

Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
Hand tools and fabrication machines | ||||||
 |
| |||||
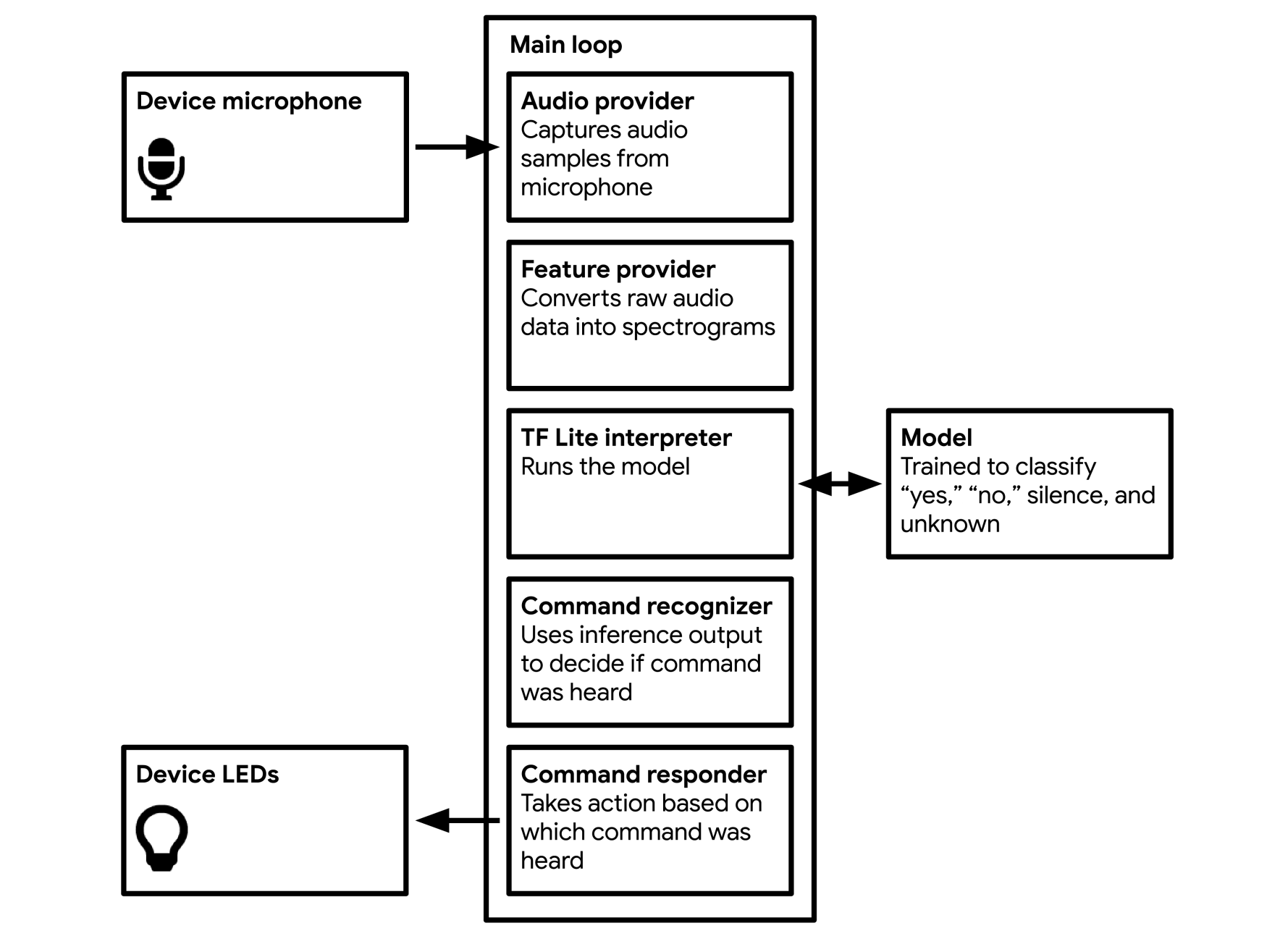
In this project, we built an embedded application that uses an 18KB model, trained on a dataset of speech commands, to classify spoken audio. The model is trained with TensorFlow Lite to recognize "Stop" and "Go". The application will listen to its surroundings with a microphone and indicate when it has detected a word by lighting an LED.
General Structure
The structure of the project will be similar with the example "wake-word detection" given in previous sections. I first gather audio data as input and preprocess the input to extract features suitable to feed into a model. Then I can run inference on the processed input, and then pass the information to the wake-word detection model we've trained, and then process the results. The project is designed to recognize "Stop" and "Go" or none of these words.
Model TrainingDatasets: The dataset called the Speech Commands Dataset consists of 65, 000 one-second long utterances of 30 short words. The application will capture the audio and use the model to distinguish the sound, then take action based on the command it heard.
Training ResultsStep 1: Setting up the microcontroller, downloading support library for BLE 33 nano, select corresponding board and port.
Step 2: Invoke given project code pre-installed from library Arduino_tensorFlow. In detail, the path will be File-> Examples -> TensorFlowLite -> micro_speech
Step 3: In addition to allowing the Arduino board to capture voice, we need the support of the library Arduino_LSM9DS1.
Step 4: Upload the compiled project and test results to the serial monitor. A sample output will be displayed in the video attached below.


{kind=link}
Comments