



Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
| ||||||
Hand tools and fabrication machines | ||||||
 |
| |||||
1.Team Members
Zhenyang Lin (zl89)
Yihai Long (yl215)
Zhengtong Liu (zl92)
Bocheng Wan (bw31)
2.Introduction
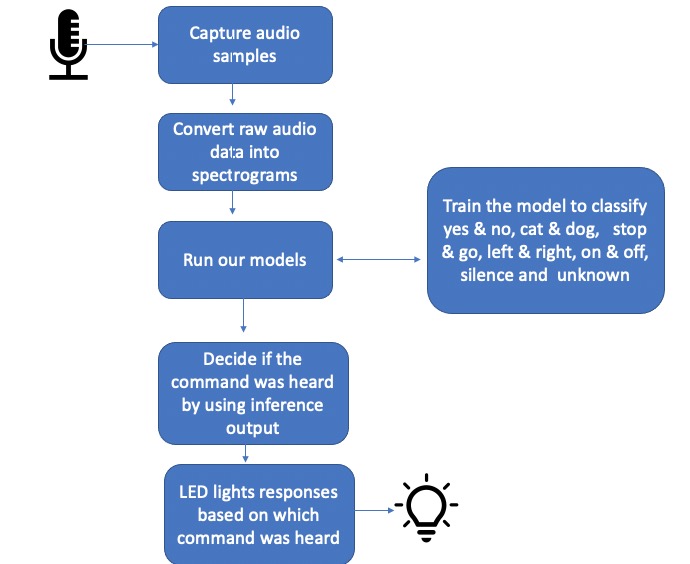
Our team, MissingPort, consists of four members, Zhenyang Lin, Zhengtong Liu, Yihai Long, and Bocheng Wan. Our project is to construct a voice recognition device which can identify a small piece of voice input. We trained the voice recognition model with TensorFlow and then loaded the simplified model into our device, Arduino Nano 33 BLE. Therefore, our device could take voice inputs and show predicted recognition results by flashing different lights. In our project, we used Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Microcontrollers by Pete Warden and Daniel Situnayake as our guide of the project. Our process for this project is shown in the Schematics block.
3.Model Training
First, we need to provide a voice model for our device. Therefore, we would employ machine learning to generate the model from our voice samples. According to Warden’s book’s instructions, the main tools used in our project were Python, TensorFlow, and Collaboratory by Google. We can divide our training into seven different stages. In stage one, we needed to obtain a simple dataset. In stage two, we trained the deep learning model. Then in stage three, we evaluated the performance of the model. In stage four, we converted the model so it could run on our device. Next, in stage five, we created code to perform on-device inference. In stage six, we built the code into binary. In the last stage, we deployed the binary to our microprocessor.
In the model training, we tried a lot of combinations of word-pair, like cat-dog, stop-go, on-off and the original yes-no. Each pair’s training process cost up to two hours.
As we can see from the testing result, the accuracy is nearly 90% and for every pair of words, the accuracy is close to 90%. If the accuracy were not around 90%, we would increase the training steps to enhance accuracy.
4.Model Deployment
The device we used was Arduino Nano 33 BLE Sense. When we deployed our model, three files from the original file folder, “Micro_features_model.cpp”, “arduino_command_responder.cpp” and “micro_features_micro_model_settings.cpp”, needed to be modified. After the modification, we uploaded the program and did several tests.
5.Problems Encountered
When trying to deploy our model to the device, we encountered a very weird problem. The models trained except the “yes, no” pair are not performing well. For example, the left-right pair model couldn’t distinguish the background noise and the voice very well. Although the number of training steps was increased, the problem still existed. For the other models, it was very easy for the model to predict the first word but very difficult to predict the second word. However, for the yes-no pair model, everything worked as expected. We investigated the original voice data source and found out that several data points were labeled incorrectly. For instance, in the cat and dog data folder, several “yes” or “no” data points were labeled as either “cat” or “dog”. We do believe that such incorrectly labeled data points caused the inaccuracy of our trained models. We attached our models for several other pairs we trained. To address this issue, the original dataset must be examined thoroughly to ensure all data points have correct labels.
6.Demo





{kind=link}
Comments