

Hardware components | ||||||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
 |
| |||||
| ||||||
To fully comprehend the impact this project brings to the FPGA industry, it requires knowledge of multiple areas of computer science: Deep Neural Networks, Evolutionary computation, Supervised/Reinforcement Learning, OpenCL and High-level deployment FPGA.
It might seem like a daunting task; however, it is possible to run the examples below without a full understanding of the inner details, even with a surprise a the end of this article.
Remember, it is not just about the destination, but about enjoying the journey to discovery.
BackgroundTraining of Deep Neural Network (DNN) has taken multiple approaches to make them faster, more accurate or power efficient; one technique used to simplify models is the utilization of quantized values for weights, activations, inputs or outputs.
This project introduces a brand new approach to train Binary Neural Network using neuroevolution to perform the space search, with the addition of FPGA acceleration as a viable alternative to CPU/GPU training, previously barely explored.
Source: Welcoming the Era of Deep Neuroevolution
Traditional DNN (ex. AlexNet, Resnet, GoogLeNet) employs the principles of an algorithm named "Backpropagation": it operates derivatives to calculate a set of floating-point values that produces the least error, trained in two stages: forward and backward steps. When training finishes, a single fixed topology DNN is employed to resolve supervised learning problems.
Source: Introducing GPipe
However, as those models grow, also the memory and computation requirements. A partial solution to reduce their impact is the "Quantization" of continuous values; to deploy trained models onto FPGAs; Xilinx Vitis AI offers a tool to reduce the precision and execute inference only. However, to the author's knowledge, FPGAs are not widely used for training in comparison to CPUs or GPUs.
The last quantization frontier is a binary state (0 or 1), creating what is known as Binary Neural Network (BNN). By taking weights and biases values to the lowest denominator, BNN reduce memory footprint, it uses mainly bitwise operations and promotes model compression, further explored by Review of Binarized Neural Networks. On the other hand, BNN lack behind its continuous counterparts in accuracy when tested on Image Classification tests.
Most research around BNN has focused on the translation of backpropagation, an algorithm designed for floating-point values, to engage with discrete sequences; such transformation exacerbates instabilities at training time.
ContributionTo gain all the BNN features, extend its capabilities to Reinforcement Learning (RL) and avoid drawbacks from a quantized backpropagation, this project takes a groundbreaking approach:
- Weights and activations use bitsets.
- Only logic operations (AND, XOR, OR, XNOR) are applied, nullifying the need for Arithmetic Logic Unit (ALU).
- Neuroevolution is employed to drive the space search, replacing a two-stage backpropagation.
- It generate a dynamic network topology to adapt and optimize for the problem at hand.
- Training and inference can be performed by reconfigurable devices, like the Alveo U50.
These fundamental changes simplify hardware requirements to execute the algorithm. Given FPGA's reconfigurability, this algorithm acquiesces a pipelined architecture that effectively adapts to any RL problem to be engaged. At the same time, BNN models remain power/memory efficient.
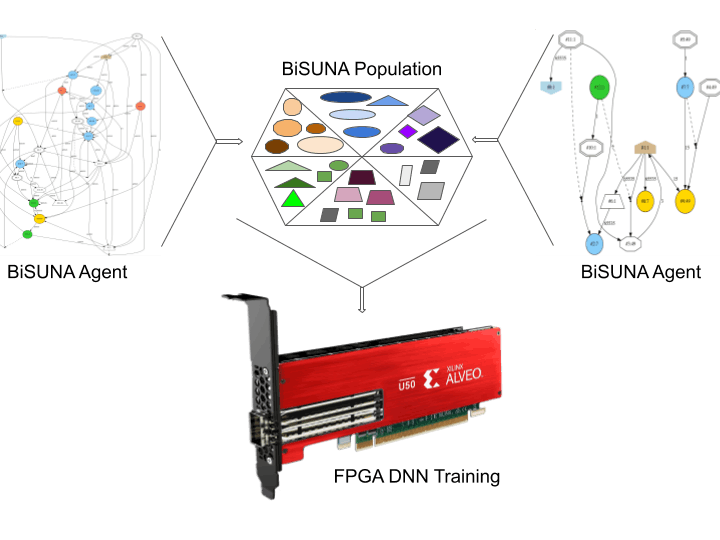
The name of this algorithm is Binary Spectrum-diverse Unified Neural Architecture (BiSUNA).
