

Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
When you create a Machine Vision project, you need a large database of labeled images to train your model.
Comparing Image Annotation ToolsCollecting and labeling data is probably the most crucial and often the most time consuming and tedious part of any machine learning project. This is an illuminating breakdown from Cognilytica that shows that data related tasks make up 80% of machine learning project time, and data labeling makes up 25%:
Despite their importance, data collection and annotation were barely covered in the machine learning courses that I've taken in grad school and online. I wanted to fill in my knowledge gap a bit by comparing different annotation tools on real world data.
Types of annotation
Before starting this project, I didn't realize that there were so many different types of image annotation, from simple bounding boxes to 3D cuboids:
Most image annotation tools are only capable of a subset of these types of annotation. I need simple bounding boxes to do chicken detection, so that narrowed down my search a bit.
The contenders:
There are many free and open source image annotation tools. Wikipedia has a helpful list here.
My criteria for an image labeling tool: able to tag video or still images, maintained by a consortium or group, easy to install, and runs on Mac, Linux and PC. After narrowing it down, there were two major contenders:
CVAT: is another free and open source tool that is part of the Open Vino Toolkit.
VoTT: stands for visual object tagging tool. It's free and open source and it's maintained by Microsoft.
Collecting the dataI want to create a model that can identify each of my four chickens by name and let me know when they're in the coop. The data I collected is from a MaaXBoard using a USB webcam. I set it up to run using ffmpeg (full chicken cam project is here).
I collected both still images and video. To collect still images, I ran the following script via ssh:
nohup ffmpeg -s 640x480 -i /dev/video1 -r 1 chickens-%04d.jpegTo collect video, I ran this script:
nohup ffmpeg -s 640x480 -i /dev/video1 -r 1 chickens.mp4- s 640x480 sets the resolution. This is the smallest resolution I found that got good enough resolution for me to (usually) identify the chickens by sight.
- I /dev/video1 sets the input source to the USB webcam.
- r 1 sets the frame rate to one frame per second, which I figured would be fast enough to catch the chickens in action by not overload me with too many frames.
How much data do I need?
While researching for our project Dobble Buddy, I found that 1, 000 images is the standard minimum for training an image detection model. However, you can can get by with fewer, and for well-constrained tasks like facial recognition you can even be successful with just a handful of images. In the interest of time, I decided to get 200 images per chicken. I have read that even this few images means at least 20 hours of image annotation.
The chickens are typically in the coop from sunset to sunrise, and then they pop into the coop a couple times a day to either lay eggs or to annoy/encourage the other chickens who are laying eggs. Once the data is collected, it's time to install the tools.
What should I label?
Object detection is a computer vision technique that deals with distinguishing between objects in an image or video. While it is related to classification, it is more specific in what it identifies, applying classification to distinct objects in an image/video and using bounding boxes to tells us where each object is in an image/video. Face detection is one form of object detection.
This technique is useful if you need to identify particular objects in a scene, like the cars parked on a street, versus the whole image.
This was a hard question for me. Using the coop cam, I can see chickens in both upper and lower levels of the coop. Sometimes the chickens in the lower level are obscured, so I can only see their heads or tails. In that case, is it still good practice to label them?
Also, sometimes when they're in motion, they appear as a blur. Should I label them then? Finally,
CVATYou can use the online tool at https://app.cvat.ai. Alternatively, you can install CVAT.
Install CVATCVAT is maintained by OpenCV on their github here. The installation guide for CVAT is here. It can be installed on Ubuntu Linux, Windows 10, or Mac OS Mojave. It requires Docker and Google Chrome.
1. Clone the github repo:
git clone https://github.com/opencv/cvat
cd cvat2. Install Docker.
3. Run docker containers from within the repo:
docker-compose up -d4. Create a superuser:
docker exec -it cvat bash -ic 'python3 ~/manage.py createsuperuser'You'll be prompted to enter your email address (leave blank for default username "docker") and password.
