
No matter if you use the default model or transfer learning, you are only using one image as input. As we know, however, real driver doesn't make decisions based on only what he/she sees at that moment (spatial information). Driver makes decisions based on what they observe in a short period of time (Spatiotemporal information). For steeling angle control, temporal information might not be that important, but for throttle control, temporal information has a big impact on the performance.
By using 2D CNN, we take one image as input for each time. So 2D CNN model can capture spatial information very well, but the model doesn't have the ability to capture temporal information. If we can take a small video(several consecutive images) as input, then we can use 3D CNN algorithm to capture temporal information for our prediction model.
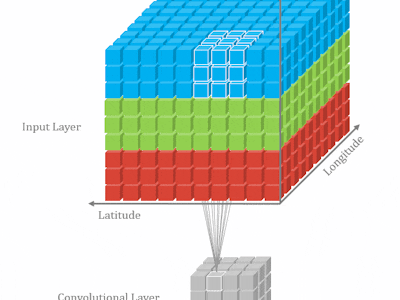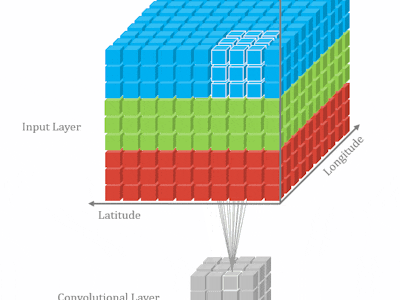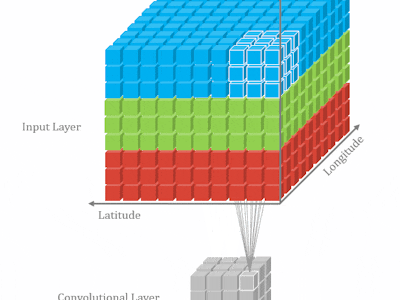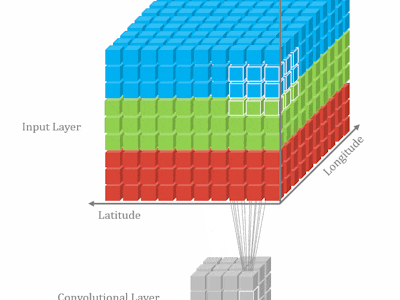
How 3DCNN works3D CNN has been widely used on video classification problem, such as 3D Convolutional Neural Networks for Human Action Recognition etc. Comparing to 2D CNN, 3D CNN provides the ability of capturing temporal information. How does it work? The answer will be very clear when we compare the difference between 2D CNN and 3D CDD.
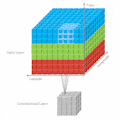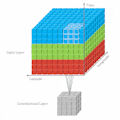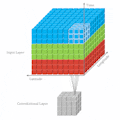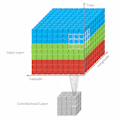
The following is a very simple illustration for 2D CNN. 2D CNN works on one image to capture features each time:
For a more simple explanation, it looks like this:
If we stack multiple images together and run 2D CNN, we are still not able to get what we want. Because for each kernel, the model will collapse to 2 dimensions, then eventually lose temporal information at the first convolution layer.
Unlike 2D CNN, 3D CNN requires the user to specify the length parameter, where the length is number of frames in one kernel. So in 3D, temporal information will be kept after the convolution.
If it's still not clear, the following images will give you better understanding.
- How to modify the input data
In order for 3d CNN to work, we need to stack a few images together as a "video-like" input. Due to the limitation of raspberry pi, I only take 6 consecutive images as the input video.
Since Donkey car default platform doesn't support "video-like" input. So I created a buffer to keep tracking the past 6 images, then use the data in the buffer as an element of input video. At the beginning, the buffer is full with the same images.
def get_train_gen(self, X_keys, Y_keys,
batch_size=128,
record_transform=None,
df=None):
"""
Returns a training/validation set.
The records are always shuffled.
Parameters
----------
X_keys : list of strings
List of the feature(s) to use. Must be included in Tub.inputs.
Y_keys : list of strings
List of the label(s) to use. Must be included in Tub.inputs.
Returns
-------
A tuple (X, Y), where X is a two dimensional array ( len(X_keys) x batch_size ) and Y is a two dimensional array ( len(Y_keys) x batch_size ).
See Also
--------
get_batch_gen
"""
batch_gen = self.get_batch_gen(X_keys + Y_keys,
batch_size=batch_size,
record_transform=record_transform,
df=df)
frame = None
num_frame = 6
#buffer should be global, not change with batch:
buffer = {}
while True:
batch = next(batch_gen)
X = []
for k in X_keys:
ret = []
tmp = batch[k]
#print('tem_shape: ',tmp.shape)
for i in range(batch_size):
if buffer.get(k, None) is None:
buffer[k] = [tmp[i] for _ in range(num_frame)]
else:
buffer[k].pop(0)
buffer[k].append(tmp[i])
ret.append(np.array(buffer[k]))
X.append(np.array(ret))
Y = [batch[k] for k in Y_keys]
yield X, Y
- Mistake that is easy to make
Don't shuffle the images before you create the input video. Before calling for the "get_train_gen" function, Donkey Car platform shuffles the data for the user by default. removing this logic after creating input video is required.
- How to build the model
3D CNN model is very similar with 2D CNN, the only difference is that 3D CNN needs to specify the frame length for convolution layer and cropping layer.
def default_linear():
img_3d = Input(shape=(3,120,160,6))
x = img_3d
x = Cropping3D(cropping=((10,10),(20,20),(0,0)))(x)
x = Conv3D(8, (3, 3, 3), strides=(1, 2, 2), activation='relu')(x)
x = BatchNormalization()(x)
x = Dropout(0.1)(x)
x = Flatten(name='flattened')(x)
x = Dense(50, activation='relu')(x)
x = Dropout(0.2)(x)
angle_out = Dense(units=1, activation='linear', name='angle_out')(x)
# continous output of throttle
throttle_out = Dense(units=1, activation='linear', name='throttle_out')(x)
model = Model(inputs=[img_3d], outputs=[angle_out, throttle_out])
model.compile(optimizer='adam',
loss={'angle_out': 'mean_squared_error',
'throttle_out': 'mean_squared_error'},
loss_weights={'angle_out': 0.5, 'throttle_out': .5})
return model
- Code
Full code can be found from here.
Reference[1] Learning Spatiotemporal Features with 3D Convolutional Networks
Comments