

Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
On behalf of the MIT Hanlab, in this project we demonstrate the utility & performance of the Temporal-Shift-Module (https://hanlab.mit.edu/projects/tsm/) for video understanding problems on FPGA.
TSM is a network structure that enables efficient learning of temporal relationships by 2D CNNs. At a high level this is done by performing inference on a single frame at a time (online TSM) or multiple frames (offline TSM) and shifting activations between these tensors as they flow through the network. This is done by inserting a shift operation into the bottleneck layers of a 2D backbone (in this case mobilenetv2 and resnet50). This shift operation then shuffles a portion of the input channels between temporally adjacent frames.
Deploying such a model to FPGA can bring a number of benefits. Firstly, as TSM already brings large benefits in power efficiency, deployment to FPGA can further this. Additionally, although not done in this project, access to programmable hardware opens the door for hardware offloading of operations in a similar manner to how we offload shift to software.
In this project, we deploy a model to both ZCU104 and Ultra96V2:
(1) Online TSM trained on the Jester dataset
Structure of TSM Network
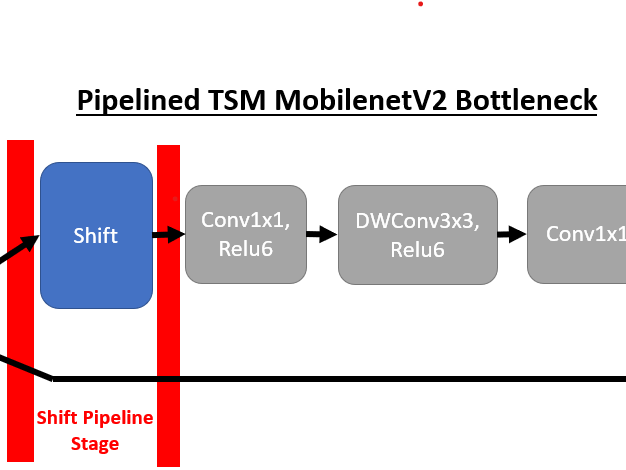
We will first review the underlying structure of these TSM networks and the translation to a DPU-compatible implementation. The core structure of a TSM network is the temporal-shift-module inserted within the bottleneck layers of the backbone model to enable temporal modelling. For example, a TSM MobilenetV2 bottleneck layer has the following structure once the shift operation is inserted:
In the demonstrated online-TSM network, if we are at temporal step T we are also at inference round T. The shift module shifts the first 1/8 of the incoming channels to a shift buffer containing the same channels from the previous inference round (T – 1). The contents from round (T – 1) are then shifted into the current tensor for round T.
Offline ShiftFor offline TSM, as used in the resnet50 kinetics demo (currently disabled), the shift buffer is bypassed. Instead, we process N adjacent temporal steps as tensors within a batch. Instead of storing the channels from step (T – 1) in a buffer, the channels can be directly shifted within a batch. Additionally, this enables access to future rounds within a batch (i.e. inference step T can exist in the same batch as step T + 1). With such access offline shift also shifts channels from step T + 1 into the tensor for step T.
DPU Model OptimizationTwo large changes needed to be made to the original TSM models for deployment to DPU. The first was separation of the shift module from the network as we are unable to implement the shift operation using supported tensorflow operations. To accomplish this, we pipeline the model at every occurrence of a shift module.
By placing the shift module in its own pipeline stage we gain the flexibility to offload the shift operation from the DPU kernels. Below we can see the first 4 pipeline stages of MobilenetV2 online TSM (from right to left). If compare the two bottleneck layer implementations, and remove shift ops, this corresponds to the following transformation where the bottleneck layers contain 1output before the shift module and 2 inputs after the shift module. One input contains the post-shift tensor from the top branch and the other the unshifted residual tensor in the bottom branch.
Here we visualize TSM with a mobilenetV2 backbone for simplicity, however the same approach is used with the resnet-50 backbone.
To implement this pipelined structure we have a flag within our Tensorflow models to indicate if we want to generate a split model excluding shift operations (used for deployment for DPU) or the normal unified model with shift operations implemented in Tensorflow. If the split flag is set, new outputs are added prior to every shift operation and new placeholders are added following the shift where post-shift inputs are fed.
The implementation of this logic is simplified as the shift module is only inserted into structures which resemble the 3-stage MobilenetV2 bottleneck shown above. However, for resnet models we make sure to insert the shift pipeline stage after the reduction logic in the shortcut path. As the shift + convolution path is independent from the shortcut path until the bottleneck layer is complete, operations on the shortcut path can be placed in any of the 3 stages.