5. Open the installed Google Chrome browser and go to localhost:8080. Type your login/password for the superuser on the login page and press the Login button. Now you should be able to create a new annotation task.
Detailed documentation on creating a new project is here.
1. Select "Create new project" to create a new project. Give it a name.
2. Add your labels. Give each label a color.
3. To create the project, select "Submit." To see your project, select "open project" in the dialogue box that appears.
4. Select "Create new task" to under your new project. You can create many tasks under a single project and assign them to different users.
5. Give it a name and select your data subset (train, validation, or test).
6. Drag and drop your images to upload them, or select a remote source.
7. Under advanced options, change the Segment size if you would like to divide the project into multiple jobs to assign to different people. There are many other options here that are especially useful when working with huge datasets.
8. Once the task is created, you can find it under the "tasks" tab. Select "Open" in order to review it and start annotating!
1. To start annotating, select the "job" under your task.
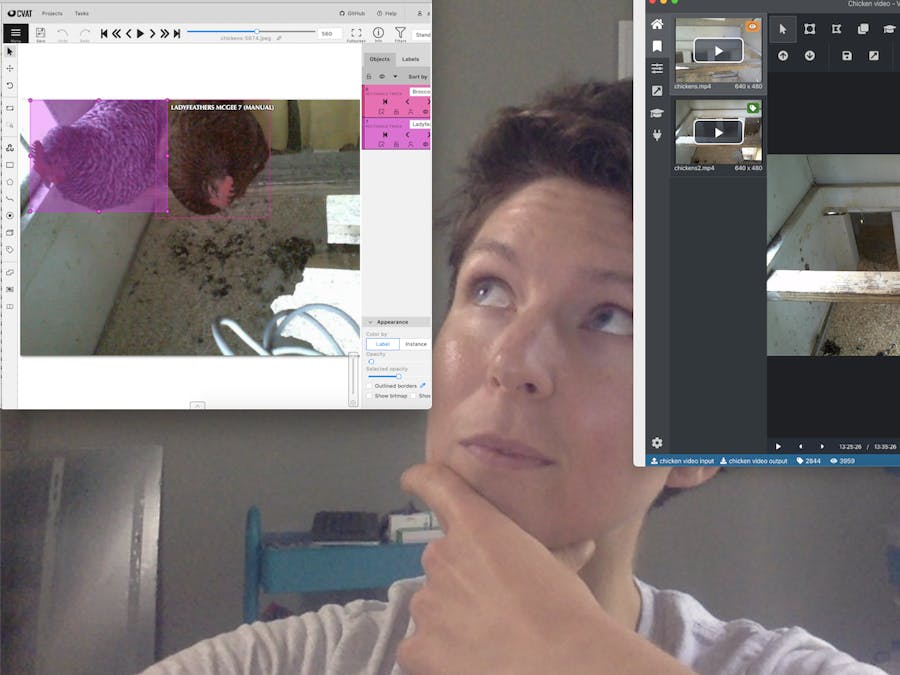
Right away, I can see some obvious benefits to using CVAT. They support all of the types of image annotation I noted above. The controls on the side let you choose which annotation type you'd like to use.
The controls at the top of the screen allow you to scroll through your still images easily, or even play them, so you can pause as soon as the desired object comes into view. You can also use the arrow keys on your keyboard to do this.
I'll be using the rectangle annotation. To start annotating:
- Select "Draw New Rectangle" and select your label
- Select shape mode to only draw on a single frame
- Select track mode to track an object across multiple frames.
- Draw your shape on the screen over the object you would like to label.
- If you're using track mode, you'll see the play controls in your object label in the sidebar.
- As the object moves in the next frame, simply drag the corners so the label fits on the object in the next image.
- When the annotated object disappears or becomes too small or blurry, choose
Outside Property, shortcutO, to remove the label from the screen.
NOTE: Clicking "remove" on your object when using track mode will delete ALL frames you've added.
Don't forget to click "save" periodically as you go to save your work. If you try to navigate away from the page without saving first, your work will be lost (it will warn you if you do this). You can also enable auto save by selecting it under Settings (click on your username in the top right corner, and then click Settings).
