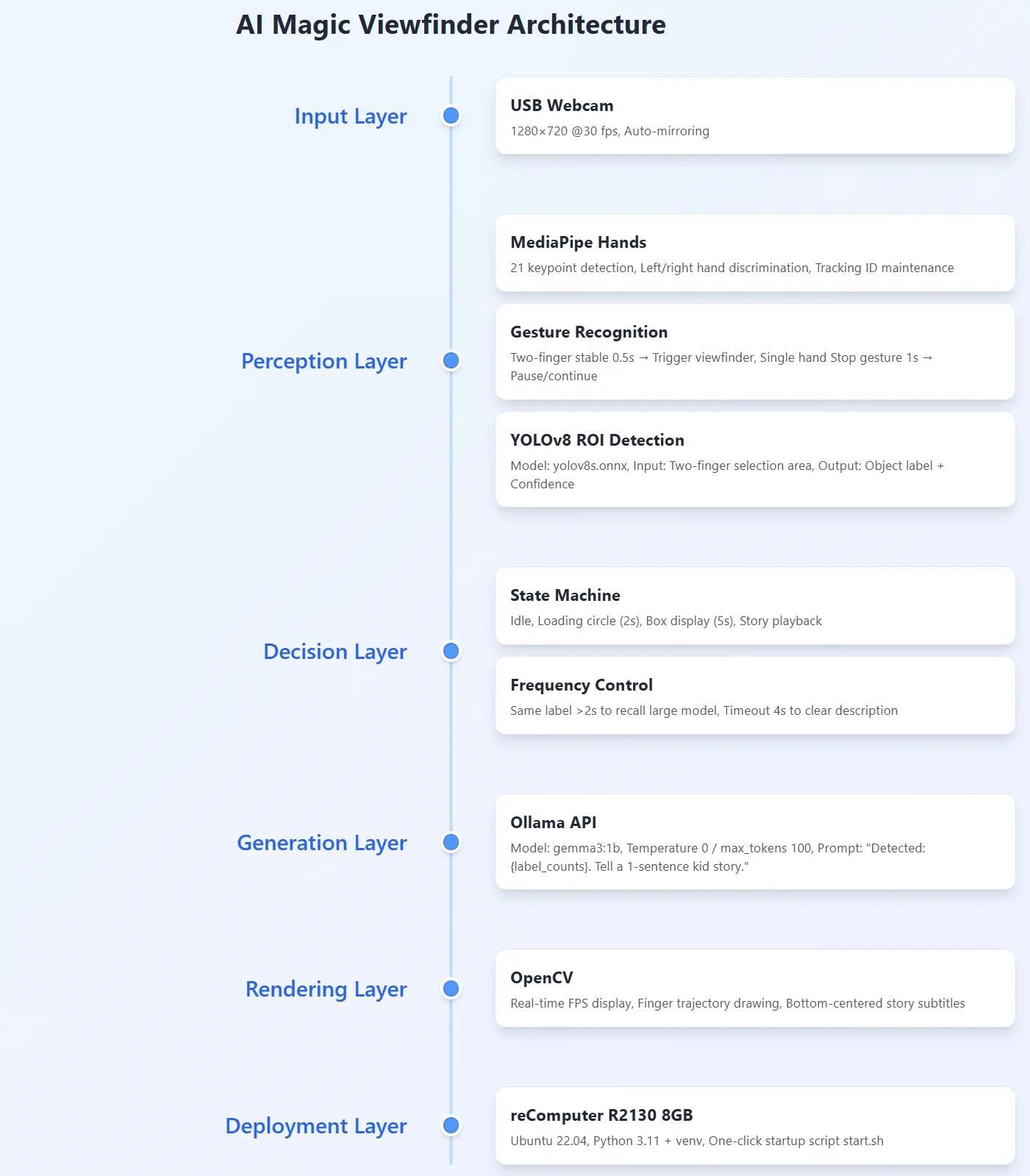
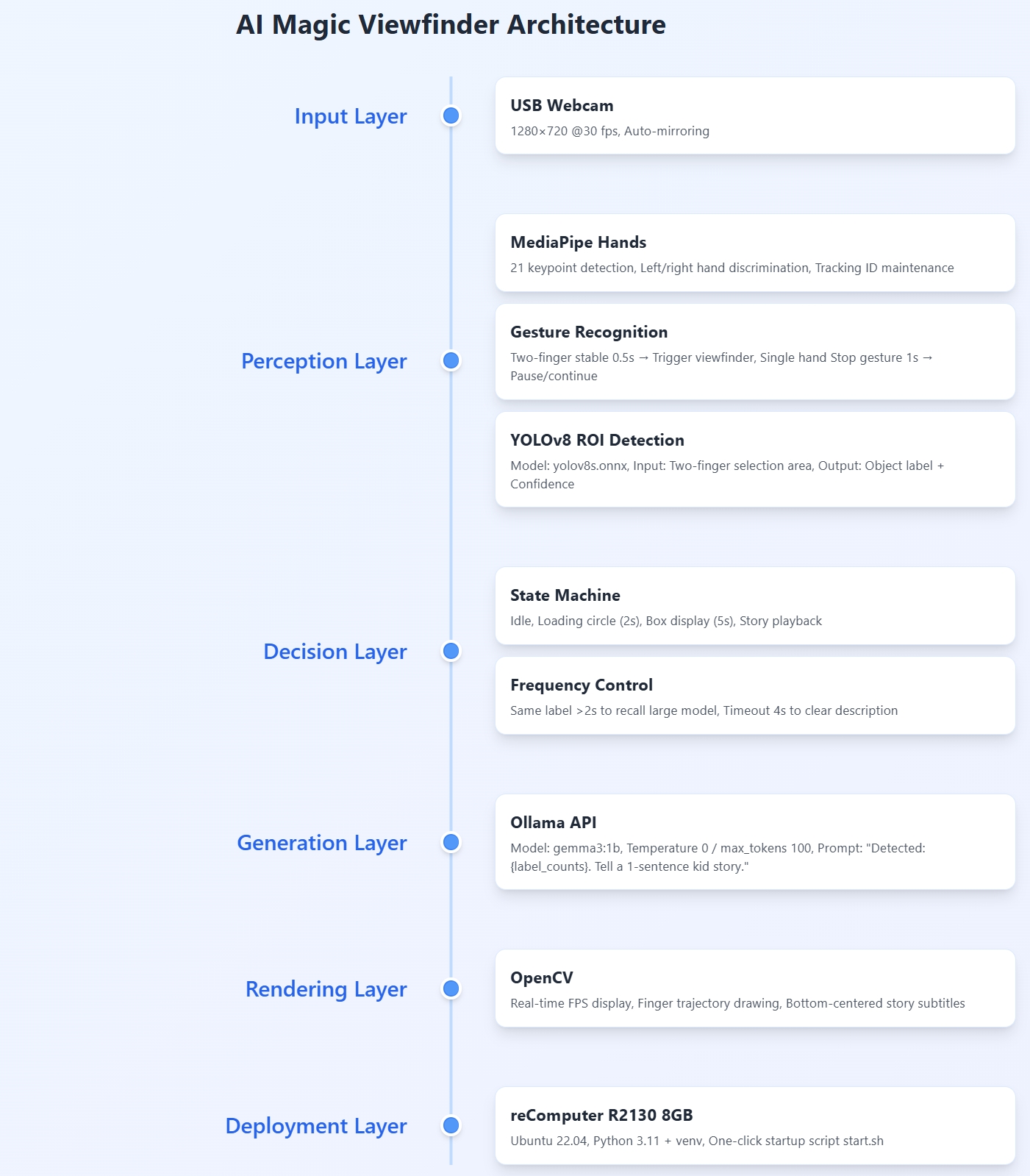
Back in my hometown for the summer, my niece tore around the house clutching a plastic dinosaur. I wanted her to “see” the world those creatures once ruled, so I hacked together a 1000-line core: pinch your index fingers and a red frame blooms on screen; whatever sits inside is named by YOLO, then Ollama spins a Jurassic micro-tale in the next breath. She lined up every toy dinosaur and demanded a story apiece—total chaos, total magic.
2 What it does now
• Two-finger framing: hold both index-finger tips steady for 0.5 s → red viewfinder appears.
