Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
This project goes through the steps of developing a smart parking lot ML model on Edge Impulse and deploying it on the MaaXBoard. Clinton Oduor's blog covers an existing Faster Object, More Objects (FOMO) model on Car Parking Occupancy Detection. The project in this post uses this existing model as a template to develop an occupancy detection system for vehicles that recognizes occupied AND free spaces. In addition, there's an object counting script that works with FOMO models. More details on what files are needed and how it works are on this Edge Impulse site. The script has been modified to count and display the number of free and taken spaces in the parking lot. More background on FOMO can be found on this Edge Impulse documentation.
A few of the applications of the MaaXBoard including Embedded Computing and Machine vision will be showcased and a few Edge Impulse models (MobileNetV2 SSD, FOMO MobileNetv2 0.1 and FOMO MobileNetv2 0.35) will be compared.
This post will walk through:
- Collecting data, then annotating and uploading images from CVAT to Edge Impulse
- Comparing the speed, accuracy and power consumption of the MobileNet SSD, FOMO.1, and FOMO.35 models provided by Edge Impulse
- Using a script to display the number of objects counted by each model
The part of this project that consists of comparing the Edge Impulse models involves working through Installing and Running Edge Impulse on the MaaXBoard up to after the Installing Edge Impulse CLI and SDK step and Benchmarking Edge Impulse on the MaaXBoard up to the Current Run Formula step after this line:
export LD_LIBRARY_PATH=/usr/local/lib:/home/root/portaudio/lib/.libs:$LD_LIBRARY_PATH(for this one, the only differences in the steps are the types of images, models, and scripts being copied to the MaaXBoard directory).
Make sure you have:
- All the necessary software added to the MaaXBoard (Python, OpenCV, TF, Tflite)
- Edge Impulse Linux installed
- Portaudio Installed
- An image of the mock parking lot and cars (for testing the Edge Impulse models)
- A video of the mock cars being moved in the mock lot (for object counting with the models)
Current Edge Impulse Models: Each project uses one of Edge Impulse's provides models. Feel free to clone any of these projects and modify them however you would like.
Scripts:
pas2ei.py : A script also referenced in Monica Houston's Hard Hat Detection Project. It's a python script used to convert Pascal VOC obtained from CVAT to an JSON file formatted to be uploaded on Edge Impulse.
ei_benchmark_smart_parking_temp.py: It's a Python script used to measure object detection performance parameters from a.eim file (number of boxes detected and their accuracy and inference speed). It also a a few lines that help prevent the same object from being detected more than once when the boxes are displayed.
space_counter.py: A object counting script provided by this Edge Impulse site modified to count "free" and "taken" spaces in a video. It also has lines that help prevent the same object from being detected multiple times.
Data CollectionCollecting data
For those starting from scratch, you can connect to Edge Impulse through various means to collect and upload data.
Go to the Devices tab on the far left
Then click on Connect a new device on the far left
Uploading data
For those who have existing data, in the Data acquisition section, click on Upload data
Browse for the needed files, click Upload then Upload data
If the images uploaded don't have labels for object detection, you'll have to go to the Labeling queue and annotate them on your own or with provided Edge Impulse tools
For those who want to add annotated data to Edge Impulse, I recommend using the Computer Vision Annotation Tool (CVAT) software to make the annotations
Open Google chrome, go to CVAT and either log in or make an account
In the Projects tab, find the blue plus sign on the far right, click on it and select Create a new project
Add the necessary names and labels and click Submit & Open when finished
Once the project is created, click on the blue plus sign on the far right and select Create a new task
A window opens in which you name the task and add the images that need to be annotated. Click on Submit & Continue when done
Click on the Job number and you'll be directed to the page where you add annotations to your images
Annotate by drawing boxes with the rectangle tool and you can make changes to the annotations on the far right
- Note any other tool used for annotating may not be recognized when uploading the annotated images to Edge Impulse
When all the images have the labels needed, export the images to the Pascal VOC format by clicking Menu, then Export job dataset
Use the pas2ei.py script to convert the Pascal VOC to a labels file that Edge Impulse will recognize. Then upload the images along with the labels file to Edge Impulse under Data Acquisition
- Note after the script runs, change the name so that it is recognized by Edge Impulse as a bounding_boxes.labels file
- All the images uploaded should contain the annotations previously made
For more details on annotating for machine learning, go to Monica Houston’s post
Don't worry! After labeling the images, there won't be any other time consuming steps!
A Potential Issue
After going through the motions of Impulse design in the Edge Impulse studio, you'll see an F1 percentage accuracy score as well as a confusion matrix.
Although the score and matrix look good, you may see the same object being detected multiple times.
- When you see the Model testing with 100% accuracy, your model is most likely overfitting
This means the model with the existing data is overfitting. The model works well with the training data, but it struggles when tested with types of unfamiliar data.
To mitigate this:
- Add more data
- Increase the number of training cycles
- Reduce the learning rate
- Experiment with batch sizes 16, 24, and 32
Go to Deployment, select Linux(AARCH64), click Build and Object detection model (eim file) will be downloaded
Use scp to copy the model to the MaaXBoard root directory
Ex:
scp benchmark_v3-linux-aarch64-v9.eim root@'IP Address of MaaXBoard':/home/rootThen use the chmod +x command on the model to avoid issues with permissions
Ex:
chmod +x benchmark_v3-linux-aarch64-v9.eimUse the ei_benchmark_smart_parking_temp.py script to run the model(s)
- It's a template so you'll have to change the path of the eim model, and the image you'll be using for testing
This is the test image for the Edge Impulse models:
Follow the Current Run Formula making sure you're in your virtual environment.