You can see how many labels you've tagged so far by selecting "info" in the top right.
In CVAT, tagging video is exactly the same as tagging still images.
Exporting Labels from CVATOnce you're done labeling, select "Menu" > "Dump Annotations" and then choose the type of dataset you would like to export as. CVAT lets you export labels in a ton of different formats!
Types of modelformats
Having only used pre-made datasets I found online (or that my colleague Mario found) I also didn't realize that different types of models require different types. For instance,
The TensorFlow Object Detection API requires the data to be in the somewhat obscure TFRecord format.Understanding TFRecord and getting it right is not an easy task and may take some time.
I chose tfrecords. After a minute or so, you'll see the files are downloaded as a zip folder.
If you open the folder, you'll see two files
CVAT also includes tools for semi-automatic and automatic annotation: https://openvinotoolkit.github.io/cvat/docs/administration/advanced/installation_automatic_annotation/
VOTTInstall VoTTThe easiest way to install VoTT is using the prebuilt installers from the GitHub Releases. You can also build from source (requires node & npm) or use the online version of the tool (only allows Azure blob storage or bing image source as data connections, so you can't add files from your PC unless you upload them to Azure first).
Set up your project in VoTTThis part is really easy.
1. Name your project
2. Leave security token blank, or choose a security token from a previous project. Encryption isn't necessary for my project, because I'm not concerned about protecting my chicken's identities (should I be?). However, it's a great feature if you're dealing with sensitive data.
3. Add source connection. This is where your data is located. You can choose between Azure blob storage, bing image search, or your local file system. I chose local file system because I only collected about 50 gigs of data which I have in a folder on my PC. Choose "save."
4. Add target connection. I recommend choosing a different connection than your source connection for your target connection. WARNING: If you change this connection after labeling your images, you will have to move the.json files from your original connection folder into the new connection folder or you will lose all your labels.
5. Write a project description (optional)
6. Choose a framerate (if using video)
7. Enter your tags or labels. I added the names of my chickens, as well as a default "chicken."
8. click "save." This will generate a project named [your project name].vott in the target connection folder that you selected earlier.
Tagging still images in VoTTFirst of all, this is going to take a long time. I recommend putting on your favorite podcast and pouring yourself a beverage.
In the sidebar you will see the tags you added in the previous step. VoTT lets you draw rectangles or polygons, but that's the extent of the shapes it allows.
I noticed that if I placed a bounding box around an image touching a corner of the screen, if I copy the same tags onto the next screen, the bounding box will show up at 0, 0:
As you go, you will notice your output connection folder filling up with.json files. There will be one for each image.
While going through all of these images, you may be wondering: with all of our machine learning tools, isn't there an easier way to find the images we're looking for?
Tagging videos in VoTTTagging videos is slightly different from tagging still images in CVAT, so it's worth noting the differences. It seems that only.mp4 files are allowed in VoTT.
Labeling video is very similar to labeling still images, with the exception that it includes video playback controls and two extra pairs of buttons: previous and next frame.
In order to draw a tag on the frame, you must use the "previous/next frame" buttons. If you try to tag an image simply when the video is paused, clicking on the frame will restart playback. I found it frustrating that I wasn't able to tag a chicken in the first frame it appeared and then the last frame
Use active learningWhat is active learning? From this Microsoft blog:
Active learning refers to the subset of machine learning algorithms designed for projects featuring a lot of unlabeled data, in which labeling all that data manually is unfeasible. When using active learning, the algorithm is able to select a smaller subset of the data, and then prompt the user to label it. It’s worth mentioning at this point that the samples aren’t selected at random, but instead there are policies for selecting samples, mainly aimed at minimizing the model’s prediction error.
VoTT offers active learning, and they provide Coco SSD free, so if the images you're labeling correspond to any of the 90 classes defined in the model, you may be able to test it out. Unfortunately, chickens aren't included in their classes.
