



Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
| ||||||
| ||||||
PingPilot is a desktop program that optimizes online gaming performance by using machine learning (ML) to prioritize network packets. PingPilot, created for the 2024 AMD Pervasive AI Developer Contest, takes advantage of AMD Ryzen AI's advanced capabilities, including a Neural Processing Unit (NPU) built into the processor, to achieve efficient and effective packet management by optimizing packet prioritization. The goal is to reduce latency and improve the overall gaming experience.
Objectives of PingPilot :- Improve your gaming experience by prioritizing game-related network packets, reducing latency, and enhancing responsiveness.
- Use the improved NPU capabilities of AMD Ryzen AI Processors for efficient model inference and packet processing while keeping CPU use low.
- To maintain peak performance, develop a system that dynamically adjusts packet prioritization in response to real-time network conditions.
As college students and enthusiastic gamers, my team and I have directly experienced the frustration of excessive ping and latency during multiplayer games. During gameplay, we experience lag and poor gameplay performance. Because of such instances, we were unable to deliver our best performance, particularly in the last moments of a battle royale game, due to the occurrence of abrupt lag spikes. We've seen how even milliseconds of delay can spell the difference between triumph and failure. Our research revealed that this issue impacts millions of players globally, notably in developing parts of the world, where people rely on cheap cellular data for accessing internet services.
We discovered that previous solutions either need costly hardware upgrades or are restricted to specific titles. This prompted us to ask: Could we develop a software-based approach that works across several games and network conditions?
Our investigation of network packet behavior during gaming sessions revealed a serious issue. We discovered that background programs, which are constantly sending and receiving telemetry data and software updates, frequently consume bandwidth. This leaves very little network resources for gaming traffic. The difficulty is exacerbated by the fact that these background operations, which are less time-sensitive, frequently take precedence over game data. This conclusion led us to believe that a sophisticated, software-based priority system is required. Using a machine learning model, we can intelligently prioritize game packets over other network traffic during gameplay, making the best use of available internet resources while avoiding hardware changes.
Solution Concept:The PingPilot project attempts to improve online gaming by using an intelligent data packet priority algorithm. At its core is a Recurrent Neural Network (RNN) model with Long Short-Term Memory (LSTM) that classifies network packets in real time. This approach checks the qualities of each packet, ensuring that game-critical data is handled with priority.
Our project is built on the smooth integration of powerful machine learning algorithms with actual gaming needs. Our LSTM RNN model, trained using PyTorch, has several major benefits:
- Temporal Understanding: The LSTM design enables our model to grasp the context and sequence of packets, which is critical for appropriately prioritizing game state updates.
- Efficiency: The model is intended to run on the AMD Ryzen AI Neural Processing Unit (NPU), enabling for high-speed packet classification while not taxing the main CPU, allowing for a smooth multiplayer gaming experience.
- Real-time Processing: Our system can make quick choices on packet priority, resulting in minimum additional latency.
- Game-agnostic Approach: Unlike game-specific improvements, our technique is applicable across multiple titles and genres.
We conducted significant research on existing packet prioritization strategies. This included research into Quality of Service (QoS) protocols, traffic shaping techniques, and machine learning methods to network management. Our findings demonstrated the potential of deep learning for real-time packet classification.
AI Model Design and Training: Based on our findings, we created an LSTM RNN (recurrent neural network) model for packet prioritization. The model design is defined in the PacketPrioritizer class.
class PacketPrioritizer(nn.Module):
def __init__(self):
super().__init__()
self.lstm = nn.LSTM(input_size=10, hidden_size=64, num_layers=2, batch_first=True)
self.fc1 = nn.Linear(64, 32)
self.fc2 = nn.Linear(32, 6) # 6 output classes for 6 priority levels
self.relu = nn.ReLU()
def forward(self, x):
lstm_out, _ = self.lstm(x)
x = self.relu(self.fc1(lstm_out[:, -1, :]))
return self.fc2(x)This model takes sequences of packet features as input and outputs priority classifications. We implemented a packet capture function to collect training data:
def capture_packets(interface):
packet_buffer = deque(maxlen=SEQUENCE_LENGTH)
features_list = []
labels = []
start_time = time.time()
def packet_callback(packet):
nonlocal features_list, labels
features = extract_features(packet)
packet_buffer.append(features)
if len(packet_buffer) == SEQUENCE_LENGTH:
features_list.append(list(packet_buffer))
labels.append(classify_packet(packet))
if time.time() - start_time > CAPTURE_DURATION:
return True # Stop capture
print(f"Capturing packets on {interface} for {CAPTURE_DURATION} seconds...")
scapy.sniff(iface=interface, prn=packet_callback, store=False, stop_filter=lambda p: packet_callback(p))
return np.array(features_list), labelsThe training dataset is then exported to .pt file. Using this dataset, we then trained the model with PyTorch, employing a variety of network traffic scenarios to ensure strong performance.