• Live recognition: YOLOv8 labels whatever is inside the frame, confidence score included.
• AI narration: only one Ollama call per frame, returning a single-sentence story—no spam, just wonder.
importcsvimportcopyimportargparseimportitertoolsfrommathimportdegreesfromcollectionsimportCounterfromcollectionsimportdequeimportcv2ascvimportnumpyasnpfromutilsimportCvFpsCalcfromutils.utilsimportrotate_and_crop_rectanglefrommodelimportPalmDetectionfrommodelimportHandLandmarkfrommodelimportKeyPointClassifierfrommodelimportPointHistoryClassifierfromultralyticsimportYOLO# Import YOLOv8 modelimporttimeimportrequests# New: used to call Ollama API# Global variablesstop_gesture_start_time=0stop_gesture_active=Falsestop_gesture_duration=1# Duration threshold (seconds)label_counts=Counter()# Count label occurrences# LLM-related variablesdescription_text=""# Store LLM-generated descriptionlast_description_time=0# Last time description was generateddescription_interval=2# Interval between calls (seconds)prev_label_counts=Counter()# Record previous label countsdescription_expire_time=0# Expiration time for descriptiondescription_keep_duration=4# Extra time to keep description after box disappearsdefget_args():parser=argparse.ArgumentParser()parser.add_argument('-d','--device',type=int,default=0,)parser.add_argument('-im','--image',type=str,default='',)parser.add_argument('-wi','--width',help='Frame width',type=int,default=1280,)parser.add_argument('-he','--height',help='Frame height',type=int,default=720,)parser.add_argument('-mdc','--min_detection_confidence',help='Minimum detection confidence',type=float,default=0.6,)parser.add_argument('-dif','--disable_image_flip',help='Disable image flipping',action='store_true',)args=parser.parse_args()returnargsdefmain():globalprev_label_countsglobalstop_gesture_start_time,stop_gesture_active,stop_gesture_durationgloballabel_counts,description_text,last_description_time,description_interval,prev_label_countsargs=get_args()# Video source fixed to specified filevideo_path=r"C:\Users\seeed\Pictures\Camera Roll\WIN_20250718_17_10_40_Pro.mp4"cap_device=0cap_width=args.widthcap_height=args.heightmin_detection_confidence=args.min_detection_confidencelines_hand=[[0,1],[1,2],[2,3],[3,4],[0,5],[5,6],[6,7],[7,8],[5,9],[9,10],[10,11],[11,12],[9,13],[13,14],[14,15],[15,16],[13,17],[17,18],[18,19],[19,20],[0,17],]# Video capture setup #######################################################cap=cv.VideoCapture(cap_device)cap.set(cv.CAP_PROP_FRAME_WIDTH,cap_width)cap.set(cv.CAP_PROP_FRAME_HEIGHT,cap_height)cap_fps=cap.get(cv.CAP_PROP_FPS)fourcc=cv.VideoWriter_fourcc('m','p','4','v')video_writer=cv.VideoWriter(filename='output.mp4',fourcc=fourcc,fps=cap_fps,frameSize=(cap_width,cap_height),)# Model loading #############################################################palm_detection=PalmDetection(score_threshold=min_detection_confidence)hand_landmark=HandLandmark()keypoint_classifier=KeyPointClassifier()point_history_classifier=PointHistoryClassifier()# Load YOLOv8 model #########################################################object_detection_model=YOLO("./yolo_model/yolov8s.onnx")# Label loading #############################################################withopen('model/keypoint_classifier/keypoint_classifier_label.csv',encoding='utf-8-sig',)asf:keypoint_classifier_labels=csv.reader(f)keypoint_classifier_labels=[row[0]forrowinkeypoint_classifier_labels]withopen('model/point_history_classifier/point_history_classifier_label.csv',encoding='utf-8-sig',)asf:point_history_classifier_labels=csv.reader(f)point_history_classifier_labels=[row[0]forrowinpoint_history_classifier_labels]# FPS