They also allow you to use your custom model. In order to get your custom model to work with VoTT, you could use the TensorFlow Object Detection API to train your custom model. You'll likely want to use transfer learning to save time. You must then use the TensorFlow.js Converter to convert the TF model to the Tensorflow JSON format needed by VoTT. This is a many step process that requires a Docker environment running Python 3.6.8.
You'll need to place the weights binary files referenced in the model.json file and the custom classes.json file containing your labels on a folder (see the cocoSSDModel model format that they're using here). You can also find a number of TF.js models at Tensorflow's model zoo here, which you could download and format according to the required format.
Because this is rather complex, I may create a separate tutorial showing how to set this up. Let me know in the comments if this would be helpful for you.
Exporting Labels from VoTTOnce assets have been labeled, they can be exported into a variety of formats. Select the arrow button to export.
1. Choose your label format. VoTT allows the following formats
- Azure Custom Vision Service
- Microsoft Cognitive Toolkit (CNTK)
- TensorFlow -TFRecords. This exports each label as a .tfrecord, as well as a tf_label_map.pbtxt file that maps images to labels.
- Tensorflow - Pascal VOC. This option gives you a slider bar so you can choose your test/train split.
- VoTT (generic JSON schema). It's not actually necessary to export these, since VoTT has been saving JSON files for each tagged image as you go.
- Comma Separated Values (CSV). This is good for PyTorch.
2. Choose which assets you want to export. You can export all assets, only visited assets, only tagged assets.
3. Choose whether or not to export unassigned data. Select "Save Export settings."
4. Back in your project, click on the export icon. Your exported files will appear in the output directory you defined earlier.
Note that when you export video annotations from CVAT, it will export each frame as a separate jpeg into the output directory as well.
CONCLUSIONThe ResultsIt actually didn't take me as long as I expected to annotate with either tool, although it was still a couple days of mind-numbing box drawing.
CVAT:
- install time: 30 minutes
- ease of use: excellent
- types of annotations supported: all of them
- time taken to annotate 200 images per chicken: 7 hours
VoTT:
- install time: 5 minutes
- ease of use: good
- types of annotations supported: bounding boxes and polygons
- time taken to annotate 200 images per chicken: 10 hours
VoTT is actually part of Microsoft's Custom Vision Service. It recommend checking it out because it's not free, but it could potentially make your project way easier.
LESSONS LEARNEDLabeling best practices:
- Label entirely around the object
- For occluded objects, label them entirely
- Generally label objects that are partially out of frame
- Beware of labeling many boxes that overlap or are entirely contained within each other. This can really confuse your model.
Stillimages are generally easier to work with than video
- There are upsides and downsides to each of these. I found still images were easier to work with because it was easier to upload only parts of the dataset, and I didn't have to worry about my network to crap out while waiting for a huge video file to transfer from my MaaXBoard to my PC. Additionally, in CVAT when you have to select your test and train photos, you can easily select a variety of photos taken at different times, so your training set will have the best mix possible.
Bemindful of how you're collecting data to make tagging images easier
- You can use a library like motion to only capture an image if your camera detects motion.
Decide what framework you'll be using to train your model and annotate your images accordingly
- This is the most important thing I learned. For instance, for training an object detection model using Google's Object Detection API, annotations must be in either CSV, TFrecord, or Pascal VOC format. They have additional requirements for how your CSV must be formatted, so after exporting as CSV from VoTT, you'll have to write some sort of conversion script in order to even use the files. Prior to annotating data, look at the necessary annotation formats and ask yourself:
- Does the annotation tool I want to use export in the format required by the API/Framework that I'm using? If not, is it easy to write a script to convert it?
- Do the annotations I'm using provide the amount of detail my model needs to train? Does it provide too much detail (am I doing extra work?) For instance, CVAT allows you to mark
I just became aware of Roboflow's annotation conversion tool, and it's extremely useful! Roboflow is the "universal converter" for your images and annotations: upload in any annotation format, and export to any other.
Roboflow supports a wide array of export formats:
And many, many more.




Comments