Make sure that you're in your virtual environment:
source myenv/bin/activateCopy and paste the next line into the terminal. If needed, replace the path below with the one obtained after using the sudo find command:
export LD_LIBRARY_PATH=/usr/local/lib:/home/root/portaudio/lib/.libs:$LD_LIBRARY_PATH- Every time you want to run the script, you'll have to copy and paste that
exportline whenever you're in the virtual environment to avoid an ImportError
Run the script with the command format shown below:
Ex:
python3 ei_benchmark_template.py /home/root/benchmark_v3-linux-aarch64-v9.eim /home/root/MaaXBoard_folders/test_pics/fruit.jpegAfter the code successfully runs, you should have a new, annotated image saved in the same directory the original image was in
Use scp to see the annotated image on your computer:
scp /home/root/MaaXBoard_folders/test_pics/annotated_image.jpeg 'username'@'Computer or Workstation IP Address':/homedirectoryAfter running the ei_benchmark_smart_parking_temp.py script and moving the annotated image to your computer, you will see bounding boxes on the objects that were used for one Edge Impulse model (MobileNet SSD), and you'll see labels with smaller boxes on another model (FOMO.1 &.35).
FOMO.1 Output
Found 6 bounding boxes (78 ms.)
Processing label: taken, Score: 1.00
Processing label: taken, Score: 0.98
Processing label: free, Score: 0.96
Processing label: taken, Score: 0.77
Processing label: taken, Score: 0.83
Processing label: taken, Score: 0.94
- Five objects (4 "taken" 1 "free") have been correctly detected
- One of those objects has been detected twice (light green car), but the script made sure it was marked only once
- Three remaining objects (two spaces and dark green car) have not been detected
FOMO.35 Output
Found 9 bounding boxes (86 ms.)
Processing label: taken, Score: 0.86
Processing label: taken, Score: 0.93
Processing label: free, Score: 0.92
Processing label: taken, Score: 0.86
Processing label: taken, Score: 0.84
Processing label: taken, Score: 0.98
Processing label: taken, Score: 0.94
Processing label: taken, Score: 0.86
Processing label: taken, Score: 0.50
- 6 objects (5 "taken" 1 "free") have been correctly detected
- Two of those objects has been detected multiple times (red car x2, dark green car x3)
- Two remaining objects (two spaces) have not been detected
MobileNetSSD Output
Found 10 bounding boxes (688 ms.)
Processing label: free, Score: 0.97
Processing label: taken, Score: 0.96
Processing label: free, Score: 0.92
Processing label: taken, Score: 0.89
Processing label: free, Score: 0.87
Processing label: taken, Score: 0.86
Processing label: taken, Score: 0.86
Processing label: taken, Score: 0.86
Processing label: taken, Score: 0.78
Processing label: free, Score: 0.77
- All 8 objects (5 "taken" 3 "free") have been correctly detected
- Two of those objects has been detected two times (top left space & light green car)
Visual Summary
Conclusion
Although both FOMO models had the same parameters for the Impulse design, FOMO .35 had a lower F1 accuracy score (81.4%) compared to the FOMO .1 accuracy score (97.5%). Even with the lower accuracy score, it was able to detect more objects in the same image. The MobileNet model consumed more power and its inference speed was about 8 times longer, but it detected all the free and occupied spaces in the image. The models were still overfitting, but the difference in overall performance could still be seen from each one.
Counting Spaces on FOMO modelGo to Deployment, select Linux(AARCH64), click Build and Object detection model (eim file) will be downloaded
Use scp to copy the model and the video that you want to count objects in to the MaaXBoard root directory.
Use the space_counter.py script to run the object counter.
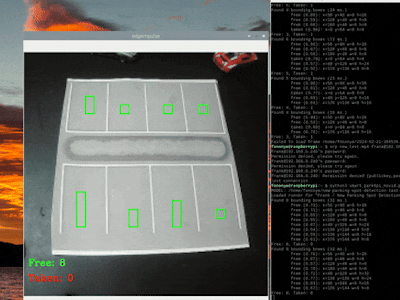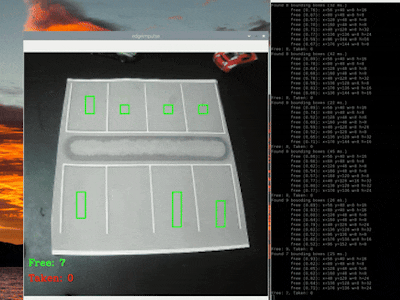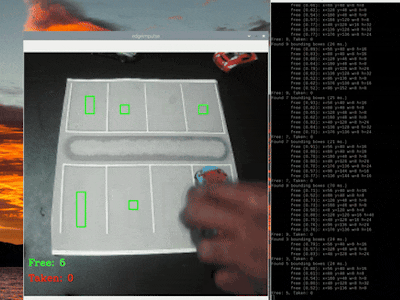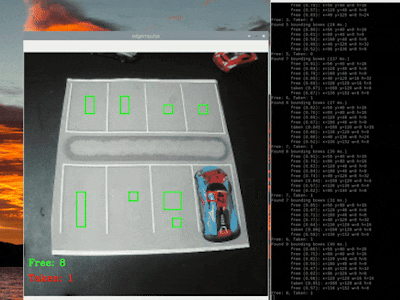
Here are gifs that show both "free" and "taken" spaces being counted:
FOMO.1
FOMO.35
MobileNet SSD





Comments