calculation module ####################################################cvFpsCalc=CvFpsCalc(buffer_len=10)# Coordinate history ########################################################history_length=16point_history={}pre_point_history={}# Gesture history ###########################################################gesture_history_length=10finger_gesture_history={}# Palm tracking #############################################################palm_trackid_cxcy={}# Loading circle and box variablesindex_finger_tip_positions={}loading_circle_start_time=0loading_circle_active=Falseloading_circle_duration=2box_start_time=0box_active=Falsebox_duration=5locked_box_position=Nonedetected_stops=set()# Object detection variablesobject_detection_active=Falsedetection_results=[]mode=0wh_ratio=cap_width/cap_heightauto=Falseprev_number=-1image=Nonetotal_frames=0begin=time.time()whileTrue:fps=cvFpsCalc.get()total_frames+=1# Keyboard handling (ESC to quit) #########################################key=cv.waitKey(1)ifkey==27:# ESCbreaknumber,mode,auto,prev_number=select_mode(key,mode,auto,prev_number)# Frame capture ###########################################################ret,image=cap.read()ifnotret:breakimage=imageifargs.disable_image_flipelsecv.flip(image,1)debug_image=copy.deepcopy(image)# Detection ################################################################ Palm detection ##########################################################hands=palm_detection(image)rects=[]not_rotate_rects=[]rects_tuple=Nonecropted_rotated_hands_images=[]iflen(hands)==0:palm_trackid_cxcy={}detected_stops=set()object_detection_active=Falsedetection_results=[]palm_trackid_box_x1y1s={}iflen(hands)>0:forhandinhands:sqn_rr_size=hand[0]rotation=hand[1]sqn_rr_center_x=hand[2]sqn_rr_center_y=hand[3]cx=int(sqn_rr_center_x*cap_width)cy=int(sqn_rr_center_y*cap_height)xmin=int((sqn_rr_center_x-(sqn_rr_size/2))*cap_width)xmax=int((sqn_rr_center_x+(sqn_rr_size/2))*cap_width)ymin=int((sqn_rr_center_y-(sqn_rr_size*wh_ratio/2))*cap_height)ymax=int((sqn_rr_center_y+(sqn_rr_size*wh_ratio/2))*cap_height)xmin=max(0,xmin)xmax=min(cap_width,xmax)ymin=max(0,ymin)ymax=min(cap_height,ymax)degree=degrees(rotation)rects.append([cx,cy,(xmax-xmin),(ymax-ymin),degree])rects=np.asarray(rects,dtype=np.float32)cropted_rotated_hands_images=rotate_and_crop_rectangle(image=image,rects_tmp=rects,operation_when_cropping_out_of_range='padding',)# Draw debug info #######################################################forrectinrects:rects_tuple=((rect[0],rect[1]),(rect[2],rect[3]),rect[4])box=cv.boxPoints(rects_tuple).astype(np.intp)cv.drawContours(debug_image,[box],0,(0,0,255),2,cv.LINE_AA)rcx=int(rect[0])rcy=int(rect[1])half_w=int(rect[2]//2)half_h=int(rect[3]//2)x1=rcx-half_wy1=rcy-half_hx2=rcx+half_wy2=rcy+half_htext_x=max(x1,10)text_x=min(text_x,cap_width-120)text_y=max(y1-15,45)text_y=min(text_y,cap_height-20)not_rotate_rects.append([rcx,rcy,x1,y1,x2,y2,0])cv.putText(debug_image,f'{y2-y1}x{x2-x1}',(text_x,text_y),cv.FONT_HERSHEY_SIMPLEX,0.4,(0,0,0),2,cv.LINE_AA,)cv.putText(debug_image,f'{y2-y1}x{x2-x1}',(text_x,text_y),cv.FONT_HERSHEY_SIMPLEX,0.8,(59,255,255),1,cv.LINE_AA,)cv.rectangle(debug_image,(x1,y1),(x2,y2),(0,128,255),2,cv.LINE_AA,)cv.circle(debug_image,