the actual Crazyflie, the results are still visible and can be observed clearly. Links and details of the video demos are given in the next section. Getting everything up and running on Ultra96 took me almost 4-5 days.
Demo VideosSimulation:
Crazyflie:
Pole Balancing in simulation (Inverted Pendulum Attached):
Pole Balancing on a real Quadcopter (More details are given here):
Instructions to Reproduce the Results
Step-by-step instructions to reproduce these results are given in the README.md of the project’s GitHub repository.
Impact of this ProjectQuadcopters
As mentioned previously, when considering social impact, quadcopters can be pretty helpful in disaster relief efforts, e.g., humanitarian aid [13]. They help organizations identify areas of need and deliver first aid kits and other relevant packages. When discussing environmental research and development, drones are helping animal scientists and researchers [13]. They can give views and access to places they never had before. In defense, they are used to fight illegal logging, especially in the middle of the forest [13]. They are helping in refugee search and rescue missions [13]. Drones are also used in telecommunication to provide radio connections to areas with little coverage [13]. They are being used commercially in the photography and cinematography industry. Lastly, they are a very attractive platform for control systems, robotics, deep learning, and scientific research because of their simple mechanical design. They are used for DRL, developing and testing autonomous flight systems, and further pushing the limits of state-of-the-art research in those areas.
Autonomous Flight Systems
Quadcopters are a great platform to develop and test autonomous flight systems, which are vital in making our lives simple and easy. Autonomous systems, in general, constitute many industries and a crucial part of many industrial process control. They are particularly attractive in the automotive sector and flight systems. This is another beautiful key factor of this project, i.e., it combines autonomous systems with IoT and shows how Xilinx’s device can be utilized in this scenario. It is impressive that a small device can control a flying vehicle using state-of-the-art algorithms. There is room for much improvement in this project when talking about autonomous flight, which requires an investment of money.
Deep Reinforcement Learning
Using DRL for quadcopters and autonomous systems is getting attention, and researchers have recently started looking into it, as given in the references. As DNNs are showing impressive performance in many research areas, I believe that using them to develop fully autonomous flight systems can be a big step in research and another massive success for DNNs. Based on my limited experience with supervised learning and DRL, I think DRL is a much more challenging problem, and it still requires a massive amount of research to be conducted.
Complete Bill of MaterialsThe repository has two mostly identical branches. “main” branch has the code for simulation and training scripts.
The “flying_pend” branch has an inverted pendulum model added to the quad and unity simulator. It trains to reach a given point, starting from any random point while balancing the pendulum.
I will explain code organization below. The “README.md” files contain important information. So please make sure to go through all of that to understand the structure more accurately. Also, the code itself is self-explanatory and well-commented.
env_window/
The source code of env_window is given in the file “env_window_source_code.tar.gz” you can extract it if you want to look inside it or play around with it. After extraction, the “env_window” folder contains the complete code for the unity simulator. It is named an environment window because it provides an interface to look into the environment and what the agent is doing. It was developed using unity 3D personal edition 2020.1.4f1.
env_ip.txt
The file “env_ip.txt” contains the IP address to connect to. If you want to connect to localhost for training and evaluation, set it to 127.0.0.1:4567. But when running a demo on ultra96, you have to change it to 192.168.3.1:4567 or whatever the IP over the network ultra96 has.
Assets/
The C# scripts for handling the network communication use the ZMQ socket and are available under the “Assets/” folder, and the code also provides explanatory comments. Similarly, the quadcopter’s body is available under “Assets/ProfessionalAssets/.”
build/
The final compiled simulator is located at “build/unity_sim.x86_64”.
quad96/
This folder contains all the code besides the unity simulator, i.e., the actual python simulator, agent’s training scripts, ultra96, camera, keyboard, Crazyflie nano copter interfaces, etc. All commands related to training on PC or inference in DPU on Ultra96 must be run from this folder. The “quad_run.sh” file contains all the commands to reproduce the demo. The argument is commented out in the file“—render_window” by default. You can uncomment (and launch the unity simulator) to view the environment in the unity simulator during training and evaluation. Another important point is that the output DPU model is generated under the “ultra96/” folder, and a symbolic link is created under this directory. The “test_quad.py” has to be loaded as a python module from here. This is due to a bug in the DPU-PYNQ’s relative directory handling. Lastly, the“input_func.py” is used by the Vitis-AI to calibrate the quantized graph.
camera/
This folder contains all the files related to the camera controller and interface. The “thresholder.py” file is used to find the HSV values for the object of interest and is used by the camera controllers in “camera.py.”
crazyflie/
This folder contains all the files related to interfacing the Crazyflie 2.1 nano copter to the simulator and attaching the keyboard controller to control the Crazyflie. It also has an additional Bluetooth driver, which can be used for testing the Crazyflie, but it is not suitable for use with the simulator. CrazyRadio PA is the recommended option.