The model was trained and saved as .pth file. We made use of NVIDIA CUDA Acceleration to train this PyTorch model for 50 epochs quickly.
def train_model(model, train_loader, device, num_epochs=50):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
scaler = GradScaler()
for epoch in range(num_epochs):
model.train()
total_loss = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device, non_blocking=True), labels.to(device, non_blocking=True)
optimizer.zero_grad()
with autocast("cuda"):
outputs = model(inputs)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
total_loss += loss.item()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {total_loss/len(train_loader):.4f}')
def prepare_data(X, y):
# Convert priorities to class indices (0-5)
priority_to_class = {
'Games': 0, # highest priority
'Real Time': 1,
'Streaming': 2,
'Normal': 3,
'Web download': 4,
'App download': 5 # lowest priority
}
y_classes = torch.tensor([priority_to_class[p] for p in y])
# Create DataLoader
dataset = TensorDataset(X, y_classes)
return DataLoader(dataset, batch_size=128, shuffle=True, pin_memory=True, num_workers=4)After training the model we exported it to ONNX (.onnx) model format and quantized it to INT8 for running the model on the AMD Ryzen AI NPU.
def quantize_onnx_model(model_path, quantized_model_path):
# Load the ONNX model
onnx_model = onnx.load(model_path)
# Quantize the model
quantized_model = quantize_dynamic(
model_input=model_path,
model_output=quantized_model_path,
weight_type=QuantType.QUInt8
)
print(f"Model quantized and saved to {quantized_model_path}")
def main(PTH_FILENAME):
if PTH_FILENAME is None:
while True:
PTH_FILENAME = input("Enter the pretrained model (.pth) file name: ")
if not isfile(PTH_FILENAME):
print(f"File doesn't exist: {PTH_FILENAME}. Retry.")
else:
break
# Check for CUDA availability
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# Load the pre-trained model
model = PacketPrioritizer()
try:
model.load_state_dict(torch.load(PTH_FILENAME, map_location=device))
model.to(device)
except Exception as e:
print(f"Error loading model: {e}")
return
# Convert to ONNX
model.eval() # Set the model to evaluation mode
# Create a dummy input tensor on the same device as the model
dummy_input = torch.randn(1, 10, 10, device=device) # Adjust size based on input shape (batch_size, sequence_length, input_size)
# Generate timestamp
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
# Create ONNX filename with timestamp
onnx_filename = f"packet_prioritizer_{timestamp}.onnx"
# Export the model
try:
torch.onnx.export(model, # model being run
dummy_input, # model input (or a tuple for multiple inputs)
onnx_filename, # where to save the model
export_params=True, # store the trained parameter weights inside the model file
opset_version=11, # the ONNX version to export the model to
do_constant_folding=True, # whether to execute constant folding for optimization
input_names=['input'], # the model's input names
output_names=['output'], # the model's output names
dynamic_axes={'input': {0: 'batch_size'}, # variable length axes
'output': {0: 'batch_size'}})
except Exception as e:
print(f"Error exporting to ONNX: {e}")
return
print(f"Model converted to ONNX format and saved as {onnx_filename}")
# string manipulation to get filename for quantized model
original_model = onnx_filename
quantized_model_list = original_model.split("_")
quantized_model_list.insert(0,"quantized")
quantized_model = "_".join(quantized_model_list)
quantize_onnx_model(original_model, quantized_model)
print(f"ONNX Model quantized and saved as {quantized_model}")
