

Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
| ||||||
 |
| |||||
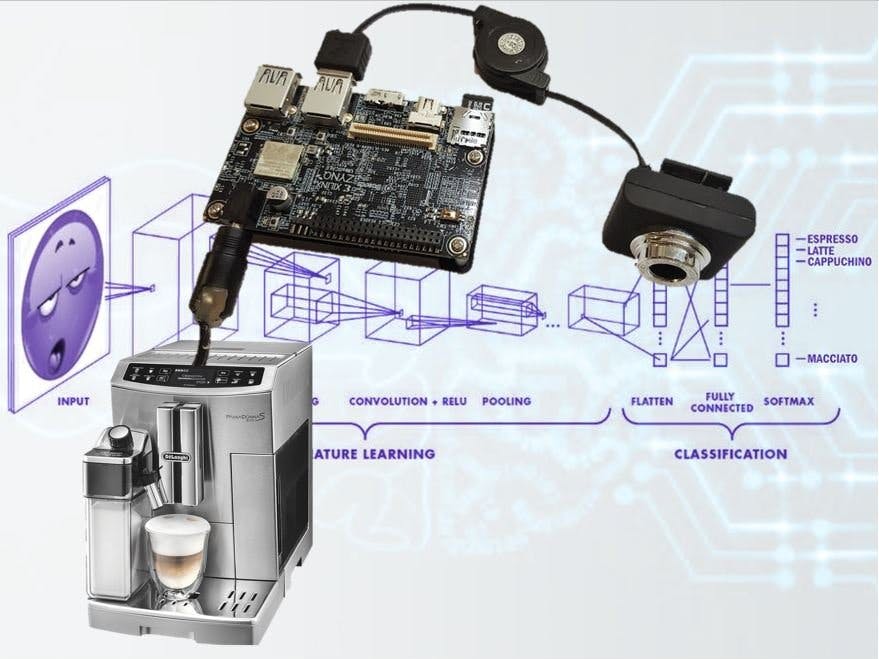
Deep learning is great! Coffee is great! It's time to bring the two together in harmony!
Convolutional neural networks can do things which were considered pretty-much impossible to accomplish just a few years ago. (relevant XKCD). Now, with a big data set, a working knowledge of Python, and the right deep learning API, the impossible has become a weekend project.
Everyone requires a different level of caffeination to perform at their optimum. Tragically, our current coffee-based caffeine delivery systems offer only a grossly unrefined dosage system, the so-called 'shot' system and differing milk volumes. ;) By leveraging the power of local deep learning, we can identify subjects via facial recognition, and log their caffeine dosage and intake.
Furthermore, by analyzing facial expression with deep learning, we can monitor tiredness and stress levels, and adjust their coffee strength accordingly. This AI system uses the Random Forest Machine Learning algorithm to tie these neural networks together, and lets the system learn the users' coffee preferences over time. The more you use it, the smarter it gets! This innovation will redefine our understanding of the coffee break, and usher in a new era of 'Peak-Caffeination,' which in turn will advance our efforts in science, engineering and technology.
As a further bonus, you'll learn how to install and use deep learning systems on your Ultra96 for other projects. You will be able to incorporate face and emotion recognition into you electronic projects!
GoalsThe goal of the Caffein-AI-tor project is to teach you how to get up-and-running quickly with deep learning and machine learning on the Ultra96. There are a lot of pitfalls you can avoid by following this guide. I know, because I fell in all of them while getting everything compiled and running :)
You could use this project as a basis for a smart home AI, a home robot, an intelligent burglar alarm, or even something thing like a wakefulness detector for drivers. Imagine the cosplay costumes you could build if the costume itself could react to the people around it!
Human-computer interaction become much more fluid when your computer knows who you are and what you want before you even touch the device. I hope you can incorporate this project into you own projects, and I can't wait to see what you will build!
Don't skip the Jupyter Notebook on GitHub! It has tons of useful information!
Extra InformationAt these links you'll find detailed information on the components we'll be using.
https://www.96boards.org/product/ultra96/
http://zedboard.org/product/ultra96
https://github.com/Xilinx/PYNQ
https://github.com/Avnet/Ultra96-PYNQ
http://caffe.berkeleyvision.org/
The Basic SetupGetting the basic hardware and software running.
We are using the awesome Pynq environment to make this great AI project. Download the Ultra96 Pynq Image, and use Win32DiskImager to get it onto your microSD card. More info is in the video below.
If you also forgot to order an appropriate power supply with you Ultra96, you can do what I did, and snip the cables of a 12 V DC power supply, and solder on an adapter tip from your odd-and-ends draw, then cover the exposed wires in too much hot-glue.
To get this going, we'll need to upgrade a bunch of stuff. First, we need to get online. We can use the Jupyter wifi notebook to get the wifi network running and get online. Connect to the Pynq AP, and browse to "http://192.168.2.1:9090/notebooks/common/wifi.ipynb" from the computer you connected to the Ultra96 board, and follow the instructions.
The key cells are:
from pynq.lib import Wifi
port = Wifi()
This gets the Wifi module ready, then we connect to our network with the next cell:
ssid = input("Type in the SSID:")
pwd = input("Type in the password:")
port.connect(ssid, pwd)
Then you can open up a terminal from the main Jupyter page and us the command 'ip a' to find your new ip address on you wlan. Disconnect from the Ultra96 access point, and now you can access the Jupyter notebook from the IP address, and it will have internet access.
Few steps, you'll need to SSH into the Ultra96; I like using Putty, but you can also use the Jupyter Terminal too!
Once this is done, it's good to upgrade Pip to the latest version:
$ pip3 install --upgrade pip
Setting up the main component.
We need to compile OpenCV. The version that comes with Pynq isn't the latest, with the needed DNN module for doing inferences in Tensorflow/CAFFE etc. We'll have to compile it for the Ultra96 to make sure its fully optimized.
We get it the source from Here, we'll download it first:
$ cd ~
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/3.4.3.zip
Extract the zip and move to the base directory.
$ unzip opencv.zip
$ mv opencv-3.4.3 opencv
$ cd ~/opencv
$ mkdir build
$ cd build
You need lots of memory for compiling OpenCV! this won't work directly on an Ultra96!, so you'll need swap space on an external USB drive. I plugged in a 8 Gb USB stick, and you can set up swap space quite simply. Make sure your USB stick is connected. In a terminal type:
$ sudo blkid
This will list all the storage devices on the Ultra96. For example, if your USB drive is /dev/sdx, you would use (you must be root for this):
$ sudo mkswap /dev/sdx
$ sudo swapon /dev/sdx
This will let the Ultra96 use the USB drive as swap RAM, giving you enough space for the compiler to do its stuff.
Note that this would use the whole device and you will probably lose all the existing data on it!
Then its time to configure OpenCV, using this command:
$ cmake -DCMAKE_BUILD_TYPE=RELEASE \
-DCMAKE_INSTALL_PREFIX=/usr/local \
-DINSTALL_PYTHON_EXAMPLES=ON \
-DINSTALL_C_EXAMPLES=OFF \
-DPYTHON_EXECUTABLE=/usr/bin/python3 \
-DBUILD_EXAMPLES=ON ..
This is fast, but the next bit will take hours:
$ make -j2
This will compile OpenCV for us! with '-j2' it took about 3 hours to compile. Using the option '-j4' might work for you faster, but for me it fails. If something goes wrong, simply delete the 'build' directory and start again. When it's finally finished, we can install OpenCV with these commands:
$ sudo make install
$ sudo ldconfig
How the parts come together.
The best way to control an appliance is with a state machine, and we can jot that down in a flowchart nicely, as shown below:
Basically, what we are doing is optimizing for responsiveness. As neural networks take a while to infer, we want to be sure the captured image is of a well sized, sharp face before we begin the process! So, we only proceed to the next step if we are sure it makes sense, otherwise we try again with the earlier faster steps.
- We capture a webcam image. This the really fast!
- We check if there has been movement since the last image. We compare it to the previous image, and see if there's a difference; pretty fast
- We make sure the image is sharp. If someone moves in the picture quickly, there can be motion blurring. We can estimate the blurriness be getting the variance of Laplacian Kernel; kinda quick. This is described below and implemented on the PL fabric for a super speed boost!
- We look for a face with a Haar Feature-based Cascade Classifiers. This works well, and is one of the faster ways to detect a face; maybe a dozen frames a second, so still nice and responsive.
- We check if the face is nearby, by making sure the detected face is big enough. It has to be large to crop to get a sample for the Convolutional Neural Networks; this sizing/cropping step is really fast.
- We then calculate the 'fingerprint' of the face with a Convolution neural network. Slow, over a second per calculation.
- We next calculate the emotion expressed on the face. Also a Convolutional network, about a second.
- We use the data to make our prediction with machine learning. We will use a Random Forest, its good and quick, and it learns the more you use it!
- Lastly, we set the GPIO's to control the coffee machine. Almost instantaneous!
Application Acceleration.
Image processing is an idea task to accelerate on programmable logic, as many image operations can potentially be perform in a parallel manner. In this project, we will be trying to determine if an image is blurry: we need to check the 'blurriness' at every point of the image, so we should try and do all those measurements in a very parallel way! Luckily, Xilinx has provided us with many functions from OpenCV, including some kernel processing accelerators. I'll explain how to use this feature to build a super-high-speed blurriness detector in programmable logic!
Install PYNQ computer vision overlays from PYNQ-ComputerVision,
$ pip3 install --upgrade --user git+https://github.com/Xilinx/PYNQ-ComputerVision.git
I'm not sure why, but I had to upgrade Pandas to get this to run!
$ pip3 install --upgrade pandas
To speed up the blur detection, we will outsource the calculation to the programmable logic. The Laplacian Kernel will be the magic function we will convolve with, the image, to detect sharpness and then blurriness:
This kind of convolution is provided for in the ComputerVision overlay, by describing the kernel as a Numpy array:
kernel = np.array([[0.0, 1.0, 0],[1.0,-4,1.0],[0,1.0,0.0]],np.float32)
It works like this: we multiple the 3x3 kernel by each 3x3 patch in the picture. If there is a similar sharp point in the patch, it produces a high value; a smooth patch will produce a low value. Once this is done for every patch in the whole image, we calculate the variance of all these values (how much they vary by). A nice sharp picture will have a big range of smooth and sharp points!
This get accelerated on the programmable logic: we feed the image to the PL and the these convolution calculations can be done in parallel to speed things up. This is done in milliseconds on an FPGA :) Then we can take back the resulting convolution image and quickly calculate the variance to get an estimate of the blur in Python.
To find faces in the captured webcam image, we'll use a Haar Cascade. It a clever way to find faces, as all faces have some similar features. It works by matching the face to simple black and white patterns, to capture the shading differences in a face. As the patterns are really simple, the calculations are easy and the algorithm can run very quickly, compared to a Deep Neural Network face detector which must do many more calculations. It might not be as accurate as a DNN, but for our purposes it 100% the right choice.
We'll use the OpenCV 'CascadeClassifier' modules with a pre-configured Haar Filter face face detection. Using this module, all the faces detected in an image will detected, and it will return as list of face coordinated we can use to extract the face images.
# Haar Cascade file
https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml
On this webcam capture, we found one face (mine!) and the output was used to draw a bounding box. We can even set a minimum size for the detected face, so we can be sure the person is close enough and the cropped picture will have enough detail.
faces = haar_face_cascade.detectMultiScale(face_frame[:,:,1], scaleFactor=1.1, minSize= (400,400) , minNeighbors=5)
The output is:
array([[678, 253, 467, 467]], dtype=int32)
We can also show the bounding box for the detected face, by using the coordinated to draw a rectangle on the image.
for (x, y, w, h) in faces:
cv2.rectangle(face_frame, (x, y), (x+w, y+h), (0, 255, 0), 2)plt.figure(figsize=(1 2,8))
plt.imshow(cv2.cvtColor(face_frame, cv2.COLOR_BGR2RGB))
We can set the minimum size for the detected face, so we know that the user is near and facing the coffee machine. With a faces found, we use the coordinates to crop the image, then its time for the deep learning AI magic...
Artificial IntelligenceWe'll need 2 separate deep learning networks for this project!
1) Facenet
The first is a face embedding, in which we identify people from their images. It's the kind of thing that's easy for humans to do, but nearly impossible to describe how to do in an algorithm. It's done with a Convolutional Neural Network that's trained using something called Triplet Loss.
What happens is that a neural network is trained to compress all the inputs (thousands of pixel in a photo of a person), into just 512 numbers. An analogy would be for a person to learn lots a of city names and their postcodes. Cities with postcodes that are numerically close together are usually spatially close together, and they often share cultural traits, like favorite fast foods and accents. In the same way, the 512 numbers the Convolution Neural Network generates are more similar with similar faces. If two pictures are from the same person, the numbers are nearly identical. Triplet loss uses three images for each training step: two pictures are of the same person in different setting to bring the output numbers closer together, and a picture of a second person to drive the numbers apart.
Once we have our Neural Network trained, we give it a face found on the webcam, and generate a 512-dimensional embedding. We can store it in a Python list, and when we see another face in the webcam, it can be compared to the stored embeddings using euclidean distance between the vectors. In 2D this would look like the diagram below, but we are working in 512-dimensional space!
We calculate the length of the vector between the embeddings, and see if its really similar:
cutoff = 0.5
# List-comprehension to find the position of the face in the list of known faces
postion = [i for i,face_encodings in enumerate(known_faces) if np.linalg.norm(face_encodings[0] - facenet_fingerprint, axis=1) < cutoff]
The key calculation is 'np.linalg.norm(face_encodings[0] - facenet_fingerprint'). Here we subtract one vector from another, and use the np.linalg.norm module to calculate the length.
Training a Convolution Neural Network takes days, but we can take a trained model, and reuse it on the Ultra96. Each time we see a person, we use it to calculate the 512-digit 'fingerprint', and then we compare it to the people we have previously seen. If we find a match, we can use that persons previous caffeinated-beverage selections to train our model, and if not, we store the new ID.
We'll need to download the model structure and trained model data from here:
# Caffemodel: face_model.caffemodel
# caffemodel_url:
http://dl.caffe.berkeleyvision.org/bvlc_googlenet.caffemodel
# deploy_file:
https://github.com/ydwen/caffe-face/blob/caffe-face/models/bvlc_googlenet/deploy.prototxt
# rename deploy.prototxt file to bvlc_googlenet.prototxt
2) Emonet
The second Neural Network we will use can estimate the Emotion of the person in the picture. Instead of training a Convolution Neural Network to create a 512-digit fingerprint of a person, it is train with labelled images to generate a one-hot encoding. To train such a network, lots of pictures of people, each labelled 'happy', 'sad', or 'angry' etc are feed into the network.
One-Hot encoding of our three emotions looks like this:
'Happy' = [1, 0, 0]
'Sad' = [0, 1, 0]
'Angry' = [0, 0, 1]
So, we train our Convolution Neural network to learn that a happy face should output [1, 0, 0] and so on. Of course, just like humans, it can never get it exactly right (thank goodness for flowers and chocolates!), so it will give a probability of each emotion instead of a hard value. For example, the output of an angry face might look like [0.1, 0.3. 0.6], which means the network is pretty sure the face looks angry, but maybe also a bit sad. We are going to use the detected emotion, together with the persons identity and coffee history, to train a third Machine Learning system to estimate what kind of drink the person will most likely want.
We'll need to download the model structure and trained model data from here:
# Caffemodel: VGG_S_rgb/EmotiW_VGG_S.caffemodel
# caffemodel_url:
https://drive.google.com/open?id=0BydFau0VP3XSNVYtWnNPMU1TOGM
# deploy_file:
https://drive.google.com/open?id=0BydFau0VP3XSOFp4Ri1ITzZuUkk
# rename deploy.prototxt file to EmotiW_VGG_S.prototxt
3) Classification with Machine Learning
We'll first need to install SciKit Learn, which is a tremendous collection of Machine Learning techniques.The easiest way to install scikit-learn is using pip, as we'll need to upgrade the dependencies, and this will require compiling scipy and numpy as well as scikit-learn, so expect about 4 hours of compiling :(
$ pip3 install -U --user scikit-learn
In the chart above, the x-axis and the y-axis represents two features. The circles and crosses represent two kinds of things. The Machine learning algorithm is trying to learn how to differentiate between the two classes by their features (moving the black line to a position that best separates the classes).
We will do the same thing with Machine Learning, and predict what kind of drink the user wants (the drinks class), using the users emotions and time (the features), by training on the users past choices. There are lots of methods to do this, but we're picking one of the more interesting techniques.
Random Forests
A decision tree is just a bunch of step-wise set of questions used to make a decision. For example:
1) Q: Is it Monday? The subject usually likes an espresso or double espresso on a Monday, otherwise a milk-based coffee.
A) Yep, its a Monday.
2) Q: Is the subject annoyed and tired looking? (The subject likes a double when they're tired)
A) Nope, they look happy!
Output: Give them an single shot of Espresso!
With lots of factors, a single decision tree is hard to create, and can overfit the data. So, we use machine learning to generate a forest of decision trees (lots of trees!), and combine the results, which is a bit like the 'Wisdom of Crowds'.
This classification training will rerun each time a user is able to select a drink. The input features array will be:
- the emotional state vector (floating point values)
- the time of day (floating point fraction of the time today)
- the day of the week (one-hot encoded value)
The target will be an array the same length of the previously selected coffee's.
One-hot encoding is simply a way to convert categorical data into numbers in a way the algorithm likes. We simply split the number items in each categories (types of coffee or days of the week), into columns, and give a value of '1' if the item matches the heading, or otherwise '0', the same as for the Emonet described above.
Whats amazing is that this powerful technique can be performed in 3 lines of python, once the data has been prepared in input_data and input_targets arrays:
# Create a Gaussian Classifier
classifier = RandomForestClassifier()
# Train the model using the training data
classifier.fit(input_data, input_targets)
# Generate new prediction
predicted_target =classifier.predict(new_input)
After each prediction, the users new data and selection are logged, so the more the user uses the Caffein-AI-tor, the cleverer the prediction will be. As in the animated GIF above, the classifier still has to decide where the class cutoffs lie, but with more data, a clearer line can be drawn.
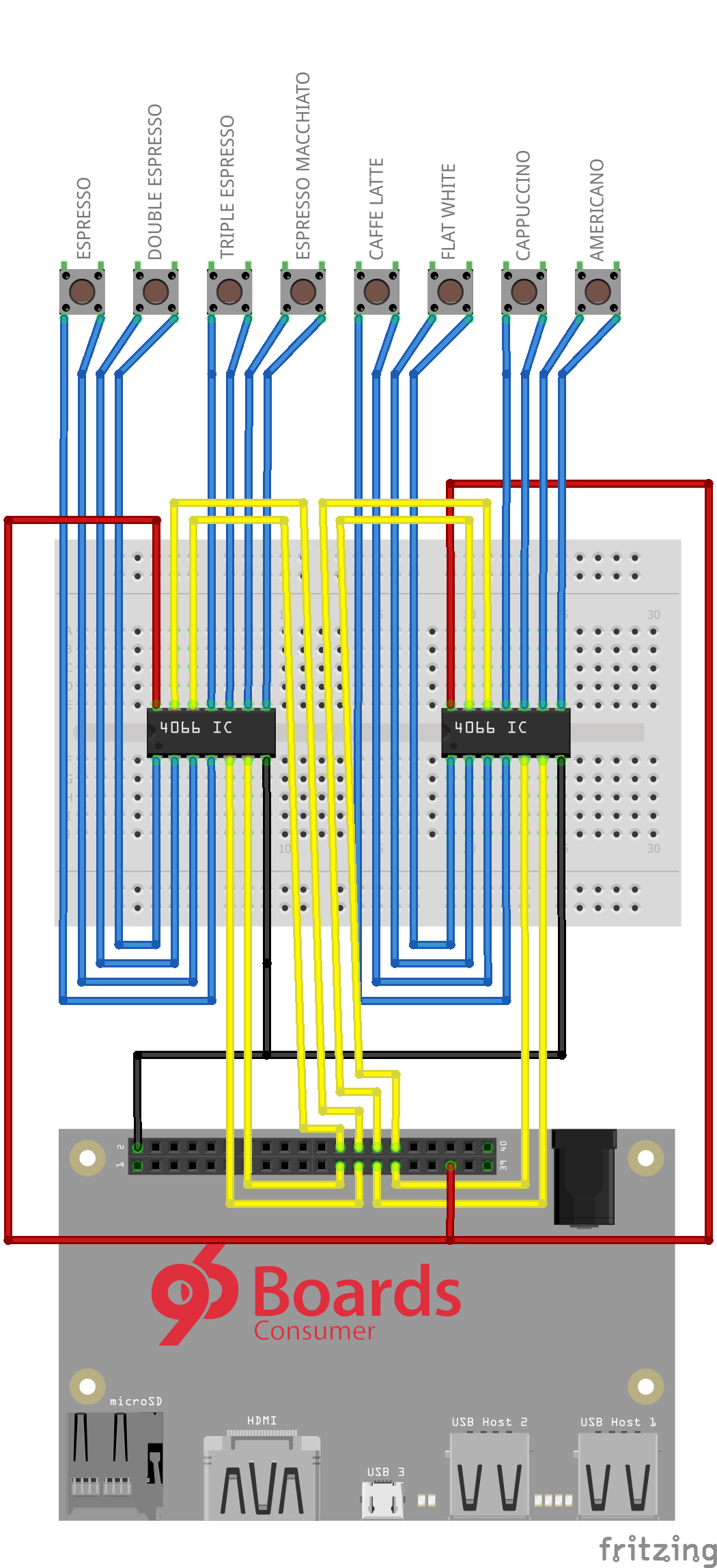
Hardware InterfaceTo interface to out (theoretical) coffee machine, we will use a few Quad Analog switches to interface to the physical coffee machine buttons. The switches will be wire in parallel, so both control options will still work.
We will use analog switches to save parts, so we don't have to use transistors to drives optocouplers or relays. They can be driven by the low voltages and current the Ultra96 board offers on its GPIOs. They don't share the same ground as the device, and their wide voltage range should work with most coffee machines!
The circuit layout is shown below, with the 4066 IC wired to the switches of the coffee machine, and the Ultra96. The 'theoretical coffee machine' and 4066 interface will be represented by 8 LEDs in this project, as it proves the point (and I don't have a spare coffee machine to hack within the contest period)!
We'll us the PS GPIOs, which can be controlled in python using the Pynq GPIO module. There are good examples on controlling the pins in Jupyter. This module interacts with Linux’s GPIO Sysfs API. In the same way, we can interface the User controllable LEDs, available in the sysfs at:
/sys/class/leds/ds2
/sys/class/leds/ds3
/sys/class/leds/ds4
/sys/class/leds/ds5
The Xilinx Linux wiki shows how to use them, and we can access the linux command line to modify their state, or by writing to the control files with Python, thanks to a tip from Green2:
# Python LED control functions
# thanks to Green2
def ledOn(led):
# Turns the given LED on
s = '/sys/class/leds/ds' + str(led + 2) + '/brightness'
value = open(s,'w')
value.write('1')
value.close()
def ledOff(led):
# Turns the given LED off
s = '/sys/class/leds/ds' + str(led + 2) + '/brightness'
value = open(s,'w')
value.write('0')
value.close()
def ledHeartBeat(led):
# Turns the given LED to heartbeat mode
s = '/sys/class/leds/ds' + str(led + 2) + '/trigger'
value = open(s,'w')
value.write('heartbeat')
value.close()
The system runs on a Jupyter notebook. Cells can be run to test each of the modules described above, or to run the entire system! Jupyter inputs provide an interface to select a beverage each time a face is detected when the last few cells is run!
You should run each cell, and try and follow whats going on. You can copy and use the code in your own python programs. You will have to use:
$ sudo python3 your_python_code.py
to use the correct python binary with all the correct permissions to load the Pynq module.
Of course, you don't have to use a coffee machine. Feel free to add AI to all your projects with this code!
A Few Final FPGA TipsLearning about FPGA as a hobbyist is daunting, but being about to have huge amount of GPIO and ports easily is really powerful and getting easier all the time. That said, here are a few last tips for Advanced Pynq users, learnt from hard experience:
- VHDL is not so hard, if you remember: It's all about state machines!
- When your write if/else/end if blocks, make sure you cover every possible case! Latches are bad.
- VHDL wires are NOT variables, they are really like wires! You can 'read' the voltage anywhere on a wire with your multi-meter, but if you try and 'set' it in more than one place with several power supplies, bad things will happen :)
- Use www.airhdl.com when you generate your AXI-Lite interfaces. You can use the generated IP in your block diagram. Then wire it directly to your HDL code in the block diagram. It's much easier to add and remove more AXI-lite/stream interfaces like this than to mess around in the new IP generator. And you can edit your HDL code without opening a whole project!
- For prototyping new IP in Python, you can start by examining the ip_dict generated from the TLC file by the overlay module. That will give you the memory offsets for the MMIO module. You can use the self-generated documentation from your www.airhdl.com project to read and write directly to the registers you created, no drivers necessary.
That's it! Good luck with your projects!







{kind=link}
Comments