Thanks to the BiSUNA framework, it is possible to solve RL challenges by creating different BNN topologies with multiple outcomes. The fundamental milestone is how FPGAs are used to train neuroevolved BNN competitively in terms of energy dissipation and time when measured against a single thread CPU execution.
With the battery of tests performed, the FPGA 8 Compute Unit (CU) bitstream was executed with comparable time to a single thread CPU runtime, despite data movement over a PCI-Express channel.
Binary Spectrum-diverse Unified Neural ArchitectureThis paper demonstrated how the reduction of floating-point connections to 8 bits decreases the memory needed to transfer neural models.
BiSUNA moves that idea further by taking advantage of diverse weight sizes along an evolving topology that adapts to RL problems, with the addition of having binary sets instead of floating-point connections and neurons.
BiSUNA was introduced in this paper, a state-of-the-art TWEANN algorithm with distinctive characteristics that strengthen its suitability for discontinuous-nonlinear systems. Those attributes are: Inputs and Outputs are bitsets; all neuron operations are logic functions; it implements population metaheuristics to find solutions; lastly, it trains without backpropagation.
A second publication analyzed BiSUNA's training on programmable hardware, this enabled acceleration on entry-level FPGA.
This project takes that idea further by capitalizing on the fast HBM2 memory, massive LUT resources and simple software environment provided by the Xilinx Alveo U50.
FPGA trainingLimited research has taken place to take advantage of FPGA flexibility at the time of training deep neural networks, a place where GPGPU dominates the market. On the other hand, multiple examples have demonstrated FPGA's advantage when performing inference of DNN models.
As an alternative optimization technique, evolutionary algorithms operate similar bio-inspired operations continuously applied to multiple individuals at the same time, called "agents"; querying each takes most of the computation time with particular features:
- Agents' calculations are embarrassingly parallelizable for well-designed applications.
- Sharing updates and communication has low overhead, with examples of linear growth as more processors become available.
- Stored data required for computations can be efficiently cached, given the lack of backpropagation.
- Evolution has been proven by nature to perform an open exploratory behavior of complex environments.
Therefore, by iteratively querying multiple agents in parallel using dedicated CUs, it is possible to achieve more performance at scale. The BiSUNA framework employs neuroevolution with only binary operations/values in the creation of non-sequential neural networks in charge of solving RL problems.
