


Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
_ztBMuBhMHo.jpg?auto=compress%2Cformat&w=48&h=48&fit=fill&bg=ffffff) |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 4 | |||
 |
| × | 2 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 2 | ||||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
| × | 5 | ||||
| × | 5 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 5 | ||||
Software apps and online services | ||||||
| ||||||
| ||||||
| ||||||
| ||||||
Hand tools and fabrication machines | ||||||
 |
| |||||
 |
| |||||
 |
| |||||
The world is in a great crisis. Situations all over the world are becoming worse than ever. Doctors are fighting with the virus, yet the situation cannot be controlled. The virus is spreading primarily via small droplets produced by coughing, sneezing, and talking. The droplets usually fall to the ground or onto surface rather than travelling through air over long distances.Doctors, Scientists ans Innovators are working hard to detect and destroy the virus thereby protecting the humans. On considering the current situation I planned of building disinfectant robot which uses UVC rays to kill the virus present on the surface thereby providing a better sanitation of surfaces. And that's how the idea of the bot Aurora was born.
UV on Viruses:What is UV?
Ultraviolet (UV) is a form of electromagnetic radiation with wavelength from 10 nm with a corresponding frequency of approximately 30 PHz to 400 nm with a frequency of 750 THz, shorter than that of visible light but longer than X-rays. UV radiation is present in sunlight, and constitutes about 10% of the total electromagnetic radiation output from the Sun. It is also produced by electric arcs and specialized lights, such as mercury-vapor lamps, tanning lamps, and black lights. Although long-wavelength ultraviolet is not considered an ionizing radiation because its photons lack the energy to ionize atoms, but it can cause chemical reactions and causes many substances to glow.
UV on Living things:
Short-wave ultraviolet light damages DNA in bacteria and fungi, RNA in viruses thus, preventing them from reproducing and sterilizes surfaces with which it comes into contact. For humans, suntan and sunburn are familiar effects of exposure of the skin to UV light, along with an increased risk of skin cancer. The amount of UV light produced by the Sun means that the Earth would not be able to sustain life on dry land if most of that light were not filtered out by the atmosphere. More energetic, shorter-wavelength "extreme" UV below 121 nm ionizes air so strongly that it is absorbed before it reaches the ground. However, ultraviolet light (specifically, UVB) is also responsible for the formation of vitamin D in most land vertebrates, including humans. The UV spectrum thus has effects both beneficial and harmful to life.
UVC and its effect on Virus:
UVC is also a kind radiation with a wavelength ranging between 200 nm to 280 nm and it is very useful for disinfection purposes. UV-C light is weak at the Earth's surface since the ozone layer of the atmosphere blocks it. The devices that produces UVC radiation for the purpose of disinfection are generally termed as Ultraviolet germicidal irradiation devices. Ultraviolet germicidal irradiation (UVGI) is a disinfection method that uses short-wavelength ultraviolet C light to kill or inactivate microorganisms by destroying nucleic acids and disrupting their DNA, leaving them unable to perform vital cellular functions.
How UVC Disinfection Works?When biological organisms are exposed to deep UV light in the range of 200 nm to 300 nm it is absorbed by DNA, RNA, and proteins. Absorption by proteins can lead to rupture of cell walls and death of the organism. Absorption by DNA or RNA (specifically by thymine bases) is known to cause inactivation of the DNA or RNA double helix strands through the formation of thymine dimers. If enough of these dimers are created in DNA, the DNA replication process is disrupted, and the cell cannot replicate.
Research says, it is not necessary to kill pathogens with UV light, but rather apply enough UV light to prevent the organism from replicating. The UV doses required to prevent replication are orders of magnitude lower than required to kill, making the cost of UV treatment to prevent infection commercially viable.
UV Disinfectant Robot:UV robot or UV disinfectant robot is a kind of robot generally used in medical field for surface disinfection purposes. I found that UV robots are rarely employed in hospitals and other institutions due to its cost and difficulty in operating it. Normally, the cost of the UV robot is too high. I've came across some UV robots which are commercially available in the market and I was shocked on seeing its cost. So, on keeping the above factors in mind, I've designed an Autonomous UV disinfection robot "Aurora". Aurora is a low cost, user friendly, autonomous and mobile phone controlled robot.
Aurora:On considering the factors such as cost, stability, reliability, efficiency and ability to control the robot by the user, I've made an innovatie design of the UV disinfectant robot - "Aurora". Aurora is a low cost, autonomous, voice controlled as well as smartphone controlled robot.