deploy/
The trainer uses this folder to export the graph and Vitis AI to generate the outputs, e.g., frozen and quantized graph. The host folder contains scripts to install the Ultra96 part in the Vitis-AI flow.
simulator/
This is the main folder containing the actual python simulator. All the parameters related to the Crazyflie and the PID values are given in the “params.py.” The "controllers.py” file contains the PID controller, attitude controller for the quad simulator, and position controller. The “network.py” handles the communication between the python simulator and unity env_window via the ZMQ socket. The “plot.py” file provides a function to plot the state with respect to time for PID tuning and also provides an option for plotting the quad in pure matplotlib’s 3D plot if the unity simulator is not running, but it is pretty slow. The “keyboard.py” contains the function to interface with the keyboard for adding disturbance or position control. The “flying_pend” branch also has an “inv_pend.py” file which contains the model of the inverted pendulum. Finally, “drone_class.py” is the main file combining all the required components and forming a drone/quad simulator. It provides a function to update the state, reset, execute position and/or attitude commands, and handles all the connected interfaces, e.g., keyboard, camera, and network. “utils.py” provides some helpful utility functions.
training/
This folder contains all the necessary files for training. It includes the definitions for TD3PG actor-critic architecture, Rank based on prioritized experience replay, and an environment interfacing the drone with the agent and providing useful functions like a reward, terminate, and assistant. The intermediate models are saved under the “Models/” directory.
ultra96/
This folder contains the script for running the demo on ultra96, handling the communication with DPU on the PL, and the output .elf file from the Vitis-AI compiler.
[1] Mellinger, Daniel Warren, "Trajectory Generation and Control for Quadrotors" (2012). Publicly Accessible Penn Dissertations. 547.
[2] D. Mellinger and V. Kumar, "Minimum snap trajectory generation and control for quadrotors, " 2011 IEEE International Conference on Robotics and Automation, Shanghai, 2011, pp. 2520-2525, DOI: 10.1109/ICRA.2011.5980409.
[3] https://towardsdatascience.com/demystifying-drone-dynamics-ee98b1ba882f
[4] “System Identification of the Crazyflie 2.0 Nano Quadrocopter”. Available at: http://mikehamer.info/assets/papers/Crazyflie%20Modelling.pdf
[5] https://victorzhou.com/series/neural-networks-from-scratch/
[6] Scholten, Jan & Wout, Daan & Celemin, Carlos & Kober, Jens. (2019). Deep Reinforcement Learning with Feedback-based Exploration.
[7] Christiano, Paul & Leike, Jan & Brown, Tom & Martic, Miljan & Legg, Shane & Amodei, Dario. (2017). Deep reinforcement learning from human preferences.
[8] Schulman, John & Wolski, Filip & Dhariwal, Prafulla & Radford, Alec & Klimov, Oleg. (2017). Proximal Policy Optimization Algorithms.
[9] Silver, David, Lever, Guy, Heess, Nicolas, Degris, Thomas, Wierstra, Daan, and Riedmiller, Martin. Deterministic policy gradient algorithms. In ICML, 2014.
[10] Lillicrap, Timothy & Hunt, Jonathan & Pritzel, Alexander & Heess, Nicolas & Erez, Tom & Tassa, Yuval & Silver, David & Wierstra, Daan. (2015). Continuous control with deep reinforcement learning. CoRR.
[11] Fujimoto, Scott & Hoof, Herke & Meger, Dave. (2018). Addressing Function Approximation Error in Actor-Critic Methods.
[12] Schaul, Tom & Quan, John & Antonoglou, Ioannis & Silver, David. (2016). Prioritized Experience Replay.
[13] https://mashable.com/2017/04/23/drones-social-good-humanitarian-aid/?europe=true
For Inverted Pendulum
[14] M. Hehn and R. D'Andrea, "A flying inverted pendulum, " 2011 IEEE International Conference on Robotics and Automation, Shanghai, 2011, pp. 763-770, DOI: 10.1109/ICRA.2011.5980244.
[15] Figueroa, Rafael & Faust, Aleksandra & Cruz, Patricio & Tapia, Lydia & Fierro, Rafael. (2014). Reinforcement Learning for Balancing a Flying Inverted Pendulum. Proceedings of the World Congress on Intelligent Control and Automation (WCICA). 2015. 10.1109/WCICA.2014.7052991.
[16] Zhang, Chao & Hu, Huosheng & Gu, Dongbing & Jing, Wang. (2016). Cascaded control for balancing an inverted pendulum on a flying quadrotor. Robotica. -1. 1-17. 10.1017/S0263574716000035.







{kind=link}
Comments