All these characteristics fit FPGA's flexibility: unconventional data paths are comfortably implemented, specifically with hardware architectures optimized for logic functions and popcount operations. FPGAs typically consume less power compared to CPUs and GPUs.
Process Offloading, v0With the background stablished, the next step is to understand which functions the FPGA can accelerate; inspired by this Xilinx tutorial, that process will be covered below.
Regarding development environment, given OpenCL 1.2 support offered by the Xilinx U50 board, it was possible to bring C++ code already tested in BiSUNA, then transform it to C kernels compiled using the Xilinx Vitis Unified Software platform.
What is even more encouraging, this project could be extended to virtual machines on the cloud, like Nimbix or AWS F1 instances. The following hardware and software stack was used:
Hardware:
- Xilinx Alveo U50
- Intel i5 2.5GHz 2400S
- 16 GB RAM
- 1TB storage
- Motherboard with PCI-Express 3.0
- System Power Supply at least 225W
Software
Taking the code from the BiSUNA repository, fulfilling all the necessary dependencies listed above, it is possible to compile a Linux binary using the GCC flag gprof as follows:
git clone https://github.com/rval735/bisunaU50
cd bisunaU50
make PROFILE=-pg bisuna
./bisuna resources/BiSUNAConf.ini
gprof bisunaThe snipped above will clone the repository, compile the binary using a GCC profiling flag and run "bisuna" with the default configuration. The last line runs "gprof" to retrieve profiling information, data written to file 'gmon.out' in the same folder. The output provides the list of functions that take the most time to execute:
~/bisunaopencl $ gprof bisuna | head -n 30
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls ms/call ms/call name
60.13 1.40 1.40 10956329 0.00 0.00 NNSFunction::execute(unsigned short const&, NNetworkState*, bool const&)
7.33 1.57 0.17 836438 0.00 0.00 NNSFunction::processRemainingNeurons(NNetworkState*)
5.17 1.82 0.12 871540 0.00 0.00 NNSFunction::processOutputNeurons(NNetworkState*)
3.88 1.91 0.09 887024 0.00 0.00 NNSFunction::processControlNeurons(NNetworkState*)
3.45 1.99 0.08 999288 0.00 0.00 NNSFunction::process(std::vector<unsigned short, std::allocator<unsigned short> > const&, NNetworkState*)
3.02 2.06 0.07 873969 0.00 0.00 NNSFunction::processCPrimerNeurons(NNetworkState*)
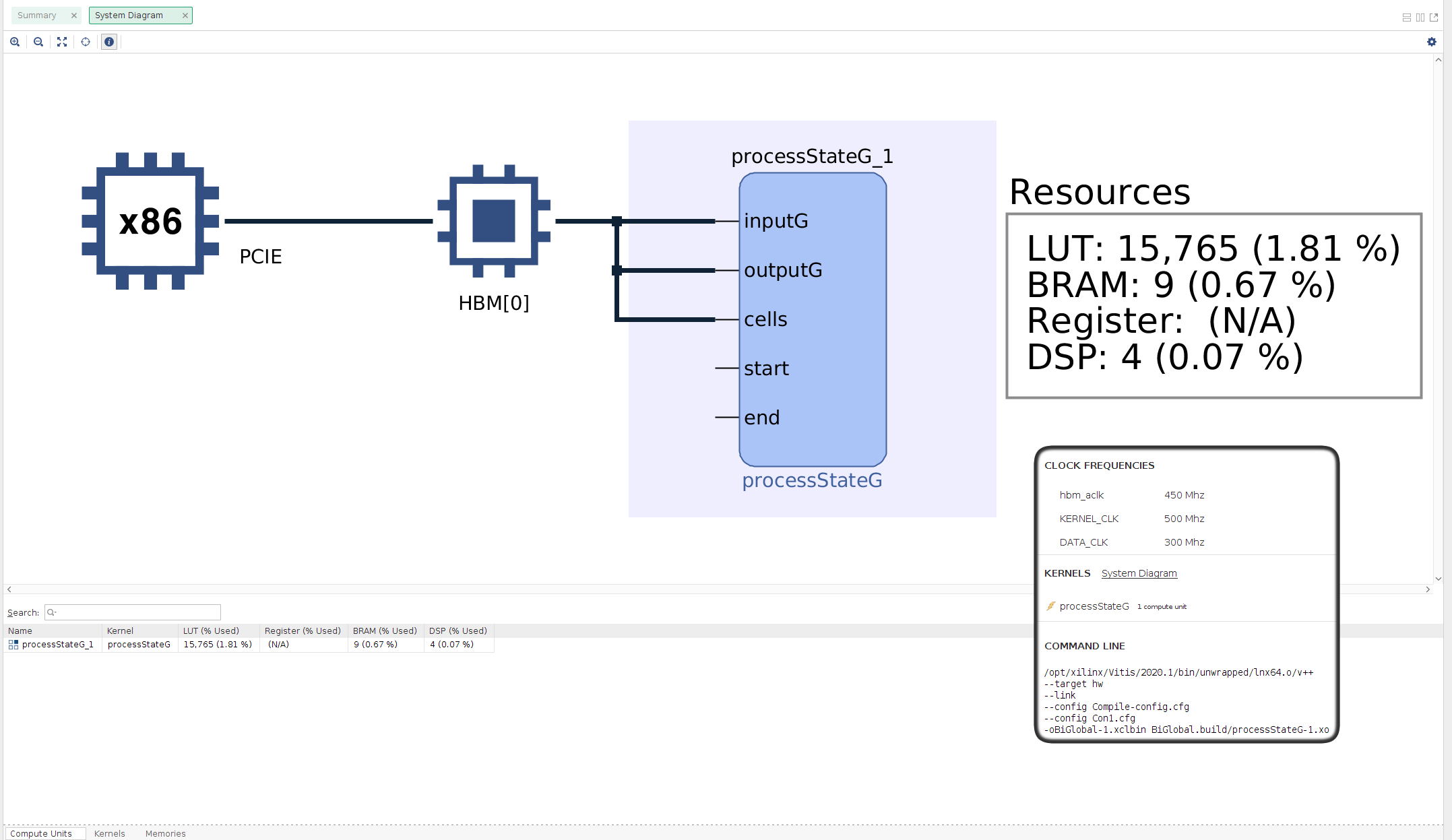
2.59 2.12 0.06 1465608 0.00 0.00 NNSFunction::runControlID(unsigned short, std::vector<NConnection, std::allocator<NConnection> > const&, std::vector<NNeuronState,This result bestows insight for the function to deploy to the Xilinx U50 board: "NNSFunction::process" takes the environment action and every agent state. OpenCL kernel will perform these steps on the FPGA.