Let's discuss briefly about the component selection for the robot.
Hardware Specifications of the robot:In this section, we'll be discussing about the hardware considerations and specs of the robot.
NVIDIAJetson Nano:
Jetson Nano will be the computer (brain) of our robot. You may think why I've chosen this board among many of the choices of SBC's, that is beacause of its hardware architecture, speed and as well as its software compatbility. Also since Jetson Nano is specially designed for autonomous robotic applications, this board will be best suited for our robot. More details about the jetson nano can be found here. Since Jetson Nano lacks inbuilt wifi module, it is necessary to connect a USB wifi module or internal wifi module available for the Jetson Nano.
Motors of the Bot:
So, we have finalized our robot's computer and now let's discuss about the motor to be used in the robot. Before selecting the motor for the bot there are some factors to be taken into account. Those factors includes weight of the bot, power source of the bot and most importantly the speed at which our robot is going to traverse. On considering the mentioned factors, now we'll be selecting the motor for our bot.
- Weight - We can approximately calculate the weight of our bot by calculating the weight of the components used for building the bot. And it is estimated that the weight of the robot approximately ranges between 10-15kg.
- Power source - Battery will be used as the power source of our robot. Power Source Considerations will be discussed finally and for now Battery is the power source of our robot. Since battery is a DC power source, using a DC motor will be best among all the choices of motors. And the motor's operating voltage will be decided while discussing the Power SourceConsiderations.
- Speed - Since we are desigining a UV disinfectant robot, it is necessary that the robot should traverse in a lower speed. Also, a higher torque is needed inorder to pull the entire robot to make it move. So, technically speaking, Torque is inversely proportional to the speed of motor. So we have to choose a DC motor with high torque and less rpm.
From the above factors, it is clear that a DC motor with high torque and less rpm will be the best choice. A DC geared motor is the best suited choice since, the gear box in the DC motor reduces the RPM and increases the torque of the motor. Since we are using a battery as power source, a 12V DC gear motor will be suitable. And while considering the torque and speed character of the motor, a motor with speed ranging from 100-150 rpm and torque ranging from 6-8 kg-cm can be used.
Microcontrollerfor Motor Driver:
Now, we've to select a Microcontroller unit to provide PWM pulses to the motor so that the speed and direction of the motor can be controlled. You may think, what is the need of a microcontroller, when we have number of I/O pins along with PWM pins in the Jetson Nano. Actually, there are some factors in the embedded linux boards thats affects the generation of the PWM. I've faced issues with PWM generation in Jetson nano as well as Raspberry Pi. And after reading number of articles and forums, it is found that, there will be number of threads running in the linux system. And when we add a code that access PWM pins and if the code consists of while loop, some times the script stops executing and the pwm will be generated improperly. This is generally a kernal issue. Since we need the robot to be stable, it's not good to use the PWM pins of nano for the Base Motors. So inorder to avoid this problems and to provide odom data from the encoder to the ROS system we'll be using a microcontrolled unit and I'm choosing Arduino Nano considering its size and compatibility. But any Arduino based MCU can be used.
Motor driver:
Motor driver act as an interface between the motors and the control circuit. Motor require high amount of current whereas the controller circuit works on low current signals. So the function of motor drivers is to take a low-current control signal and then turn it into a higher-current signal that can drive a motor.
Rotary Encoder:
A Rotary Encoder is an electro-mechanical device that converts the angular position or motion of a shaft or axle to analog or digital output signals. We can choose a motor with built-in encoder or we can attach a rotary encoder externally. You may think why need a rotary encoder in our robot. Let me explain it. Since our robot will function with the help of ROS, it is essential to provide the odometry data to the ROS inorder to make the system understand about the movement of robot. So it is essential to provide odom data to achieve stable functioning of the robot.
LaserRangefinder:
A laser rangefinder is a kind of sensor which uses a laser beam to calculate distance of an object. Since the robot needs to be navigate autonomously, a rangefinder is essential for the SLAM, autonomous navigation and obstacle avoidance of our robot. There are number of laser rangefinders available in the market. We can use any Rangefinders. And here, we'll be choosing the RPLIDAR A1, considering its cost, efficiency and its compatibility with ROS(Robot Operating System). We'll discuss about ROS in software specifications section, since ROS will be used in our robot.
PIR Sensor:
While considerng about the safety system of our bot, it is essential to use a sensor to detect the presence of living being in order to avoid any threat to the living beings. A PIR sensor can be used to do the job.
Buzzer:
Also, when considering the safety factors it is important to notify the persons about the status of the UV light in the bot, and for that a buzzer can be added to the bot. A buzzer is a small electronic device that produces sound when energized. So, to indiate the status of UV light we can use a buzzer to create a beep sound periodically so the people can be aware of the UV light. A 5v buzzer can be selected to attach it with the bot.
Camera:
Another safety measure that can be added to the robot is camera. Yes, a camera can be used for the vision of bot with the help of OpenCV library. And deploying some ML and DL algorithms it is possible to detect the humans as well as objects. With the help of computer vision we can identify doors, handles and other high touch surfaces for preferential sanitation order to improve efficiency and effectiveness of the disinfection of the bot. Also to add the night vision feature to our bot, it is important to use a camera that is capable of night vision. And it is found that Pi NoIR Camera V2 will be the best option, considering its cost, compatibility with the Jetson Nano.
Servo Motor:
Since a camera will be used for the vision of the bot, it necessary the the robot should see the entire area and not only a particular area. So to make it possible a servo motor is needed. The camera will be mounted on top of the servo motor and made to rotate in step upto an angle of 360 degree, so that it is possible for the camera to cover the entire place. Since we need 360 degree rotation, a 360 degree servo motor with lesser torque can be selected, since the camera has lesser weight, lesser torque motor can be considered.
LEDs:
This is also one of the safety considerations of the robot. Now, consider the UV light in the bot is on and the buzzer gives alarm, eventhough if the person fails to understand that warning, a warning is visually needed inorder to ensure the people safety. Also, LEDs can be used indicate the power status of the robot.
UV Light Sensor:
The most important safety consideration for the robot is UV Light Sensor. The sensor is essential inorder to ensure safety at the time of any fault in the relay or in UV light system. In case, the any fault occurs and the light is not in the control of the person or the bot. The UV sensor detects the UV ray and then shutdown the entire bot in case of emergency or fault. Generally UV sensors are designed to detect UVA and UVB light rays. So it is essential to calibrate the sensor to work with UVC light rays. We've to measure the analog reading of the sensor with the help of datasheet since the wavelength of the UVA, UVB and UVC differs.
Microphone:
To add some additional feature to the bot, I'm plannig to integrate voice control feature in the robot so that it is easier for the user to control the robot with voice commands. A USB microphone is needed to receive the voice signals. A good quality microphone can be used in the robot.
Relays:
A electromechanical switch is to be added in the robot, so that the robot can turn the UV lights ON and OFF. So to achieve this function, relays are used. A relay is an electromechanical device or switch that gets activated when energized.
UV Light/Lamp:
UVC Light/Lamp will be used in the robot for disinfection. There are some factors to be considered while selecting UVC lamp for the robot. The factors includes power rating of lamp, UVC Radiating power of the lamp, dimensions of the lamp, Life of the lamp etc,. The above mentioned factors are needed to calculate and determine the Light/Lamp's UVC dose on virus. I have tried using the UV dose claculator provided for reference. A UV meter is required to calculate the UV intensity of the light source. Since I'm documenting only the design specifications and not making a real time robot, I'm unable to provide the light intensity data. But in the future, after building the bot, complete specifications of the UV light will be provided. But for my design, a 4 feet lamp in 4 numbers and a 8 inch lamp in 1 numbers will be required. For now i'm considering the specs of the Philips TUV 75W HO 1SL/6 T8. The spec is available here. And after reading lot of reasearch papers regardibg the dosage, It is clear that 27 J/m2 Dosage is required to kill COVID19 virus and hence the code will be written in according to Dosage time to turn on and off of uv lights and to traverse after completely sanitizing the regions.
The most important factor to be considered while designing a robot is the power source of the robot. After some researches I came to a conclusion that battery is the best power source for our UV robot. Since we're designing a mobile robot we cannot rely on a plug socket power source which requires long wires and maintenance of those wire. Thus usage of a battery power source eliminates the cost and maintenance of those long wires. But, what type of battery is suitable for the robot? For that also several researches has been conducted and it is found that lithium ion battery is the suitable battery power source for the robot, considering it's efficiency, life cycle, lower maintenance cost, and most importantly lesser weight. That's great we have finalised the power source. But what are the required battery speifications? So, according to the hardwares chosen above we'll be calculating the power requirements of the robot, so that we can select the battery. From the BOM it is clear that the bot will require a with nearly a 12V 25AhLithium IonBattery. Now, to power the UV lamps we need AC source. So an inverter is needed to power the UV lamps. Since the lamps are of 36W and 5 numbers of light is to be used, an inverter with a power output of 500W will be the best choice to handle the UV lamps. That's great and now we need 2 DC - DC power converters one to provide 5V 4A to Jetson Nano and another to provide 12V 2A to the base Motor Driver.
So, we have completed discussing about the components of the robot and it is essential to fit all the components in our robot. For that we need a skeleton of our robot i.e. the mechanical structure of our robot. After a long struggling, the design of the bot "Aurora" is finalized.
The base of the robot can be made of a ply wood sheet of thickness about 8mm so that the base can hold the weight of the entire bot. A castor wheel will be attached in front of the robot. Two wheels will be attached to the motors. The wheels can be 3D printed or can be bought. The entire circuits will be palced or the entire system will be built over the base chasis of the robot. We can reduce the dimensions as much as possible and also since the most of the heavy components are placed below the bot, The centre of gravity will be maintained properly so that there will be no chance for the robot to fall incase of high force.
Upperchasis of the bot:
I'm mentioning the chase or the mechanical design structure as the Upper chasis of the bot. Since the design is compact, the bot can easily traverse into any place. Also due to minimum width and length of the bot the distance between the surface to be sanitized and the bot will be less, which results in quicker and efficient disinfection. The laser scanner will be placed above the front PIR sensor and 4 tube lights are placed on the upper unit, a supporting pipe like structure with reflector will be attached at the centre of the base upper part and at the top most part of the bot camera fitted along with servo motor will be connected. the camera will be kept slightly cross so that it can have a efficient view.
In this section, we'll be discussing about the software considerations and its features which are going to be used in the robot.
NVIDIA JetpackSDK:
NVIDIA Jetpack SDK is specially designed for the Jetson boards for building AI applications. The SDK includes the latest Linux Driver Package (L4T) with Linux operating system and CUDA-X accelerated libraries and APIs for Deep Learning, Computer Vision, Accelerated Computing and Multimedia. The Jetpack SDK is a customized UBUNTU Operating System which has pre-installed packages essintial for AI applications. This SDK will be more helpful for developing our robot. The documentation of the SDK is here. You can download the latest SDK here. You can find the getting started guide here.
Python 3:
The code of Aurora UV robot will be mostly written in python 3 language. Since python 3 is pre-installed in the Jetpack SDK, installing the required python libraries is enough.
Robot Operating System:
The most important software platform for the robot is Robot Operating System (ROS). ROS is collection of software frameworks for robot software development. ROS is not exactly an operating system, altough it provides services designed for a heterogeneous computer cluster such as hardware abstraction, low-level device control, implementation of commonly used functionality, message-passing between processes, and package management. More details about ROS can be found in ros.org also here. Since our bot needs to run autonomously, we need a stable software system to ensure the stability and safety of the robot as well as the safety of humans and ROS is capable of providing a stable operation of the robot. The ROS packages will make it easier to design our bot run autonomously. Thus ROS is chosen as the major software for the robot.
Construction and working of the bot:Since I'm unable make a physical robot, I'm documenting about how "Aurora" can be made. And this documentation consists of sample code of different functions of the robot. So by understanding and then adding all the code together, it is possible to make the the robot work as expected because of the robustness of software and hardware chosen for the robot.
Block Diagram:
The block diagram shows the connection of hardwares inside the Aurora robot. The arrows represents the flow of signal and data.
The above block diagram only shows hardware connections, but it is essential to study the block diagram of Power Source Unit. The diagram is given below:
The bot will have 3 modes of control, they are
- Autonomous
- Smartphone control
- Voice control
Autonomous:
In Autonomous mode, the bot will first scan for the presence of human with the help of camera, then scan the entitre room with laser scanner, creates a map and then plans it path, then it checks all the safety parameters, and sends an acknowledgement signal to the smartphone app as well as the inbuilt notification system in the bot also give signal by turning on the warning leds and buzzer sound, then turn on the UV lamp and the lamp life counter in the starts to calculate the number of hours or time left to replace the UV lamp. The bot traverses along the path created by the robot itself. And sanitizes the regions of the place or room inaccordance with the time required for the whole surface to be disinfected. And once the job gets done the bot sends another acknowledgement then shutdown the UV lights. At the time of sanitation, if any human interrupts then the bot shutdown the lights and gives a beep sound as notification. And in case the battery of the bot is low and needs charging, a Script to notify and then shutdown the Jetson Nano safely must be included inorder to safeguard the bot. This can be achieved by making battery level indicator circuit to produce a digital or analog signal when the battery level is low and reading that signal in Nano to proceed further. Also we can stop or interrupt the robot by voice commands or using mobilephone app.
So to achieve the above mentioned operations, we have to create a ROS program using python, also there will be some other file extensions in which we will work like launch files, ino files etc,. For autonomous navigation, we can use gmapping slam or hector slam, since we provide odometry data to the ROS using the encoders it is best to use Gmapping slam technique. If we don't provide odom data we can go for Hector mapping. Also the bot, at the time of sanitation, creates a log file, which we can access after sanitation to ensure the effect of sanitation. The bot also ensures the proper sanitation of surfaces with the help of camera and OpenCV. We will be using the ROS's Navigation Stack for designing and progamming the bot's autonomous navigation feature.
Smartphone Control:
Now, Consider we want to control our robot manually using a smart phone and for that we need an app. Generally apps for the android platform are built using Java, but we are going to something different and robust. There is a library in Python called Kivy. Kivy is a python framework specially designed for app development for Android, IOS and also for Windows. Since we'll be writing the codes (nearly 95%) in python, it will be easier to develop a client app with UI to interact with our robot. Since ROS will be running a server it is possible to create a ROS client and then wrap into an android app and then using it for the control of robot. We can update the app data periodically by retrieving the data from the ROS server.
Voice Control:
The most important feature of "Aurora" is the voice control feature. Yes, it possible to add voice contol facility to our bot using ROS. Sphinx Speech recognition module will be used for efficient speech recognition. This feature makes the control of bot more easier for the robot.
Design Comparisions:
With the help of provided design criteria, comparing the Aurora with given Criteria.
I've compared Aurora's design with the best design criteria to show you that, Aurora design is unique, roboust, reliable, safe and highly efficient.
Future Developments:- Integrating the voice control in the app itself will be more efficient to control the robot.
- Altering the mechanical design to replace the components easily.
- Planning to design a circuit to reduce wire connections resulting in plug n play the components of bot.
- Training of model using TF to identify highly contacted surfaces.
Hope you'll liked my design. If you have any doubt regarding my design feel free to contact me. Soon I'm planning to built The Aurora. So stay tuned! And I wanna thank Micron for this oppoutunity. Let's work and fight together for a COVID-19 free world !
References: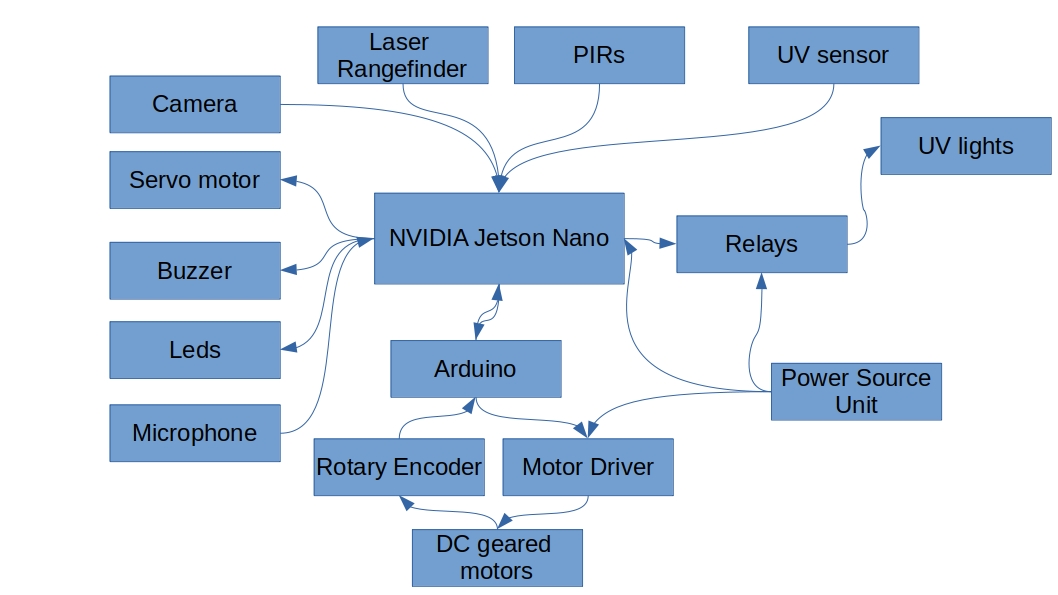






_3u05Tpwasz.png?auto=compress%2Cformat&w=40&h=40&fit=fillmax&bg=fff&dpr=2)
{kind=link}
Comments