(rcx,rcy),3,(0,255,255),-1,)base_point=np.asarray([rcx,rcy],dtype=np.float32)points=np.asarray(list(palm_trackid_cxcy.values()),dtype=np.float32)iflen(points)>0:diff_val=points-base_pointall_points_distance=np.linalg.norm(diff_val,axis=1)nearest_trackid=np.argmin(all_points_distance)nearest_distance=all_points_distance[nearest_trackid]new_trackid=int(nearest_trackid)+1ifnearest_distance>100:new_trackid=next(iter(reversed(palm_trackid_cxcy)))+1ifpalm_trackid_cxcyelse1else:new_trackid=1palm_trackid_cxcy[new_trackid]=[rcx,rcy]palm_trackid_box_x1y1s[new_trackid]=[x1,y1]# Hand landmark detection #################################################iflen(cropted_rotated_hands_images)>0:hand_landmarks,rotated_image_size_leftrights=hand_landmark(images=cropted_rotated_hands_images,rects=rects,)iflen(hand_landmarks)>0:pre_processed_landmarks=[]pre_processed_point_histories=[]for(trackid,x1y1),landmark,rotated_image_size_leftright,not_rotate_rectin \
zip(palm_trackid_box_x1y1s.items(),hand_landmarks,rotated_image_size_leftrights,not_rotate_rects):x1,y1=x1y1rotated_image_width,_,left_hand_0_or_right_hand_1=rotated_image_size_leftrightthick_coef=rotated_image_width/400lines=np.asarray([np.array([landmark[point]forpointinline]).astype(np.int32)forlineinlines_hand])radius=int(1+thick_coef*5)cv.polylines(debug_image,lines,False,(255,0,0),int(radius),cv.LINE_AA,)_=[cv.circle(debug_image,(int(x),int(y)),radius,(0,128,255),-1)forx,yinlandmark[:,:2]]left_hand_0_or_right_hand_1=left_hand_0_or_right_hand_1ifargs.disable_image_flipelse(1-left_hand_0_or_right_hand_1)handedness='Left 'ifleft_hand_0_or_right_hand_1==0else'Right'_,_,x1,y1,_,_,_=not_rotate_recttext_x=max(x1,10)text_x=min(text_x,cap_width-120)text_y=max(y1-70,20)text_y=min(text_y,cap_height-70)hand_info=f'trackid:{trackid}{handedness}'cv.putText(debug_image,hand_info,(text_x,text_y),cv.FONT_HERSHEY_SIMPLEX,0.8,(0,0,0),2,cv.LINE_AA,)cv.putText(debug_image,hand_info,(text_x,text_y),cv.FONT_HERSHEY_SIMPLEX,0.8,(59,255,255),1,cv.LINE_AA,)pre_processed_landmark=pre_process_landmark(landmark)pre_processed_landmarks.append(pre_processed_landmark)pre_processed_point_histories=pre_process_point_history(image_width=debug_image.shape[1],image_height=debug_image.shape[0],point_history=point_history,)logging_csv(number,mode,trackid,pre_processed_landmark,pre_processed_point_histories,)hand_sign_ids=keypoint_classifier(np.asarray(pre_processed_landmarks,dtype=np.float32))for(trackid,x1y1),landmark,hand_sign_idinzip(palm_trackid_box_x1y1s.items(),hand_landmarks,hand_sign_ids):x1,y1=x1y1point_history.setdefault(trackid,deque(maxlen=history_length))index_finger_tip=landmark[8]current_time=time.time()ifhand_sign_id==3:detected_stops.add(trackid)else:detected_stops.discard(trackid)iftrackidnotinindex_finger_tip_positions:index_finger_tip_positions[trackid]={'position':index_finger_tip,'time':current_time,'stable':False,'stable_start_time':current_time}else:prev_position=index_finger_tip_positions[trackid]['position']move_distance=np.linalg.norm(np.array(index_finger_tip)-np.array(prev_position))index_finger_tip_positions[trackid]['position']=index_finger_tipifmove_distance<10:ifnotindex_finger_tip_positions[trackid]['stable']:index_finger_tip_positions[trackid]['stable']=Trueindex_finger_tip_positions[trackid]['stable_start_time']=current_timeelse:index_finger_tip_positions[trackid]['stable']=Falsehand_sign_text=keypoint_classifier_labels[hand_sign_id]label_x=x1label_y=y1-90label_x=max(label_x,10)label_x=min(label_x,cap_width-120)label_y=max(label_y,20)label_y=min(label_y,cap_height-20)cv.putText(debug_image,f'Gesture: {hand_sign_text}',(label_x,label_y),cv.FONT_HERSHEY_SIMPLEX,0.8,(0,0,0),2,cv.LINE_AA,)cv.putText(debug_image,f'Gesture: {hand_sign_text}',(label_x,label_y),cv.FONT_HERSHEY_SIMPLEX,0.8,(0,255,0),1,cv.LINE_AA,)iflen(pre_point_history)>0:temp_point_history=copy.deepcopy(point_history)fortrack_id,pointsintemp_point_history.items():iftrack_idinpre_point_history:pre_points=pre_point_history[track_id]ifpoints==pre_points:_=point_history.pop(track_id,None)pre_point_history=copy.deepcopy(point_history)finger_gesture_ids=Nonetemp_trackid_x1y1s={}temp_pre_processed_point_history=[]for(trackid,x1y1),pre_processed_point_historyinzip(palm_trackid_box_x1y1s.items(),pre_processed_point_histories):point_history_len=len(pre_processed_point_history)ifpoint_history_len>0andpoint_history_len%(history_length*2)==0:temp_trackid_x1y1s[trackid]=x1y1temp_pre_processed_point_history.append(pre_processed_point_history)iflen(temp_pre_processed_point_history)>0:finger_gesture_ids=point_history_classifier(temp_pre_processed_point_history,)iffinger_gesture_idsisnotNone:for(trackid,x1y1),finger_gesture_idinzip(temp_trackid_x1y1s.items(),finger_gesture_ids):x1,y1=x1y1trackid_str=str(trackid)finger_gesture_history.setdefault(trackid_str,deque(maxlen=gesture_history_length))finger_gesture_history[trackid_str].append(int(finger_gesture_id))most_common_fg_id=Counter(finger_gesture_history[trackid_str]).most_common()text_x=max(x1,10)text_x=min(text_x,cap_width-120)text_y=max(y1-45,20)text_y=min(text_y,cap_height-45)classifier_label=point_history_classifier_labels[most_common_fg_id[0][0]]cv.putText(debug_image,f'Finger Gesture: {classifier_label}',(text_x,text_y),cv.FONT_HERSHEY_SIMPLEX,0.7,(0,0,0),2,cv.LINE_AA,)cv.putText(debug_image,f'Finger Gesture: {classifier_label}',(text_x,text_y),cv.FONT_HERSHEY_SIMPLEX,0.7,(255,165,0),1,cv.LINE_AA,)else:point_history={}index_finger_tip_positions={}detected_stops=set()object_detection_active=Falsedetection_results=[]else:point_history={}index_finger_tip_positions={}detected_stops=set()object_detection_active=Falsedetection_results=[]stable_fingers=[trackidfortrackid,datainindex_finger_tip_positions.items()ifdata['stable']andtime.time()-data['stable_start_time']>=0.5]current_time=time.time()iflen(stable_fingers)>=2andnotloading_circle_activeandnotbox_active:loading_circle_active=Trueloading_circle_start_time=current_timebox_active=Falselocked_box_position=Noneobject_detection_active=Falseifloading_circle_active:elapsed_time=current_time-loading_circle_start_timeifelapsed_time<loading_circle_duration:progress=elapsed_time/loading_circle_durationfortrackidinstable_fingers:index_finger_tip=index_finger_tip_positions[trackid]['position']center=(int(index_finger_tip[0]),int(index_finger_tip[1]))radius=30start_angle=0end_angle=int(360*progress)cv.ellipse(debug_image,center,(radius,radius),0,start_angle,end_angle,(0,255,0),2)cv.putText(debug_image,f'Loading: {int(progress*100)}%',(center[0]-30,center[1]-40),cv.FONT_HERSHEY_SIMPLEX,0.6,(0,255,0),1,cv.LINE_AA,)else:loading_circle_active=Falseiflen(stable_fingers)>=2:index_finger_tip1=index_finger_tip_positions[stable_fingers[0]]['position']index_finger_tip2=index_finger_tip_positions[stable_fingers[1]]['position']x_min=min(index_finger_tip1[0],index_finger_tip2[0])y_min=min(index_finger_tip1[1],index_finger_tip2[1])x_max=max(index_finger_tip1[0],index_finger_tip2[0])y_max=max(index_finger_tip1[1],index_finger_tip2[1])margin=10x_min=max(0,x_min-margin)y_min=max(0,y_min-margin)x_max=min(cap_width,x_max+margin)y_max=min(cap_height,y_max+margin)locked_box_position=(x_min,y_min,x_max,y_max)box_active=Truebox_start_time=current_timeobject_detection_active=Trueifbox_active:elapsed_time=current_time-box_start_timeifelapsed_time<box_duration:iflocked_box_position:x_min,y_min,x_max,y_max=locked_box_positionx_min,y_min,x_max,y_max=int(x_min),int(y_min),int(x_max),int(y_max)cv.rectangle(debug_image,(x_min,y_min),(x_max,y_max),(0,0,255),2)ifobject_detection_active:roi=image[y_min:y_max,x_min:x_max]ifroi.size>0:results=object_detection_model(roi)detection_results=[]forresultinresults:boxes=result.boxesforboxinboxes:x1,y1,x2,y2=box.xyxy[0].cpu().numpy().astype(int)x1_abs,y1_abs=x1+x_min,y1+y_minx2_abs,y2_abs=x2+x_min,y2+y_mincls=int(box.cls)conf=float(box.conf)label=result.names[cls]detection_results.append({'box':(x1_abs,y1_abs,x2_abs,y2_abs),'label':label,'confidence':conf})else:box_active=Falselocked_box_position=Noneobject_detection_active=Falsedetection_results=[]label_counts.clear()forresultindetection_results:label=result['label']label_counts[label]+=1current_time=time.time()if(box_activeorobject_detection_active)andlen(detection_results)>0:if(label_counts!=prev_label_counts)or(current_time-last_description_time>description_interval):objects_description=", ".join([f"{count}{label}"forlabel,countinlabel_counts.items()])prompt=f"""We have detected objects in the image: {objects_description}. For each object, provide: 1. The object name and quantity 2. A very brief one-sentence explanation of what it is Format the response as a single paragraph without bullet points. Use clear and concise language. Do not ask for images."""description_text=call_ollama_api(prompt)last_description_time=current_timeprev_label_counts=copy.deepcopy(label_counts)elifnotbox_activeandnotobject_detection_activeandlen(detection_results)==0:ifdescription_text:description_expire_time=current_time+description_keep_durationforresultindetection_results:box=result['box']label=result['label']confidence=result['confidence']cv.rectangle(debug_image,(box[0],box[1]),(box[2],box[3]),(0,255,0),2)text=f"{label}: {confidence:.2f}"cv.putText(debug_image,text,(box[0],box[1]-10),cv.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),2)debug_image=draw_point_history(debug_image,point_history)debug_image=draw_info(debug_image,fps,mode,number,auto)cv.imshow('Gesture Recognition',debug_image)video_writer.write(debug_image)end=time.time()total_time=end-beginprint("Average FPS:",total_frames/total_time)ifvideo_writer:video_writer.release()ifcap:cap.release()cv.destroyAllWindows()defselect_mode(key,mode,auto=False,prev_number=-1):number=-1if48<=key<=57:number=key-48prev_number=numberifkey==110:mode=0ifkey==107:mode=1ifkey==104:mode=2ifkey==97:auto=notautoifauto:ifprev_number!