The first step towards improvement is the establishment of a baseline, for which the repeated execution of the MountainCar environment takes place. Enhancements statistical significance is achieved at each stage by repeating five times the same binary and configuration.
One more feature this framework provides is the possibility to compile the executable with continuous neurons, also included in those benchmarks.
The results of executing BiSUNA on a single core with both neuron types (binary and continuous) is the following:
It takes 100 generations an average of 182 seconds to finish its execution with binary neurons, 260 with the continuous version.
Kernel Execution, v1Once the function to offload is identified, the next step is to create the OpenCL kernel and all initialization steps required to communicate with the accelerator. The author employed this book extensively to learn all about OpenCL runtime and how to deploy workloads in parallel.
The BiSUNA framework offers multiple files to abstract some OCL complexities, as well as simplify interactions between BiSUNA and OCL:
- src/OCL/OpenCLUtils.hpp: Platform, device and context initialization.
- src/OCL/OCLBridge.hpp: Collection of methods to transform from a traditional agent to one memory specialized for OCL.
- src/OCL/OCLContainer.hpp". Deals with memory and buffer transfers.
The translation of code from "NNetworkState.hpp" to "ProcessStateGlobal.cl" required multiple changes: agent organization, struct alignment and arrangement of distinctive memory layers (ex. global, local, private). Future work would focus on better memory management between these layers.
The Xilinx Vitis development environment helps to simplify the coding process with three testing stages:
- Software emulation: Initial phase of FPGA development that helps to clear any execution problem with the OpenCL runtime or memory transfers. Bitstream compilation is the fastest, that helps to resolve any kernel errors.
- Hardware emulation: This phase still runs on the CPU; it involves the target hardware closely for its compilation, taking special considerations to memory types (DDR, HBM) and FPGA resources. The Vitis Analyzer also produces hardware-specific improvements to the OpenCL kernel. The bitstream compilation takes longer than SW emulation, in the range of several minutes.
- Hardware: This stage creates the bitstream to reprogram onto the FPGA, which also requires the physical hardware board to execute. Compilation time ranges from 30 mins to several hours, depending on the kernel size.
This article displays only hardware results; nonetheless, the iterative process in the creation of the bitstream intensively leveraged SW & HW emulation phases as well.
For example, during SW emulation, it was noticed how to use enqueued memory buffers were a better option than simple read/write. During HW emulation, it was possible to identify the expected BiSUNA resource utilization. These are only two of the many improvements made before the third stage.
In order to compile a bitstream inside the BiSUNA project, it is as simple as open the "BiSUNA-U50.prj" in Vitis, then click build. Another option is to use "make" inside the root project folder:
$ make BiGlobal-1.xclbin
/opt/xilinx/Vitis/2020.1/bin/v++ --target hw --compile -I"BiSUNA-U50/src/OCL/Kernels" --config Compile-config.cfg --config Con1.cfg -o"BiGlobal.build/processStateG-1.xo" "BiSUNA-U50/src/OCL/Kernels/ProcessStateGlobal.cl"
Option Map File Used: '/opt/xilinx/Vitis/2020.1/data/vitis/vpp/optMap.xml'
****** v++ v2020.1.1 (64-bit)
**** SW Build 2960000 on Wed Aug 5 22:57:21 MDT 2020
** Copyright 1986-2020 Xilinx, Inc. All Rights Reserved.
INFO: [v++ 60-1306] Additional information associated with this v++ compile can be found at:
Reports: bisunaopencl/scripts/XilinxFPGA/BiGlobal.build/reports/processStateG
Log files: bisunaopencl/scripts/XilinxFPGA/BiGlobal.build/logs/processStateG
INFO: [v++ 60-1657] Initializing dispatch client.The result of this command is the file "BiGlobal-1.xclbin" bitstream, which is used by the BiSUNA OCL runtime to deploy its execution onto the Alveo U50 board. Here it is possible to observe how the transition from continuous to binary neurons reduces the circuit complexity from 36K to 15k, with even more gains on DSP usage, 110 vs 4.
