


Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
 |
| × | 1 | |||
| × | 1 | ||||
 |
| × | 1 | |||
| × | 1 | ||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
| ||||||
Hand tools and fabrication machines | ||||||
 |
| |||||
 |
| |||||
See what's new at Remyx.ai
Yoga has an ancient tradition of physical and mental training to improve well-being. Modern Hatha Yoga, which emphasizes physical conditioning and mental strength through training physical postures, has been growing in popularity over the last couple decades.
However, the time and cost of getting to a yoga studio can be prohibitive. Still others would prefer to practice outside of the group setting.
Here, we explore the development of YogAI. With pose recognition, we implement a smart assistant to provide corrective advice to guide practitioners.
Our setup is not limited to Yoga flows. We will also explore analysis and feedback for strength training movements.
Gather DataWe'll start by gathering sample images for a few common yoga positions. Doing some image and video search, we build up a corpus of labeled Yoga poses.
You can use this gist to download yoga videos to parse into images or use this plugin while you're running firefox to download google images on poses.
After gathering a couple hundred example images per pose, we group them into directories named for each position.
yoga_poses/
|
|- cow/
| |
| |- sample1.jpg
| |- sample2.jpg
| |- ...
|
|- plank/
| |
| |- sample1.jpg
| |- sample2.jpg
| |- ...
|
.
.We could train an image classifier, like we've done in another project. However, there are deep learning models especially well-suited to pose estimation from images. OpenPose or PoseNet help to localize body key points, offering more information than a simple image classifier.
The TensorFlow lite implementation in this repo can be pointed at your directory to superimpose these keypoints over your images. Here's an example of what the model returns:
We modify a fork to return an array of all the coordinates of each body part found in an image. This array will be the feature vector for a simple ML classifier based on KNN.
See how we label images in the repo to generate a dataset from our samples. We'll regard these annotations as our ground truth for every sample training pose.
Then, our YogAI application will extract key points and classify a yogi's poses in real time to guide instruction.
Pose Estimation & ClassificationWe found that remarkably few samples were required to get decent results. However, more images will help disambiguate similar poses.
For example, we found that the chaturangadandasana and plank poses are very similar but with enough samples the model can differentiate between the two relatively well.
We also found that performance degrades for positions featuring face occlusion like downward dog or forward bend.
Blocked faces can make it difficult for the pose estimator to find other body parts. Since we use the keypoints as a feature vector for our pose classifier, pose detection degrades as well.
To illustrate, consider the downward dog position, where the head is tucked between the shoulders and our photo frames the head blocked by the arms.
On average, analyzing positions like warrior_2, we find the majority of possible keypoints. Comparing with positions like forward_bend, we find 2 keypoints on average across hundreds of samples!
For now, we'll remove these difficult samples.
It is also important to balance the distribution of class samples in our dataset.
Initially, our model overpredicted the warrior_2 position, which was oversampled. Removing the poses that had too few samples or gathering more samples for under-represented poses will help your classifier differentiate between poses better.
Below, we show the confusion matrices for training our pose classifier under two setups. One with imbalanced data across a more challenging range of positions on the left. The second matrix indicates a stronger concentration along the main diagonal, exactly what we are looking for to improve the classifier.
Note the confusion in the lower corner 3x3 block of the right image. These are the warrior_1, warrior_2, warrior_3 pose variants. Label 0 and 3 correspond to the 'plank-like' poses depicted above.
We'd like to use what we know about human bodies to improve the keypoint detection. For instance, we do not expect an entire limb to disappear between frames.
Also, KNN is very simple, basically computing distance between vectors and assigning labels to unknown samples by using the label of nearby samples. But distance in high dimensions gets a bit weird (consequence of the curse of dimensionality). To overcome this, we'd like to learn which dimensions are more important for differentiating poses.
To exploit the bias in how Yoga poses will be framed, we can use a tree-based model like we did here. Gradient Boosting will build decision trees which help us take advantage of the fact that some positions will feature the head held high in the frame, for example.
Note that any small translations of the original images would result in the same translation of key points, while representing the same figure. And so we augmented the roughly three thousand original yoga pose samples by generating random shifts in the x and y directions, flipping on the vertical axis, and incorporated slight rotations on the resulting pose feature vector.
