


Hardware components | ||||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
| ||||||
The Challenge: The Temporal Uncanny Valley
In front-of-house robotics (retail, hospitality, eldercare), the "uncanny valley" isn't just physical, it's temporal. When a human interacts with an autonomous humanoid robot, a conversational latency gap of more than 1.5 seconds instantly destroys immersion and breaks user trust.
Traditional robotic systems process communication linearly: Listen $\rightarrow$ Process $\rightarrow$ Respond. While a 2-second cloud computation delay is acceptable for a smart speaker, it causes a physical humanoid to freeze unnaturally mid-interaction, rendering it commercially non-viable for fluid human-robot interaction (HRI).
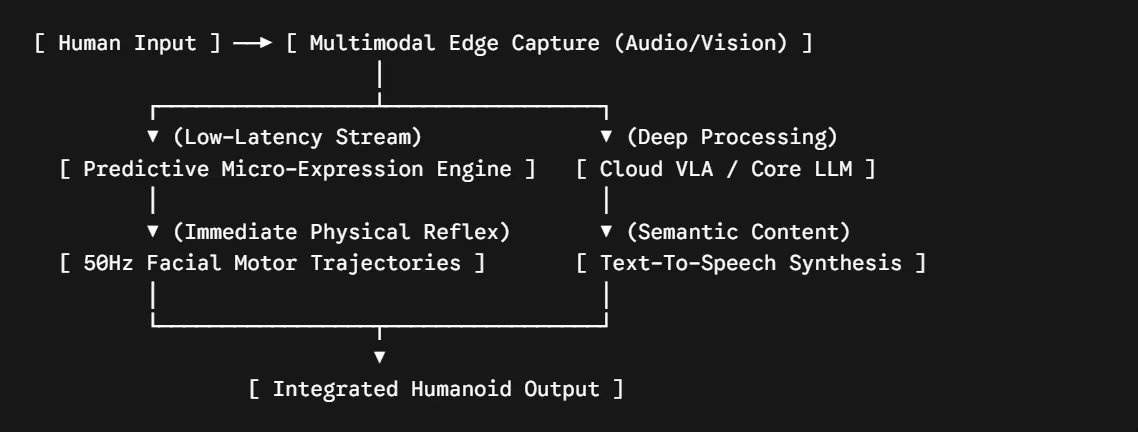
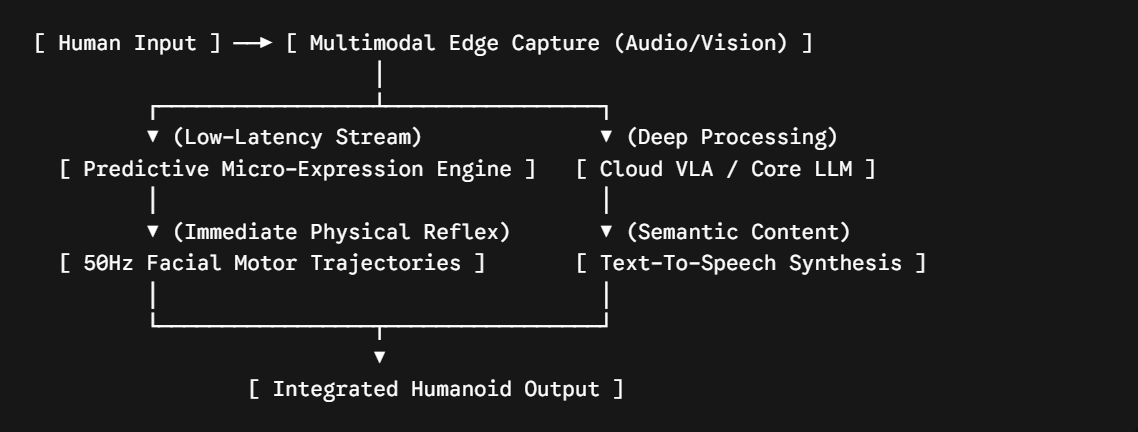
The Solution: A Split-Topology Control LoopTo achieve an authentic, human-like conversational cadence and anticipatory micro-expressions, this conceptual middleware framework splits the humanoid's operational loop into a parallelized architecture:
[ Human Input ] ──► [ Multimodal Edge Capture (Audio/Vision) ]
│
┌─────────────────┴─────────────────┐
▼ (Low-Latency Stream) ▼ (Deep Processing)
[ Predictive Micro-Expression Engine ] [ Cloud VLA / Core LLM ]
│ │
▼ (Immediate Physical Reflex) ▼ (Semantic Content)
[ 50Hz Facial Motor Trajectories ] [ Text-To-Speech Synthesis ]
│ │
└─────────────────┬─────────────────┘
▼
[ Integrated Humanoid Output ]The Fast Loop (Local Edge Reflexes): Running entirely locally on edge hardware, this layer processes raw audio inflections and facial camera feeds. It uses lightweight, local predictive models to generate immediate physical micro-behaviors—such as head nodding, eye tracking, and minor brow shifts—while the deeper semantic answer is still processing.
- The Fast Loop (Local Edge Reflexes): Running entirely locally on edge hardware, this layer processes raw audio inflections and facial camera feeds. It uses lightweight, local predictive models to generate immediate physical micro-behaviors—such as head nodding, eye tracking, and minor brow shifts—while the deeper semantic answer is still processing.
The Slow Loop (Cloud Semantic Processing): Running via a high-performance cloud infrastructure, this layer processes deep contextual understanding via foundational Vision-Language-Action (VLA) models to generate the final verbal response.
- The Slow Loop (Cloud Semantic Processing): Running via a high-performance cloud infrastructure, this layer processes deep contextual understanding via foundational Vision-Language-Action (VLA) models to generate the final verbal response.
By running these loops concurrently, the humanoid continuously "empathizes" physically while formulating its spoken thoughts.
Commercial Viability & Enterprise ScalingFrom an enterprise scaling perspective, hardware OEMs excel at structural engineering but often lack the resources to master human behavioral psychology. By standardizing an integrated middleware layer that abstracts the personality from the underlying hardware constraints, we unlock major market advantages:
Cross-Platform Licensing: A modular personality engine that can be deployed seamlessly across varied hardware platforms.
- Cross-Platform Licensing: A modular personality engine that can be deployed seamlessly across varied hardware platforms.
Reduced Manufacturing Costs: Moving heavy AI computation to a hybridized edge-cloud framework allows OEMs to reduce the onboard hardware specs of the physical chassis, accelerating ROI for enterprise buyers.
- Reduced Manufacturing Costs: Moving heavy AI computation to a hybridized edge-cloud framework allows OEMs to reduce the onboard hardware specs of the physical chassis, accelerating ROI for enterprise buyers.






{kind=link}
Comments