To signal that the bitstream has changed, the ini configuration file "resources/FPGAConf.ini" needs an update as follows:
;-------------------------------------------------------
[OpenCL]
;-------------------------------------------------------
; Folder with all OCL kernel files
KernelFolder = ./ ; It need "/" at the end
; Kernel that will calculate a step, from input -> BNN -> output
KernelStateName = processStateG ;
; This tells the runtime that the kernel "State" uses local variables or all global
KernelStateUseLocalVars = false ;
; Define the accelerator type to use
DeviceType = FPGA
; OCL file output with the bitstream compiled code.
OCLFiles = BiGlobal-1.xclbin
; When enabled, it will set OCL profiling flags and show the time it takes to process/read output data.
OCLProfiling = false
; The default value of 0 will use the population size to distribute work among the maximum number of
; CU available in the device using NDRange. When the number is 1, it will execute a "single" kernel
; and more than 1 will require multiple CU distributed in the device (ex. FPGA)
ComputeUnits = 1With the ini file updated, the compiled BiSUNA file is ready for execution:
$ ./bisuna resources/FPGAConf.ini
Config file: resources/FPGAConf.ini
Using binary neurons
OpenCL mode, device: 8
Generation: 0
Best Fitness: -209.000000
----------------------------------------
Generation: 1
Best Fitness: -211.000000
----------------------------------------
...
----------------------------------------
Generation: 99
Best Fitness: -127.000000
----------------------------------------
TimeDiff: 567 secs
Last best score: -127.000000After five repetitions of the binary and continuous neurons, these are the result of executing the first version of the OpenCL kernel on the Alveo U50 card:
These results depict similar rewards to the single thread baseline, confirming that the OCL version behaves as expected to the solution of the MountainCar problem. On the other hand, the time it takes to execute increases substantially, which is easily visualized by the data movement overhead shown here:
Information exchange must be taken into account when performing acceleration tasks on devices with different memory layouts. At the time of BiSUNA's initialization, all agents are created in the CPU, then distributed to a single HBM2 memory bank on the FPGA.
Every interaction with the environment, new inputs/outputs are obtained, which must in synchronized with the Alveo U50. Once all agents have finished their turn, the CPU performs its filtering and evolution operations, then push those changes to the FPGA to have a new population ready for the next episode.
Where traditional RL algorithms (ex. Deep Q-Learning) use floating-point to solve problems, BiSUNA employs discrete values to find solutions to the same enigma with fewer resources with FPGA acceleration, something new to the industry.
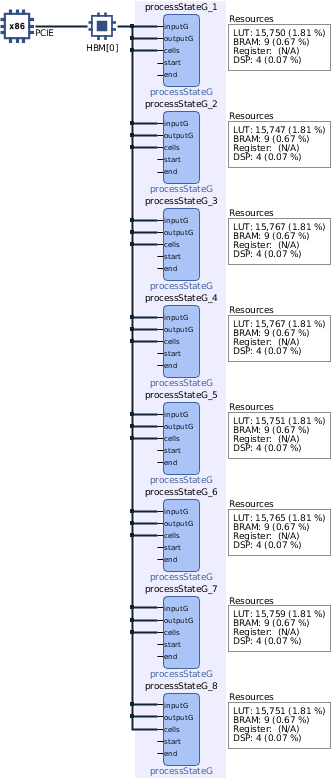
Kernel Execution, v2A similar characteristic between v0 and v1 is the lack of task parallelization, using only a single compute unit/thread, where only one agent interacts with the environment at the time. A result of embarrassingly parallelizable evolutionary procedures, any agent is independent of each other.
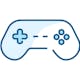
Given low FPGA utilization, it is possible to "hard-code" kernel copies inside the bitstream, that spreads the workload across multiple instances at the same time as it creates an equal number of environments. This adjustment shows improvements in the execution directly related to the number of CUs:
This version confirms how spreading the workload to multiple CU reduces time without substantial changes to the framework; the 8 CU v2 is competitive in time with v0, despite lower CU frequency (2.5GHz CPU, ~350MHz FPGA), memory transfers and PCI-E communication.
