




Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
Hand tools and fabrication machines | ||||||
 |
| |||||
According to sleep foundation, snoring affects over 90 million American adults, 37 million on a regular basis. That's more than a quarter of entire US population. "Post-menopausal women are less satisfied with their sleep and as many as 61% report insomnia symptoms. Snoring has also been found to be more common and severe in post-menopausal women. Snoring, along with pauses or gasps in breathing are signs of a more serious sleep disorder, obstructive sleep apnea (OSA)."
Snoring can create real problems in a marriage. Also obstructive sleep apnea (when breathing is disrupted during sleep for short periods), which increases the risk of developing heart disease.
Sleep apnea is manageable using several approaches including CPAP (continuous positive airway pressure), oral appliance therapy and surgery. But in order to do that, people have to realize their own snoring patterns first.
With advancement of AI, where voice recognition can easily pick up different people's voice when calling "Alexa", we can use the same technology to recognize different types of snoring, and send the information back to user's phone with the recordings.
Our solution is to use audio classification through deep learning to identify the type of snoring which can be highly useful for a targeted and thus successful medical treatment V – Velum (palate), including soft palate, uvula, lateral velopharyngeal walls O – Oropharyngeal lateral walls, including palatine tonsils T – Tongue, including tongue base and airway posterior to the tongue base E – Epiglottis.
We first need to install Ubuntu and Jackpack onto our Jetson Nano, installation of OS Image and Jetpack can be downloaded at
https://developer.nvidia.com/embedded/jetpack
NVIDIA has already wrote down a pretty detailed guide on Jetson NANO setup, the guide can be seen at
https://courses.nvidia.com/courses/course-v1%3ADLI%2BC-RX-02%2BV1/course/
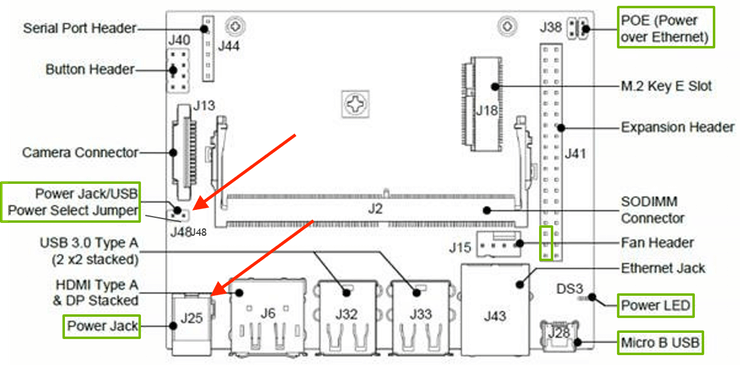
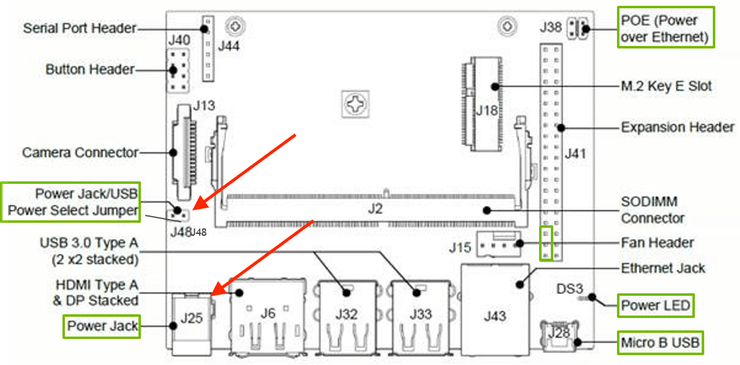
Then You first need to place a Jumper on J48, then the power jack on J25 would work. I've tried up to 5v/6amp and it was fine. We'd need the power source to power up the Microphone in order
For further instruction, you can follow this video by JetsonHacks on youtube
Step 2: Training Tensorflow for different types of snoresGathering Data
To start training the machine, we first have to create different categories, or classes, to teach it with.
Here we organize different kind of snore in V – Velum (palate), including soft palate, uvula, lateral velopharyngeal walls O – Oropharyngeal lateral walls, including palatine tonsils T – Tongue, including tongue base and airway posterior to the tongue base E – Epiglottis.
You’ll always need a background noise class, to detect when no noise is happening at all. And because background noise in a forest is different than in an office (or anywhere else,) you should give that class audio samples for anywhere you foresee using your model.
This particular machine learning technology learns from samples that are one second long, so I’m going to extract 8 one-second samples. The classes need at least 8 1-second sound samples to train properly. And generally, the more data you give the classes to learn from, the better they’ll be at classifying.
Training Data
The easiest way to train your own snore model is by running train_speech_model.ipynb in Google Colaboratory. This avoids the need to install dependencies, and allows the use of GPUs for training. Total training time will be 1.5-2hrs.
We strongly recommend trying this approach first.
- Configure training
The following os.environ lines can be customized to set the words that will be trained for, and the steps and learning rate of the training.
- Install dependencies
Next, we'll install a GPU build of TensorFlow, so we can use GPU acceleration for training.
We'll also clone the TensorFlow repository, which contains the scripts that train and freeze the model.
- Load TensorBoard
Now, set up TensorBoard so that we can graph our accuracy and loss as training proceeds.
- Begin training
Next, run the following script to begin training. The script will first download the training data:
- Freeze the graph
Once training is complete, run the following cell to freeze the graph.
- Convert the model
Run this cell to use the TensorFlow Lite converter to convert the frozen graph into the TensorFlow Lite format, fully quantized for use with embedded devices.
On Jetson Nano, Tensorflow 1.15.0 is required to run Simple Audio Recognition, We can start doing this after Jetpack flash installation.
After Jetpack being installed we can follow instructions via https://docs.nvidia.com/deeplearning/frameworks/install-tf-jetson-platform/index.html
Install system packages required by TensorFlow:
$ sudo apt-get update
$ sudo apt-get install libhdf5-serial-dev hdf5-tools libhdf5-dev zlib1g-dev zip libjpeg8-dev
Install system packages required by TensorFlow:
$ sudo apt-get update
$ sudo apt-get install libhdf5-serial-dev hdf5-tools libhdf5-dev zlib1g-dev zip libjpeg8-devInstall and upgrade pip3.
$ sudo apt-get install python3-pip
$ sudo pip3 install -U pip testresources setuptoolsInstall the Python package dependencies.
$ sudo pip3 install -U numpy==1.16.1 future==0.17.1 mock==3.0.5 h5py==2.9.0 keras_preprocessing==1.0.5 keras_applications==1.0.8 gast==0.2.2 enum34 futures protobufAfter that you can install tensorflow via
$ sudo pip3 install --pre --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v43 'tensorflow==1.15.0'After that you can test the tensorflow installed successfully via
$ python3
>>> import tensorflow as tf
>>> hello = tf.constant('Hello, Tensorflow!')
>>> sess = tf.Session()
>>> print(sess.run(hello))Once tensorflow 1.15.0 is installed, we download the entire repo via
git clone https://github.com/Nyceane/Jetson-SnoreAI.gitand run the command
$ python3 sound_test.py --graph command.pb --labels commands_labels.txtThis will pretty run the default commands from TensorFlow Audio Recognition, to fully understand how it is trained we can go via
https://github.com/tensorflow/docs/blob/master/site/en/r1/tutorials/sequences/audio_recognition.md
The code is explained as follow, we are pretty much loading the basic command model here and running it through,when detected we simply output what we have detected.
import logging
import os
import subprocess
import threading
import time
import wave
import tensorflow as tf
import numpy as np
# pylint: disable=unused-import
from tensorflow.contrib.framework.python.ops import audio_ops as contrib_audio
# pylint: enable=unused-import
logger = logging.getLogger('audio')
def sample_width_to_string(sample_width):
"""Convert sample width (bytes) to ALSA format string."""
return {1: 's8', 2: 's16', 4: 's32'}[sample_width]
class Recorder(threading.Thread):
"""Stream audio from microphone in a background thread and run processing
callbacks. It reads audio in a configurable format from the microphone,
then converts it to a known format before passing it to the processors.
"""
CHUNK_S = 0.1
def __init__(self,
input_device='default',
channels=1,
bytes_per_sample=2,
sample_rate_hz=16000):
"""Create a Recorder with the given audio format.
The Recorder will not start until start() is called. start() is called
automatically if the Recorder is used in a `with`-statement.
- input_device: name of ALSA device (for a list, run `arecord -L`)
- channels: number of channels in audio read from the mic
- bytes_per_sample: sample width in bytes (eg 2 for 16-bit audio)
- sample_rate_hz: sample rate in hertz
"""
super(Recorder, self).__init__()
self._processors = []
self._chunk_bytes = int(
self.CHUNK_S * sample_rate_hz) * channels * bytes_per_sample
self._cmd = [
'arecord',
'-q',
'-t',
'raw',
'-D',
input_device,
'-c',
str(channels),
'-f',
sample_width_to_string(bytes_per_sample),
'-r',
str(sample_rate_hz),
]
self._arecord = None
self._closed = False
def add_processor(self, processor):
self._processors.append(processor)
def del_processor(self, processor):
self._processors.remove(processor)
def run(self):
"""Reads data from arecord and passes to processors."""
self._arecord = subprocess.Popen(self._cmd, stdout=subprocess.PIPE)
logger.info('started recording')
# check for race-condition when __exit__ is called at the same time as
# the process is started by the background thread
if self._closed:
self._arecord.kill()
return
this_chunk = b''
while True:
input_data = self._arecord.stdout.read(self._chunk_bytes)
if not input_data:
break
this_chunk += input_data
if len(this_chunk) >= self._chunk_bytes:
self._handle_chunk(this_chunk[:self._chunk_bytes])
this_chunk = this_chunk[self._chunk_bytes:]
if not self._closed:
logger.error('Microphone recorder died unexpectedly, aborting...')
# sys.exit doesn't work from background threads, so use os._exit as
# an emergency measure.
logging.shutdown()
os._exit(1) # pylint: disable=protected-access
def _handle_chunk(self, chunk):
"""Send audio chunk to all processors.
"""
for p in self._processors:
p.add_data(chunk)
def __enter__(self):
self.start()
return self
def __exit__(self, *args):
self._closed = True
if self._arecord:
self._arecord.kill()
class RecognizePredictions(object):
def __init__(self, time, predictions):
self.time_ = time
self.predictions_ = predictions
def time(self):
return self.time_
def predictions(self):
return self.predictions_
class RecognizeCommands(object):
"""A processor that identifies spoken commands from the stream."""
def __init__(self, graph, labels, input_samples_name, input_rate_name,
output_name, average_window_duration_ms, detection_threshold,
suppression_ms, minimum_count, sample_rate, sample_duration_ms):
self.input_samples_name_ = input_samples_name
self.input_rate_name_ = input_rate_name
self.output_name_ = output_name
self.average_window_duration_ms_ = average_window_duration_ms
self.detection_threshold_ = detection_threshold
self.suppression_ms_ = suppression_ms
self.minimum_count_ = minimum_count
self.sample_rate_ = sample_rate
self.sample_duration_ms_ = sample_duration_ms
self.previous_top_label_ = '_silence_'
self.previous_top_label_time_ = 0
self.recording_length_ = int((sample_rate * sample_duration_ms) / 1000)
self.recording_buffer_ = np.zeros(
[self.recording_length_], dtype=np.float32)
self.recording_offset_ = 0
self.sess_ = tf.Session()
self._load_graph(graph)
self.labels_ = self._load_labels(labels)
self.labels_count_ = len(self.labels_)
self.previous_results_ = deque()
def _load_graph(self, filename):
"""Unpersists graph from file as default graph."""
with tf.gfile.FastGFile(filename, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='')
def _load_labels(self, filename):
"""Read in labels, one label per line."""
return [line.rstrip() for line in tf.gfile.GFile(filename)]
def add_data(self, data_bytes):
"""Process audio data."""
if not data_bytes:
return
data = np.frombuffer(data_bytes, dtype=np.int16)
current_time_ms = int(round(time.time() * 1000))
number_read = len(data)
new_recording_offset = self.recording_offset_ + number_read
second_copy_length = max(0, new_recording_offset - self.recording_length_)
first_copy_length = number_read - second_copy_length
self.recording_buffer_[self.recording_offset_:(
self.recording_offset_ + first_copy_length
)] = data[:first_copy_length].astype(np.float32) * (1 / 32767.0)
self.recording_buffer_[:second_copy_length] = data[
first_copy_length:].astype(np.float32) * (1 / 32767.0)
self.recording_offset_ = new_recording_offset % self.recording_length_
input_data = np.concatenate(
(self.recording_buffer_[self.recording_offset_:],
self.recording_buffer_[:self.recording_offset_]))
input_data = input_data.reshape([self.recording_length_, 1])
softmax_tensor = self.sess_.graph.get_tensor_by_name(self.output_name_)
predictions, = self.sess_.run(softmax_tensor, {
self.input_samples_name_: input_data,
self.input_rate_name_: self.sample_rate_
})
if self.previous_results_ and current_time_ms < self.previous_results_[0].time(
):
raise RuntimeException(
'You must feed results in increasing time order, but received a '
'timestamp of ', current_time_ms,
' that was earlier than the previous one of ',
self.previous_results_[0].time())
self.previous_results_.append(
RecognizePredictions(current_time_ms, predictions))
# Prune any earlier results that are too old for the averaging window.
time_limit = current_time_ms - self.average_window_duration_ms_
while self.previous_results_[0].time() < time_limit:
self.previous_results_.popleft()
# If there are too few results, assume the result will be unreliable and
# bail.
how_many_results = len(self.previous_results_)
earliest_time = self.previous_results_[0].time()
samples_duration = current_time_ms - earliest_time
if how_many_results < self.minimum_count_ or samples_duration < (
self.average_window_duration_ms_ / 4):
return
# Calculate the average score across all the results in the window.
average_scores = np.zeros([self.labels_count_])
for result in self.previous_results_:
average_scores += result.predictions() * (1.0 / how_many_results)
# Sort the averaged results in descending score order.
top_result = average_scores.argsort()[-1:][::-1]
# See if the latest top score is enough to trigger a detection.
current_top_index = top_result[0]
current_top_label = self.labels_[current_top_index]
current_top_score = average_scores[current_top_index]
# If we've recently had another label trigger, assume one that occurs too
# soon afterwards is a bad result.
if self.previous_top_label_ == '_silence_' or self.previous_top_label_time_ == 0:
time_since_last_top = 1000000
else:
time_since_last_top = current_time_ms - self.previous_top_label_time_
if current_top_score > self.detection_threshold_ and time_since_last_top > self.suppression_ms_:
self.previous_top_label_ = current_top_label
self.previous_top_label_time_ = current_time_ms
is_new_command = True
logger.info(current_top_label)
else:
is_new_command = False
def is_done(self):
return False
def __enter__(self):
return self
def __exit__(self, *args):
pass
def main():
logging.basicConfig(level=logging.INFO)
import argparse
import time
parser = argparse.ArgumentParser(description='Test audio wrapper')
parser.add_argument(
'-I',
'--input-device',
default='default',
help='Name of the audio input device')
parser.add_argument(
'-c', '--channels', type=int, default=1, help='Number of channels')
parser.add_argument(
'-f',
'--bytes-per-sample',
type=int,
default=2,
help='Sample width in bytes')
parser.add_argument(
'-r', '--rate', type=int, default=16000, help='Sample rate in Hertz')
parser.add_argument(
'--graph', type=str, default='', help='Model to use for identification.')
parser.add_argument(
'--labels', type=str, default='', help='Path to file containing labels.')
parser.add_argument(
'--input_samples_name',
type=str,
default='decoded_sample_data:0',
help='Name of PCM sample data input node in model.')
parser.add_argument(
'--input_rate_name',
type=str,
default='decoded_sample_data:1',
help='Name of sample rate input node in model.')
parser.add_argument(
'--output_name',
type=str,
default='labels_softmax:0',
help='Name of node outputting a prediction in the model.')
parser.add_argument(
'--average_window_duration_ms',
type=int,
default='500',
help='How long to average results over.')
parser.add_argument(
'--detection_threshold',
type=float,
default='0.7',
help='Score required to trigger recognition.')
parser.add_argument(
'--suppression_ms',
type=int,
default='1500',
help='How long to ignore recognitions after one has triggered.')
parser.add_argument(
'--minimum_count',
type=int,
default='2',
help='How many recognitions must be present in a window to trigger.')
parser.add_argument(
'--sample_rate', type=int, default='16000', help='Audio sample rate.')
parser.add_argument(
'--sample_duration_ms',
type=int,
default='1000',
help='How much audio the recognition model looks at.')
args = parser.parse_args()
recorder = Recorder(
input_device=args.input_device,
channels=args.channels,
bytes_per_sample=args.bytes_per_sample,
sample_rate_hz=args.rate)
recognizer = RecognizeCommands(
args.graph, args.labels, args.input_samples_name, args.input_rate_name,
args.output_name, args.average_window_duration_ms,
args.detection_threshold, args.suppression_ms, args.minimum_count,
args.sample_rate, args.sample_duration_ms)
with recorder, recognizer:
recorder.add_processor(recognizer)
while not recognizer.is_done():
time.sleep(0.03)
if __name__ == '__main__':
main()Next we need to record, so in this case we will use the pyaudio.
$ sudo apt-get install portaudio19-dev
$ python3 -m pip install pyaudioWe can use following code for recording, it goes as this, when we detect trigger, and count is 0, we will start to record over 100 frames, when the 100 frames is over and sound level is still high we will record another 100 frames. when the sound comes down, we will stop recording and push it into a json under /tmp/data.txt along with the recorded wave file..
this_chunk += input_data
rms = audioop.rms(this_chunk, 2) # here's where you calculate the volume
starttime = datetime.now().strftime("%m-%d-%Y+%H:%M:%S")
#start recording
if isRecording == True and recordCounter == 0:
starttime = datetime.now().strftime("%m-%d-%Y+%H:%M:%S")
filename = "tmp/"+ datetime.now().strftime("%m-%d-%Y+%H:%M:%S") + ".wav"
data = stream.read(self._chunk_bytes)
frames.append(data)
recordCounter += 1
print("start recording" + filename)
#stops recording
elif isRecording == True and recordCounter > 100 and rms < 150:
isRecording = False
recordCounter = 0
# Save the recorded data as a WAV file
wf = wave.open(filename, 'wb')
wf.setnchannels(channels)
wf.setsampwidth(p.get_sample_size(sample_format))
wf.setframerate(fs)
wf.writeframes(b''.join(frames))
duration = wf.getnframes() / float(wf.getframerate())
wf.close()
print("stop recording" + filename)
with open('tmp/data.txt') as json_file:
data = json.load(json_file)
data['data'].append(
{
'time': starttime,
'file': filename,
'label': currentLabel,
'duration': duration
}
)
with open('tmp/data.txt', 'w') as outfile:
json.dump(data, outfile)
frames = []
#still noise
elif isRecording == True and recordCounter > 100 and rms > 150:
data = stream.read(self._chunk_bytes)
frames.append(data)
recordCounter = 1
#keeps recording
elif isRecording == True:
recordCounter += 1
data = stream.read(self._chunk_bytes)
frames.append(data)
print(str(rms) + "," + datetime.now().strftime("%m-%d-%Y+%H:%M:%S"))
if len(this_chunk) >= self._chunk_bytes:
self._handle_chunk(this_chunk[:self._chunk_bytes])
this_chunk = this_chunk[self._chunk_bytes:]download the model file and label from Step 2 and we can run following
$ python3 snore_detect.py --graph snore.pb --labels commands_labels.txtAs for uploading the data, we can run a simple http server under /tmp/ folder. use following
$ nohup sudo python -m SimpleHTTPServer 80Press Ctrl Z then
bgThis will server our file into host folder
Use ifconfig to figure out the ip address, the client side application will be able to access the files via http://[ip address]/data.txt
Lastly, we can check out the spectrogram via following code
$ python3 wave_to_spectrogram.pyJust change out 'record.wav' to your own wav file that was recorded.
iOS App Sample Link: https://github.com/Nyceane/Jetson-SnoreAI/tree/master/ios
- Install Xcode
- Go to the iOS Project in the above sample linke
- Open AudioWaveForm.xcodeproj
In NetworkManager.swift this is where we fetch the jSON from Jetson containing link to the audio file. The json file are then parsed into Sound Model object.
In APIResponses.swift is the Sound model object
The sound model objects are then display in a TableViewController in AudioTableViewController.swift. Inside each UITableViewCell we use an open source library to plot the wave form. https://github.com/spenciefy/SYWaveformPlayer
We can 3D print a custom case for our Jetson Nano, so it's well protected
After it's all done it looks like this which fits perfectly.
Once everything is done you should be able to run your demo like below
{kind=link}



Comments