DPU Quantization StrategyWhile pipelining the models as described above simplifies the shift implementation, it complicates DPU deployment as our network is no longer a single kernel. Instead we have a kernel for every pipeline stage without a shift operation (11 for MobilenetV2, 17 for resnet50).
In order to quantize such a network we must have unquantized inputs for each kernel. To generate this information our models can also be generated without the pipeline stages. We then perform inference directly in Tensorflow on frames from the real calibration dataset, however we dump the intermediate network state at every pipeline boundary. The dumped state includes metadata such as node names, which need to be fed to vai_q_tensorflow, as well as the corresponding tensor data. All of this information is pickled as inference is repeated across the calibration set.
After dumping this intermediate inference information, we have input tensors for every kernel fed to vai_q_tensorflow. This logic is all handled by the DUMP_QUANTIZE flag in our tensorflow model scripts and the quantize_split.sh scripts (project structure is described in the “Deployment” section). Once quantization is run for all kernels, we can then generate an ELF file per kernel for integration into our main demo codebase.
There are a couple of tradeoffs with this approach. One is potentially worse quantization performance as with the current implementation later kernels do not see the quantized output of earlier stages. This, however, does not seem to be a large problem as the quantization algorithm used minimizes activation difference, so it seems minimizing the difference from unquantized intermediates is acceptable. The second cost is the potential need to rescale intermediate outputs during deployment (see rescale_input in main.cpp). This occurs if the output scaling of the previous kernel does not match the input scaling of the current kernel. If this is the case, the intermediate activations must all be scaled to preserve correctness.
Kinetics VCU IntegrationTo integrate the ZCU104 VCU into this project we create a script vcu_8frame.sh (located in fpga_build/resnet_tf_split/). This script will take an mp4 h.264 encoded clip from a video and dump the frames (scaled and center-cropped) for use by the resnet50 kinetics model.
Such functionality is very useful for this model as kinetics inputs can be long input videos for which only a short (~10s) clip is relevant. The ability to decode quickly using the VCU speeds up the process of the frames for future inference. Further integration with gstreamer allows offloading of scaling and cropping.
ResultsBelow we present performance breakdowns for the 2 platforms (ZCU104 and Ultra96V2) and 2 models (MobilenetV2 Online TSM and Resnet50 Offline TSM). We calculate FPS as 1/(preprocess + inference latencies).
MobilenetV2 Online TSM Latency:
ZCU104 (60.1 FPS) - B4096, 300MHz, RAM High, all features enabled
Ultra96V2 (38.4 FPS) - B2304, 300MHz, RAM Low, all features enabled
We can now compare the inference latency with previously gathered data of TSM on the mobile devices and NVIDIA Jetson platforms.
Deployment
All code for these demos is located in the fpga branch of the TSM github repository (https://github.com/mit-han-lab/temporal-shift-module).
In order to generate these tensorflow models, we create the TSM models from a fork of the tensorflow slim model repository. This is done in the files forming the core of the project in resnet50_tfslim.py and online_demo/mobilenet_v2_tfslim.py (pulled from the submodule using setup_tfslim.py).
Within each of these scripts we (1) build either the split or unsplit tensorflow model (2) import the trained weights from the TSM pytorch checkpoints (import_pytorch_weights), (3) export the split model for quantization, and finally (4) generate quantization inputs as described in “DPU Quantization Strategy”. Once all of these steps are complete (specific steps described in the README), one can use the vitis-ai docker container to quantize and compile the models.
The fpga_build directory contains the scripts and source code to use the generated quantization inputs with vai_q_tensorflow (quantize_split.sh), compile the DPU kernels from quantized output (compile_split.sh), and finally generate the demo executables (Makefile).
Once an executable is built it can simply be copied to FPGA and run. Note: both demos can be configured through src/main.cpp to take test inputs.
Environment SetupTo setup the development environment for these demos, initial Vitis-AI environment setup should be followed as described here: https://github.com/Xilinx/Vitis-AI. The ZCU104 DPU image used is described here: https://github.com/Xilinx/Vitis-AI/tree/master/mpsoc, and the ZCU104 VCU image is built following the ivas example application described here: https://github.com/Xilinx/Vitis-In-Depth-Tutorial/tree/master/Runtime_and_System_Optimization/Design_Tutorials/02-ivas-ml. The Ultra96V2 image is built from the 2020.1 Avnet BSP and enabling Vitis-AI during petalinux build (https://github.com/Avnet/vitis/tree/2020.1)






Comments