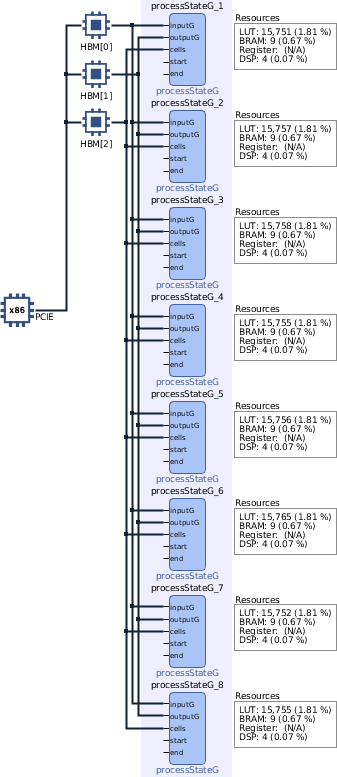
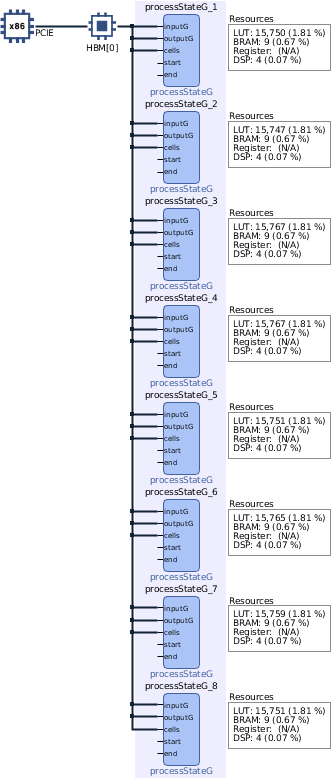
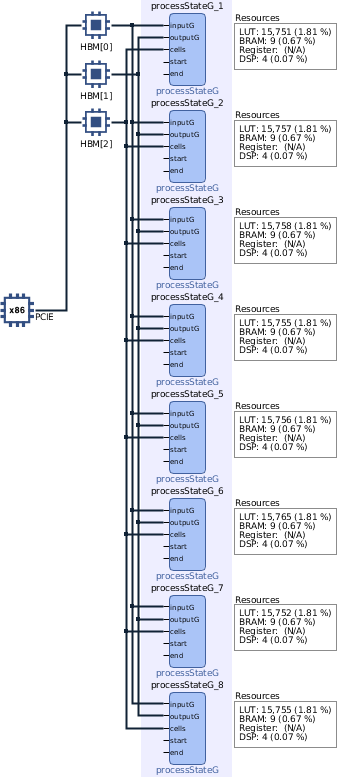
Kernel Execution, v3One last update to do without changes to the framework is the spread of memory buffers. The "process" kernel uses three global pointers: inputG, outputG and cells. "v1 & v2" shared the same HBM0, which does not take advantage of parallel data rates. v3 assigns these parameters to a particular memory bank to reduce delays as follows:
When memory banks have a direct assignment to each kernel variable, v3 reaches a 12% improvement between 8CU executions. Further action could modify every CU to have a direct connection to HBM2 sections, delegated as future work. An example of buffer metadata Is part of the Vitis Accel Examples repository.
The graph below demonstrates the gains between 1 vs 3 HBM banks assigned to each kernel:
Much more details and raw data obtained of these executions can be found in the repository folder "results".
Meanwhile, v3 sees a slight improvement in execution in comparison to v2, but drastic still to v1. Binary neurons remain the best alternative when compared in execution time and FPGA resources.
ApplicationsThe original BiSUNA repository contains tests of multiple OpenAI Gym RL environments: Mountain Car, Duplicated Input, Roulette, NChain, Copy and atari games. These represent just a small sample of BiSUNA's applications.
Thanks to this project, software developers have a new tool to easily employ FPGA bitstream to solve RL problems, an area where traditional DNN could hardly ever be deployed.
Those interested in neuroevolved BNN will be able to use this framework to train interactive models with dynamic conditions to learn from its rewards. These conditions are well known in robotics, gaming and self-driving cars, to name just a few. This project could be a competitive advantage to Xilinx in the race for AI acceleration in the cloud and at the edge.
As the last example of the BiSUNA algorithm applied to RL, below are the results of the OpenAI Atari environment "SpaceInvaders-ram-v0":
The FPGA community benefits directly from this work, given that it adds a new tool to train BNN using evolutionary principles, a innovative alternative that sidesteps completely gradient descent.
