

Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
| ||||||
In recent years so-called ASIC-resistant proof-of-work algorithms have become popular in the crypto-currency space in an effort to prevent increasing centralization of power to ASIC manufacturers. One such category of ASIC-resistant algorithms are the randomized Multi-Hash Chains (e.g. X16R), algorithms where multiple different hash functions are chained together and where the order of the chaining changes every block interval (i.e. on the order of minutes). This scheme introduces an inherent inefficiency to fixed-function ASICs, where a network is needed to shuttle the uncompleted hashes between cores and most importantly the need for over-provisioning of cores in order to handle random repetitions of hash functions required in the chain.
Note the repeated function calls in the chains.
FPGAs, being more suited to data-flow algorithms (e.g. hash functions) than GPUs, and more flexible than ASICs due to reconfigurability, makes them well positioned to tackle this problem.
We propose to utilize Dynamic Function Exchange (DFX) to time-slice the algorithm, and apply each hash function (or a sub-chain of functions provided they fit in the FPGA) to a batch of nonces sequentially. The on-board High Bandwidth Memory will be used to buffer the mid-states between reconfigurations. With this scheme, each individual hash function can be fully unrolled for maximum performance and avoids costly fully connected networks.
- Eight high performance (fully unrolled) hash functions written in Vitis HLS.
- A DFX architecture, Warphash, that is suitable for computing multi-hash PoW of any chain length.
In cryptocurrency proof-of-work mining, both performance and power efficiency has a direct impact on profitability. Therefore it is common to fully unroll the hash cores such that there are no feedback loops and achieve the maximum throughput per area. However, it is difficult to find open source hardware implementations of such hash cores that are suitable for proof-of-work.
As a part of this submission we are open sourcing the following hash cores:
- Blake512
- Bmw512
- Groestl512
- Jh512
- Keccak512
- Skein512
- Luffa512
- Cubehash512
All hash cores provided are written in Vitis HLS and are fully unrolled (i.e. capable of producing one output every clock cycle). The clock frequency we will be using for this example will be 450MHz. However, these cores can be resynthesized and clocked significantly higher, up to >700MHz without any significant increase in area.
Each hash function can be synthesized for a 64-byte input width or 80-byte input width. (In this project submission, for simplicity we assume all hash functions are of 64-byte type. However in most real PoW, the initial call will have a 80-byte input, which is the block header)
The source code can be found here:
https://github.com/Quarky93/warphash-hackster/tree/master/hash_cores
In the image below, we can see that the LUT utilization varies from ~51K to 322K. However, each comfortably fits within one SLR (~440K LUTs) on the U55N chip.
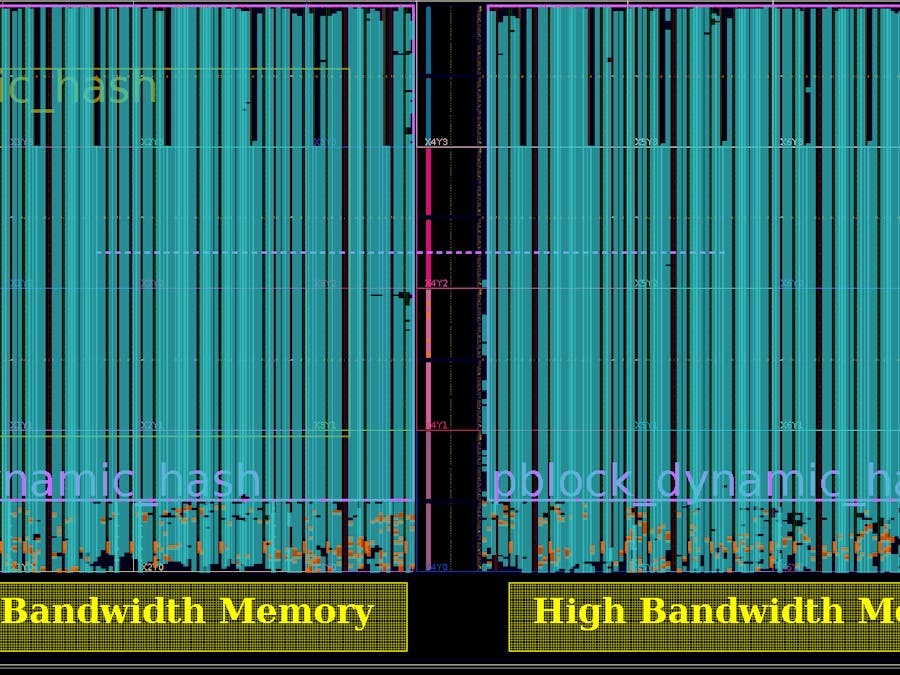
The Warphash architecture consists of two distinct regions: the static shell and the dynamic hash region. The static shell remains in place throughout the operation of the system and allows for communication with the host PC and controls the ingress and egress of mid-states from the HBM buffer. The dynamic hash region takes up most of the SLR (~350K LUTs) and is where we swap hash functions in and out.
Static Shell
The static shell consists of these primary components: PCIE DMA subsystem (XDMA), the Card Management System (CMS), the AXI High Bandwidth ICAP (HBICAP) and the Hash Controller.
The XDMA allows the host PC to read and write to the rest of the components in the system. It is configured for PCIE 4.0 x4, which allows for more than enough bandwidth to saturate the HBICAP.
The CMS allows the host to monitor the status of the FPGA, including temperature and power.
The HBICAP is a wrapper around the Internal Configuration Access Port (ICAP), by writing to which with a partial bitstream reconfigures the FPGA (the dynamic hash core in this case). In Xilinx Virtex Ultrascale+ FPGAs, the maximum bandwidth for the ICAP is 763MB/s (which is saturated easily by the XDMA).
The Hash Controller is a custom core written in Vitis HLS and has the following functions:
- On the initial function call in the chain (the head), it increments the nonce field in the block header and feeds it into the dynamic hash core.
- On subsequent calls (the tail), it takes the mid-states (i.e. the output of a hash function but not from the last) out from the HBM and feds it into the dynamic hash core.
- Except for the last function call, it stores the mid-states coming out of the dynamic hash core back into the HBM buffer.
- On the last function call, it takes the final hashes and filters them for hashes which meets the target and records the corresponding nonces into a FIFO for collection by the host.
The source code for the hash controller can be found here:
https://github.com/Quarky93/warphash-hackster/tree/master/hash_controller
Deep Dive
With the overview out of the way, let's focus the on journey that the mid-states take from HBM to the dynamic hash core and back.
We process batches of 67,108,864 (4GB worth) nonces/mid-states at a time. The HBM memory is split into two 4GB buffers (coinciding with the left and right stack). While the right stack is being drained of old mid-states, the left stack is being filled with new mid-states.
We use two dedicated write ports and two dedicated read ports. The AXI3 HBM ports 04, 06, 20 and 22 are used in such a way as to avoid contention in the built-in HBM AXI switch (for info on the switch see https://docs.xilinx.com/r/en-US/pg276-axi-hbm/Overview ). The memory is further subdivided such that each pair of read and write ports (rd_0/wr_0 and rd_1/wr_1) are responsible for only 2GB of memory in each buffer, which further eliminates contention.
Due to HBM AXI3 ports being 256-bit, it takes two cycles for a 64-byte mid-state to be loaded. Therefore two ports work in parallel in order to feed the dynamic hash core. Each 512-bit midstate is also tagged with 0 or 1, indicating the port it must return to (i.e. midstate loaded from rd_0 must return to wr_0). This is done such that the midstates are always processed in order. This allows us to use the memory index to indicate the nonce (nonce offset from starting nonce), thus we do not need to store the nonce itself.
Note the FIFOs after the demultiplexer. These are needed due to the nature of HBM being DRAM. DRAM must refresh every so often in order preserve memory contents. However, when this occurs, no reads or writes can occur. The refresh occurs independently in banks, therefore, when the store units are stalled waiting for refresh, the load units may still be running. The FIFOs provide a cushion such that a stalled store unit does not immediately drop data. Additionally, if the a FIFO becomes almost full, it will signal the load units to pause.
Dynamic Hash Core
We use the Block Design Container DFX feature of Vivado 2021.2 to implement the dynamic hash core. The Dynamic Hash Core itself is a reconfigurable partition which can be reconfigured with eight reconfigurable modules which are the eight hash functions.
Each block design is identical except for the hash core itself.
Note the AXI4-Stream Register Slices on both the ingress and egress ports. These configured with the auto-pipeline setting in order to ease meeting timing. Auto-pipeline allows Vivado to insert additional pipeline stages at the implementation stage. This is useful as our eight hash functions has differing latency (e.g. 55 cycles for Groestl, while blake takes 145 cycles).
Also note that the hash cores do not have any provision for back pressure (i.e. no ready signal) or reset. This is done in order to keep the hash cores as light weight as possible. All registers within the reconfigurable partition are reset (reset_after_reconfig) at the end of reconfiguration anyway. However, due to the lack of ability to handle backpressure, FIFOs are used in the static region to prevent data (mid-states) from being dropped (recall previous section).
The dynamic hash region is assigned to a pblock which spans most of the SLR, leaving room on the right and bottom for the static shell. Care must also be taken to exclude the the IO buffers (in this case found in the center spine of the SLR) used to bring in the system clock, UART and GPIO, as those belongs to the shell.
After implementation, Vivado shall generate the eight partial bitstreams we need to reconfigure the dynamic hash region. The partial bistreams are around 23MB each. When we consider the ICAP bandwidth, a hash function can on average be reconfigured in 30ms.
On the host side, we use the Xilinx provided XDMA drivers to communicate with the FPGA card. The linux driver exposes character devices: /dev/xdma0_user (access to axi-lite bus), /dev/xdma0_h2c and /dev/xdma0_c2h (DMA transfer to AXI4). The only component mapped to the DMA channels in this case is the HBICAP, all other components are accessed through axi-lite.
We use python to access these character devices in order to read and write to components in the FPGA. From the host, we can access the hash controller to set the block header (PoW input), the target (how difficult the PoW is) and the starting nonce. In order to reconfigure the dynamic hash region, we simply write the required partial bitstream to the HBICAP over XDMA. Once the last partial bitstream has been reconfigured, the host polls the hash controller for golden nonces and then starts the loop again.
We found that the time taken to hash 67,108,864 (4GB) mid-states was 160ms, which is 93% of the theoretical throughput if all four HBM ports used were running at maximum efficiency. We think this can be attributed to DRAM refreshes. Taking into account the reconfiguration time and the DRAM overhead, there is a 27.4% total overhead. We recorded an average power consumption of only 24W during operation.
A full loop of an hypothetical X8R (a chain of eight functions pulled from a pool of eight hash functions) algorithm will take approximately 1.52s to complete 67 million hashes. This translates to 44MH/s performance and 1.83MH/joule.
If we extrapolate this example to X16R (i.e. a chain of sixteen from a pool of sixteen), while assuming that the additional hash functions are similar in size to what we have shown here, then we will complete a full batch in 3.04s, which translates to 22MH/s and 0.91MH/joule.
When comparing to GPUs (data from nicehash.com):
- 1080 Ti (TSMC 16nm): 19.33MH/s @ 170W (0.113MH/joule)
- 2070 Super (TSMC 12nm): 34MH/s @ 110W (0.309MH/joule)
- 3090 (Samsung 8nm): 64MH/s @ 330W (0.194MH/joule)
And an ASIC:
- OW1 (unknown technology node): 250MH/s @ 1500W (0.167MH/joule)
We can see that that our Xilinx U55N FPGA (TSMC 16nm) achieves 8x better power efficiency relative to a GPU of the same technology node and 2.9x better in power efficiency when compared to a GPU on a newer node. In terms of power efficiency our approach also compares favorably with an ASIC.
ConclusionWe leveraged a unique feature of FPGAs, dynamic reconfiguration, in order to solve a problem which would be too inefficient when implemented as a traditional fixed design. By time slicing the algorithm, we can tackle hash chains of any length. This approach does not only work for proof-of-work algorithms. Any latency-insensitive, dataflow oriented problem can be mapped this way.
Potential Warphash ExtensionsOur relatively low raw performance (22MH/s) is due to the fact we are only using one SLR. By extending the design to two SLRs, we can effectively double the performance. This can be done by creating two dynamic hash cores (two reconfigurable regions), one in each SLR. By making sure that each reconfigurable region does not cross into the other SLR, we can use two ICAPs independently to configure both SLRs in parallel at the maximum speed.
Another approach is to split the multi-hash chain into subchains, i.e. more than one function per partial bitstream. However, this would lead to an explosion in the number of partial bitstreams which must be compiled (at least 136 combinations for subchains of two functions).
It would be interesting to see the improvement on Versal devices, as it has 8x faster reconfiguration speed. The built-in NoC may also simplify floorplanning of reconfigurable regions.

Comments