This helps our model to avoid overfitting to a limited sample size. Since we augment the pose vectors instead of the original images, we save a lot of time computing pose estimations. We have a couple simple functions to implement these geometric transforms:
#!/usr/bin/env python3
import pandas as pd
import numpy as np
import random
#Reading poses
df = pd.read_csv('./data/yoga/poses.csv', header=None)
x_coords = np.array([1,0] * 14, dtype=np.int32) # get x coordinates only
y_coords = np.flip(x_coords, axis=0) # get y coordinates only
def rand_shift(vec, v):
return vec + v * np.random.randint(-10, 10)
def vert_swap(vec, N=96):
def col_swap(col):
return (N - col) % 96
return (vec * x_coords) + apply_vec(col_swap, (vec * y_coords))
@np.vectorize
def apply_vec(f,x):
return f(x)
out_lst = []
for row in range(df.shape[0]):
x, y= df.iloc[row, :-1], df.iloc[row,-1]
for idx in range(5):
v = random.choice([x_coords, y_coords]) #randomly choose an index to shift
vec = rand_shift(x, v)
out_lst.append(list(vec) + [y])
#Vertical flip
v_vec = vert_swap(x)
out_lst.append(list(v_vec) + [y])
out_df = pd.DataFrame(out_lst)
out_df.to_csv('./data/yoga/augmented_poses.csv')This blew up our dataset to roughly 35,000 samples, which also increased our simple tree-based classifier accuracy from 57% to 85%.
We found the raspberry pi 3 to run inference at 1 frame every 4-5 seconds. In our demo, the stream lags by roughly 15 seconds.
Almost too slow for yoga, and definitely needs better performance before we can analyze faster movements.
Speeding up Inference
We started researching ways others have pulled off faster pose estimation. Searching for 'pose estimation mobile,' we found some work using the chainer framework with 10 FPS. Then we found work using tf-lite based on convolutional pose machines (CPM). Installing tf-lite was easy with these prebuilt binaries.
The output of the CPMs is shaped like (1, 96, 96, 14). Each slice along the last dimension is a belief map corresponding to one of 14 body key points. Finding the argmax, we can get back x, y coordinates for our key point and built up a 28 feature vector for our pose classifier stage, similar to before. All of this takes place at roughly 3 FPS, great for yoga flows!
The YogAI ApplicationOur virtual instructor will be design to:
- Guide the user through a Yoga workout
- Check current pose from the student
- If the pose is not correct, give some advice
At each instance, we'll extract body keypoints with pose detection to get the current student's body configuration.
Then, we'll check if the student's is executing the correct pose by running the resulting feature vector through an XGBoost model to classify our poses.
We'll offer helpful advice through a conversational interface until they are executing the pose correctly.
Finally, we'll guide the practitioner on to the next pose in the yoga session until completion.
Run the jupyter notebook included in the repo to see train and save the pose classifier. It'll pickle (save) the model to a file named yoga_poses.sav.
You want to train the XGBoost model directly on the raspberry pi to avoid issues arising from compiling with a processor using a different architecture. Takes a couple minutes on a few thousand samples.
To guide the yogi, we've included a script for the virtual trainer to read while it checks the yogi's poses. The trainer will playback the correct soundbite advice for each move.
To generate a new random yoga flow, YogAI uses information parsed from resources like yogajournal. Then we can present sanskrit/common english names and generate random sequences by sampling from some distribution over the pose types.
Setting Up the HardwareThe hardware for this project is super simple. Grab your raspberry pi 3 and attach your webcam via usb. Also hook it up to your display and speakers so YogAI can guide you through a flow.
If you are using a picam, make sure to enable it through raspi-config: sudo raspi-config .
To start, we've used a regular monitor to experiment with our pose classifier. Since people like using mirrors when they are exercising, we think a smart mirror would be a great way to present YogAI.
We are exploring different ways to DIY a smart mirror. We've tried attaching a large plexiglass sheet with a mirror window film, as well as, simply adding the film straight to the monitor. The quality of the reflection was a bit lacking so we got a 2X3 ft one way mirror and built a wood frame around it.
And we used some fencing material to make a decorative facade.
We can see YogAI supporting your training with wall mirrors in commercial gyms.
Adding a Voice AssistantInteracting through a flow of exercises, voice can be a convenient user interface. We learned about snips.ai for implementing an voice assistant and found it easy to dive into. Follow this get started tutorial to set up your pi and account. In the console you'll be able to create your assistant. We named ours YogAI and created an app called class.
The app has 4 intents: begin, stop, pause, and resume. This will make it easy for the user to control a yoga session.
Each intent needs plenty of command examples to be able to differentiate between the intents - for us this took about 30 samples for each. Use a dictionary to find synonyms and think about common colloquialisms to generalize the command.
We are planning for our snips application to pass simple messages with MQTT. Then our YogAI application will listen for and parse to render the correct view or voice response using flite.
After downloading the snips package, we set our own hotword/wakeword and we have a voice assistant which never transmits data off the device.
Customizing an Avatar
Visualization is a powerful method to improve sports performance. Imagining yourself performing a challenging move can help in your success.
We are interested in applying 'do as I do' motion transfer to generate a realistic avatar for YogAI users performing athletic maneuvers.
A smart mirror is well-positioned to gather these sort of images. Our pose estimation model can extract body key points from reference images.
Then we train a pix2pix model to transfigure the pose frame into a realistic rendition. By doing this, we'll learn to render an avatar from any pose frame we desire.
We will have a library of pose frames transitioning through yoga moves by expert yogis. That way, we can present the user with a visualization of themselves moving as an expert yogi would.
As we experiment here, we run into some interesting failure modes. Consider the following example:
Here our shadow was mistaken for another human in the shot and keypoints were rendered leading the pix2pix model to show a backup dancer.
We should apply some logic to remove the apparition by comparing to previous frames or discard those with more than one set of key points.
Here, we see why the authors of the motion transfer 'EveryBody Dance Now' paper apply spatio-temporal smoothing. The key points in the figure to the left are much more jittery than they should be from the motion performed in the right.
Not a problem here since we are simply learning to 'stylize' the stick figures into a realistic avatar of the user. But when we estimate pose for a reference video performed by an expert yogi, we would like a more fluid rendition in time.
We'd like to average key point positions over a small, sliding time window to stabilize the pose frame and smooth out the rendition of our avatar.
We want to test this idea in a challenging real-world setting without too many assumptions on things like the complexity of the background, the fit and pattern of clothing, or quality of lighting.
We found a great repo that reproduced the Everybody Dance Now results using pytorch. We were able to use a short clip from the "That's what I like" music video by Bruno Mars as a source. We found that filming our target video close to the perspective of the source and using a simple background helps improve the motion transfer. Here is a clip of one of our experiments:
Some further smoothing and longer training could improve the results. We believe that this could be adapted to transfer yoga flows onto a target video. We found that transferring a yoga flow video to a target video of motion not too similar to the source resulted in a poor transfer:
Filming a target video that closely resembles the yoga flow source video will most likely improve the results. More on that coming soon!
Classifying MotionsWe want to use more information over time to improve the pose estimation, which will improve our pose classification. At the same time, we can try to generalize our pose classifier to classify athletic motions like a body squat.
To test this idea, we download a youtube video of a fitness athlete performing many consecutive squat repetitions.
We use ffmpeg to split the video into images at 30 fps. Then we run the images through our pose estimation model to extract keypoints.
These were loaded into a pandas dataframe so we could generate plots. We experiment with simple time smoothing by performing a rolling median over 3 consecutive frames to reduce key point jitter.
This was done after filling missing keypoints with values from the previous frame, imputing with the last known position. However, to more closely match image sampling rates with our rate of inference, we found keypoints can move too much over successive frames.
Here is an example gif after performing keypoint annotation on every 15th frame where an athlete performs the squat. This offers a peek at what we might expect to extract from a camera feed given typical pose estimation inference performance.
We plot the head height in time to get a sense of the timing of the movement.
We expect to be able to perform at least 2 pose estimations per second on a device like the raspberry pi 3. Judging by the gif and time series above, this appears to suffice in detecting the movement.
We will experiment in models which ingest 2 or 3 consecutive pose vectors to detect squats to increment the count for users performing this maneuver in front of YogAI.
For comparison, we consider another similar body move, the deadlift. If we can differentiate between similar motions with different posture our monitor/counter could do some useful things.
We download another youtube video with a strength trainer performing numerous deadlifts with free weights. We extract the poses while imputing and smoothing out the key point coordinates with the rolling median as we did for squats above. The motion sampled at 2 fps would look something like:
This performance featured a longer pause in head position at the top and bottom of the positions.
If we can differentiate these two moves pretty reliably, then we will at least have a new application for our smart mirror: LegDay! A game to track your counts of deadlift and squat maneuvers over time and share your stats.
We also included a third class where the subject of a video was standing. We concatenated the pose feature vectors over consecutive time steps for a tree based model. This initial attempt seemed to work well in counting deadlifts but confused standing with squatting too often.
Next, we tried an LSTM model to read sequences of 3 consecutive pose vectors to classify into one of 'stand', 'squat', 'deadlift' categories. This model did well counting squats but often confused deadlift and standing.
At this point, we could filter out phases of the squat or deadlift where the position is essentially standing from the training data by dropping frames where the head position is high. However, we'd prefer to allow the model to learn from minimally processed video and instead opt for a longer time window for more context.
We increase our rolling buffer to track the most recent pose vectors for the last 5 time steps. Then our LSTM takes a 28x5 input array to classify the move into stand/squat/deadlift maneuvers.
With the additional context of pose estimates in time, this model did well differentiating between the three motions. Now that we can measure when the user is standing, we can encourage jumping back in. Likewise, we have a measure of leg workout intensity which we can split by muscle groups: quad vs. hamstring dominant.
It's natural to test a simple Keras fully connected network to classify poses from the keypoint feature extraction instead of the gradient boosting machines we used above. However, for the limited samples, we've found the tree based models to work best.
This can change as we gather more sample images. One simple idea is to save an image or the extracted keypoints when the YogAI application dictates a yoga pose and confirms with inference.
Furthermore, we can automate workout routines which incorporate user preferences with program design principles from sports science. Measuring additional information such as the heart rate and body temperature, we can explore more general health applications.
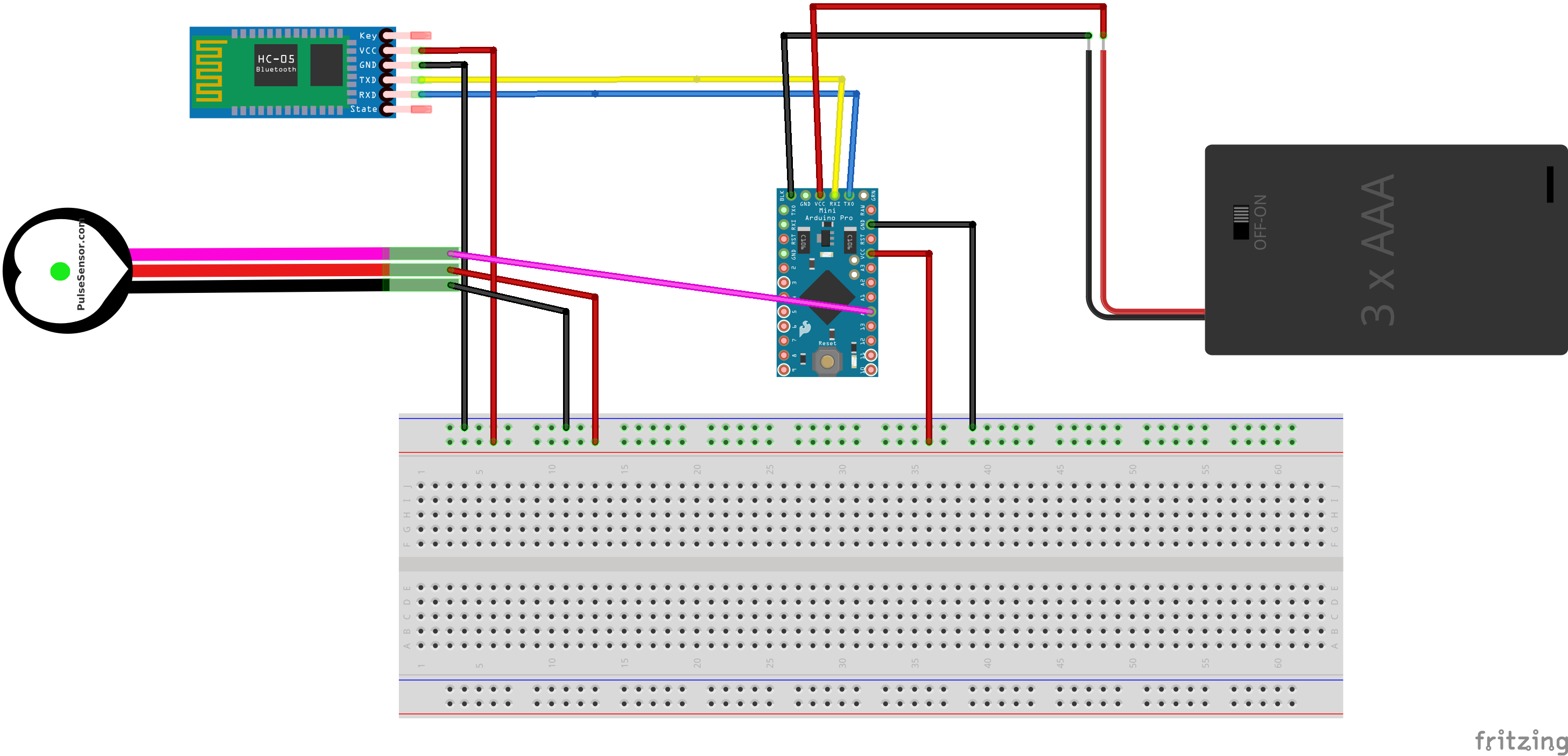
Incorporating Wearables DataBy combining heart rate data from an apple watch or heart rate monitor, we can design workouts to target a specific heart range. Incorporating some domain knowledge on exercise intensity, we can dial things back for recovery or take it up a notch to support an athletic peak. Here is a schematic on building a simple Bluetooth heart rate monitor to pair with YogAI using an Arduino and Bluetooth module:
Our prototype wearable uses a BlueBean (sadly discontinued now), which includes an accelerometer. This will likely be helpful information for movement and pose classification.











{kind=link}
Comments