As a result of BiSUNA's proficiency to conditionally compile between discrete/floating-point systems, this work can be generalized to more environments, setting a precedence of BNN application to RL.
Experiments showed how binary neurons consume fewer FPGA resources in comparison with its continuous counterpart.
Today's gains over a CPU execution lies around 16%, future versions will optimize its architecture to exploit all the Alveo U50 board features to make it faster; another improvement will be to extend its hardware support to other devices (ex. Ultra96-V2).
Furthermore, the transition to binary neurons reduces the time necessary to query models, a direct consequence of the fewer LUT/DSP utilized. Those changes have a direct impact on power consumption as well as the ability of cost-optimized devices to execute BiSUNA (ex. Spartan 7).
As a benefit of how BiSUNA is architected, a simple compile flag switches from continuous to binary values. This project demonstrates a new research path where discrete values resolve RL problems previously not explored, given that traditional DNN (ex. QLearning) relies on floating components to reach a solution.
Simplifying hardware requirements to train BNN contributes towards the creation of more efficient networks and circuits, facilitating FPGA adaptive compute acceleration inference and training.
The near future will convey more intelligent computation to any device, expanding their capabilities, increasing technology expertise to the next level, the Adaptive Internet of Things.
In less than 10 years from today, IoT devices will triplicate their computational performance while reducing their energy consumption. BiSUNA is well suited to exploit those advantages by bringing intelligence: train in the cloud, then deploy to the edge.
Here is a video summary in a presentation format plus an runtime screencast running on the U50 FPGA:
This project scratches the surface of diverse implementations that take advantage of neuroevolution. The first step would take BiSUNA out of simulated tests and bring it into real-world problems, for examples:
- Space Exploration: Use BiSUNA powered devices to survey the surface of a meteorite in search of metalloid resources. Report back to earth only results.
- Deep-sea exploration: After a BiSUNA population is trained in a simulated 3D pressure environment using the Alveo U50, the best agent is selected to manipulate multiple servomotors of a marine robot.
- Nanosatellites: Thanks to FPGA reprogrammability, BiSUNA can be retrained to perform the best course of action for a low-orbit swarm of devices.
- Mars Surveillance: BiSUNA would test multiple search paths before execution without requiring large datacenters on the earth to process its information.
In other words, anywhere a changing environment is required by dynamic intelligence at the edge, BiSUNA can be a competitive alternative tool.
Today's dependence on cloud clusters to train large memory models with power-hungry compute units; will be complemented in the future by IoT devices capable of extensive data analysis at the edge, a place where FPGAs overcome competition.
Another avenue of exploration would be "plug-in agents": with simple interaction capabilities, sharing resources, genetic improvements and establishing a simple communication protocol. That would encourage cooperative behavior instead of survival competition, all with diverse models taking advantage of FPGAs reconfigurability.
A list of short term actions are the following:
- Develop a v4 where each kernel has a direct memory bank (like in the Schematics image).
- Perform randomization and evolution on the FPGA.
- Transform the sequential neuron calculation to a non-blocking network-style graph.
- Optimize the OCL Kernel to exploit local and private memory for each agent.
- DNN: Deep Neural Network
- BNN: Binary Neural Network
- FPGA: Field Programmable Gate Array
- CPU: Central Processing Unit
- GPU: Graphics Processing Unit
- GPGPU: General Purpose GPU
- RL: Reinforcement Learning
- ALU: Arithmetic Logic Unit
- DSP: Digital Signal Processor
- BiSUNA: Binary Spectrum-diverse Unified Neural Architecture
- HBM: High Bandwidth Memory
- LUT: Look-Up Table
- OCL: Open Compute Language (OpenCL)
- CU: Compute Unit
- IoT: Intelligent Internet of Things
- SW: Software
- HW: Hardware
- PCI Express: Peripheral Component Interconnect Express
rval735 is a Ph.D. student in his last year of studies developing BiSUNA, it has the objective to provide an alternative algorithm for training and deployment of binary and continuous neuroevolved networks.
His financial survival in the 2020 COVID year relies on donations to continue this framework development; visit the GitHub repository to check his crypto address if you enjoyed this post and would like help with anything that you can 😉.
Acknowledgements to the School of Computer Science at the University of Auckland and Dr. Bruce Sham for their ongoing support.
v1 - 1 CU Binary
v3 - 8 CU Binary, 3 HBM






{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments