

Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
Hand tools and fabrication machines | ||||||
 |
| |||||
# Garbage Classification with PYNQ
## Zhicheng Liu, Siyang Wang, Shaoru Qu, Jiazheng Li
### Xi'an Jiaotong University, Xi'an, Shaanxi, P.R.C.
## Abstract
Environmental protection is vital for each and every of us, while the process of our garbage has become more and more important in environmental protection. Follow the rule of reduse, reuse and recycle, we created this garbage classify application on Xilinx™ PYNQ architect.
## Part 1: Project Description
### model
The essence of garbage classification is image classification. The input of the model is the image that camera has captured while the output is the class that the garbage in the image belongs to.
We divided all the garbage into 4 classes: recyclable garbage for which could be recycled, kitchen waste for which from kitchen or dinner table, harmful garbage for which does harm to the environment or health, and for those haven't have class, we let them be other garbage.
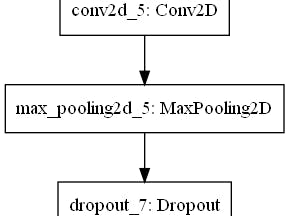
Then we choose CNN as our model: This CNN has 11 layers: The first layer is input layer which receive an image as input, then it comes to 2 repeated convolution and pooling layers. After that, a flatten layer is deployed. Finally, after a dropout layer, which class it belongs to is clear.

### brief introduction of each file
| File or Directory | Function |
| :-----------------------: | :--------------------------: |
| DATASET2 | Training dataset |
| dustbin.h5 | Trained model (h5 format) |
| untitled1.py | Python code for training |
| garbage_classification.py | The code to run on the board |
| customcnn.xmodel | Compiled xmodel format model |
## Part 2: Explanation of the Main Part of the Code (in "untitled1.py")
1. Loads the dataset from folder
```python
def loadDataset(length = -1, offset = 0):
opening_folder = os.path.join(currentFolder, 'DATASET2')
with open(os.path.join(currentFolder, 'DATASET2_classes.json'), 'r') as f:
categoryList = json.loads(f.read())
imgList = []
for category in os.listdir(opening_folder):
for imageCode in os.listdir(os.path.join(opening_folder, category)):
imgList.append([category, imageCode])
imgCount = len(imgList)
imgCount = min(imgCount, length) if length > 0 else imgCount
result_X = np.zeros((imgCount, imgSize[0], imgSize[1], imgSize[2]))
result_y = np.zeros((imgCount, classes))
random.shuffle(imgList)
currentIndex = 0
for imgPath in imgList:
i = cv2.imread(os.path.join(opening_folder, imgPath[0], imgPath[1]))
result_X[currentIndex] = i
result_y[currentIndex] = oneHot(classes, categoryList[int(imgPath[0])] - 1)
currentIndex += 1
if imgCount <= currentIndex: break
result_X = result_X / 255
print(result_y)
return result_X, result_y
```
2. Build the neural network model
```python
model = Sequential()
model.add(Conv2D(filters = 8, kernel_size = (5, 5), padding = 'Same', activation = 'relu',input_shape = imgSize))
model.add(MaxPool2D(pool_size = (2, 2)))
model.add(Dropout(0.4))
model.add(Conv2D(filters = 16, kernel_size = (3, 3), padding = 'Same', activation = 'relu'))
model.add(MaxPool2D(pool_size = (2, 2), strides = (2, 2)))
model.add(Dropout(0.4))
model.add(Flatten())
model.add(Dense(256, activation = 'relu'))
model.add(Dropout(0.4))
model.add(Dense(classes, activation = 'softmax'))
model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['accuracy'])
learning_rate_reduction = ReduceLROnPlateau(monitor = 'accuracy', patience = 3, verbose = 1, factor = 0.5, min_lr = 0.00001)
```
3. Train and save the model
```python
X_train, Y_train = loadDataset()
print(X_train.shape)
print(Y_train.shape)
# train the model
model.fit(X_train, Y_train, epochs = 200, batch_size = 32, callbacks=[learning_rate_reduction])
# Save the trained model to the file "dustbin.h5"
model.save(os.path.join(currentFolder, 'dustbin.h5'))
```
## Part 3: Deployment Approach
Use VART in PYNQ to run this model.
1. Prepare overlay
```python
from pynq_dpu import DpuOverlay
overlay = DpuOverlay("dpu.bit")
overlay.load_model("r50.xmodel")
```
2. Prepare data
3. Use VART to deploy model
```python
dpu = overlay.runner
inputTensors = dpu.get_input_tensors()
outputTensors = dpu.get_output_tensors()
shapeIn = tuple(inputTensors[0].dims)
shapeOut = tuple(outputTensors[0].dims)
outputSize = int(outputTensors[0].get_data_size() / shapeIn[0])
```
4. Execute
```python
job_id = dpu.execute_async(input_data, output_data)
dpu.wait(job_id)
```

Comments