=-1:number=prev_numberelse:prev_number=-1returnnumber,mode,auto,prev_numberdefpre_process_landmark(landmark_list):iflen(landmark_list)==0:return[]temp_landmark_list=copy.deepcopy(landmark_list)base_x,base_y=temp_landmark_list[0][0],temp_landmark_list[0][1]temp_landmark_list=[[temp_landmark[0]-base_x,temp_landmark[1]-base_y]fortemp_landmarkintemp_landmark_list]temp_landmark_list=list(itertools.chain.from_iterable(temp_landmark_list))max_value=max(list(map(abs,temp_landmark_list)))defnormalize_(n):returnn/max_valuetemp_landmark_list=list(map(normalize_,temp_landmark_list))returntemp_landmark_listdefpre_process_point_history(image_width:int,image_height:int,point_history:dict,):iflen(point_history)==0:return[]temp_point_history=copy.deepcopy(point_history)relative_coordinate_list_by_trackid=[]fortrackid,pointsintemp_point_history.items():ifnotpoints:continuebase_x,base_y=points[0][0],points[0][1]relative_coordinate_list=[[(point[0]-base_x)/image_width,(point[1]-base_y)/image_height,]forpointinpoints]relative_coordinate_list_1d=list(itertools.chain.from_iterable(relative_coordinate_list))relative_coordinate_list_by_trackid.append(relative_coordinate_list_1d)returnrelative_coordinate_list_by_trackiddeflogging_csv(number,mode,trackid,landmark_list,point_histories):ifmode==0:passifmode==1and(0<=number<=9):csv_path='model/keypoint_classifier/keypoint.csv'withopen(csv_path,'a',newline="")asf:writer=csv.writer(f)writer.writerow([number,trackid,*landmark_list])ifmode==2and(0<=number<=9):csv_path='model/point_history_classifier/point_history.csv'withopen(csv_path,'a',newline="")asf:writer=csv.writer(f)forpoint_historyinpoint_histories:writer.writerow([number,trackid,*point_history])defdraw_info(image,fps,mode,number,auto):cv.putText(image,f'FPS:{str(fps)}',(10,30),cv.FONT_HERSHEY_SIMPLEX,1.0,(0,0,0),4,cv.LINE_AA,)cv.putText(image,f'FPS:{str(fps)}',(10,30),cv.FONT_HERSHEY_SIMPLEX,1.0,(255,255,255),2,cv.LINE_AA,)mode_string=['Logging Key Point','Logging Point History']if1<=mode<=2:cv.putText(image,f'MODE:{mode_string[mode-1]}',(10,90),cv.FONT_HERSHEY_SIMPLEX,0.6,(255,255,255),1,cv.LINE_AA,)if0<=number<=9:cv.putText(image,f'NUM:{str(number)}',(10,110),cv.FONT_HERSHEY_SIMPLEX,0.6,(255,255,255),1,cv.LINE_AA,)cv.putText(image,f'AUTO:{str(auto)}',(10,130),cv.FONT_HERSHEY_SIMPLEX,0.6,(255,255,255),1,cv.LINE_AA,)iflen(label_counts)>0:stats_x=image.shape[1]-200stats_y=10stats_width=190stats_height=10+len(label_counts)*30cv.rectangle(image,(stats_x,stats_y),(stats_x+stats_width,stats_y+stats_height),(0,0,0),-1)cv.putText(image,"Detection Statistics:",(stats_x+10,stats_y+25),cv.FONT_HERSHEY_SIMPLEX,0.7,(255,255,255),1,cv.LINE_AA)y_offset=55forlabel,countinlabel_counts.items():text=f"{label}: {count}"cv.putText(image,text,(stats_x+10,stats_y+y_offset),cv.FONT_HERSHEY_SIMPLEX,0.6,(0,255,0),1,cv.LINE_AA)y_offset+=30ifdescription_text:print(f"LLM Output: {description_text}")text_size,_=cv.getTextSize(description_text,cv.FONT_HERSHEY_SIMPLEX,0.8,2)text_x=(image.shape[1]-text_size[0])//2text_y=image.shape[0]-30cv.rectangle(image,(text_x-10,text_y-text_size[1]-10),(text_x+text_size[0]+10,text_y+10),(0,0,0),-1)cv.putText(image,description_text,(text_x,text_y),cv.FONT_HERSHEY_SIMPLEX,0.4,(255,255,0),1,cv.LINE_AA)returnimagedefdraw_point_history(image,point_history):_=[cv.circle(image,(point[0],point[1]),1+int(index/2),(152,251,152),2) \
fortrackid,pointsinpoint_history.items() \
forindex,pointinenumerate(points)ifpoint[0]!=0andpoint[1]!=0]returnimagedefcall_ollama_api(prompt):try:url="http://localhost:11434/api/generate"payload={"model":"gemma3:1b","prompt":prompt,"stream":False,"temperature":0,"max_tokens":100,"stop":["\n"]}response=requests.post(url,json=payload,timeout=5)response.raise_for_status()returnresponse.json()["response"]exceptExceptionase:print(f"LLM call failed: {e}")return"Description generation failed"if__name__=='__main__':main()




{kind=link}
Comments