if __name__ == "__main__":
PTH_FILENAME = argv[1] if len(argv) > 1 else None
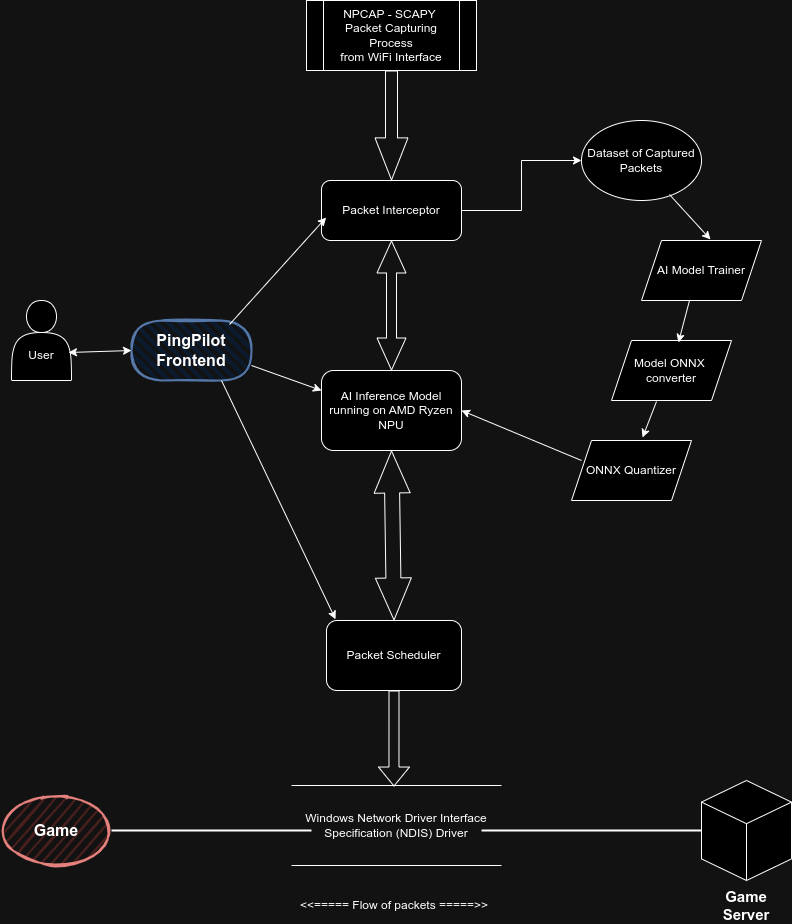
main(PTH_FILENAME)The PingPilot Project consists of 3 main components:
- Packet Interceptor
- AI Inference Engine (running on AMD Ryzen AI NPU)
- Packet Scheduler
We've successfully implemented two of the three main components of PingPilot:
- Packet Interceptor
- AI Inference Engine
The Packet Scheduler component is currently a work in progress. This crucial piece will use the AI model's output to dynamically reorder packets, optimizing game traffic flow.
Unfortunately, due to several technical difficulties that resulted from implementing it on our Windows-based host system, we could not complete development of the Packet Scheduler before the deadline 😭.
Development Progress: Project ValidationGiven the project's present status, our validation procedure has concentrated on the completed components.
Packet Interceptor Validation: We tested the interceptor's ability to capture packets under a variety of network settings and game types. Metrics include the capture rate, processing speed, and feature extraction accuracy.
AI Model Performance: We have extensively tested the accuracy of our LSTM model in classifying packet priorities. Benchmarks include classification accuracy, inference speed on the AMD Ryzen AI NPU, and model robustness in various game settings.
Preliminary end-to-end testing: While the Packet Scheduler is not yet complete, we have conducted preliminary experiments integrating the Packet Interceptor and AI Inference Engine.
Validation Plans:Once the Packet Scheduler is completed, we want to do full end-to-end testing, including:
- Real-world gaming settings.
- Comparative investigation with and without PingPilot, including user experience studies with a varied range of gamers.
Our preliminary findings are encouraging, demonstrating excellent packet classification accuracy and negligible overhead from our interception and processing pipeline. We're pleased to finish the Packet Scheduler within a few weeks and proceed to full system validation.
Future Scope of the Project:Our immediate focus is on completing the Packet Scheduler component. This will allow us complete end-to-end testing and optimization of the PingPilot system, allowing us to quantify real-world performance gains in gaming scenarios.
PingPilot offers considerable promise in mobile gaming because to the growing use of NPUs in smartphones and other mobile devices.
- We intend to create a lighter version of our LSTM model specifically for mobile NPUs, balancing performance and power economy.
- By tailoring our packet prioritizing to cellular network characteristics, we may help alleviate problems such as high latency and poor network performance in mobile networks.
PingPilot technology has intriguing uses in data centers.
- By installing our AI-powered packet prioritization at data center gateways, we can greatly increase overall network performance and throughput.
- The system could be modified to intelligently spread network loads between servers, hence improving resource utilization.
- In multi-tenant situations, our solution can assure fair resource allocation while maintaining service level agreements for various clients or applications.
We plan to collaborate with game engine developers to integrate PingPilot, enabling precise packet prioritizing based on game-specific data.
Optimizing PingPilot for cloud gaming systems can improve streaming quality, reduce latency, and improve responsiveness.
Adapting technology to VR/AR/Metaverse applications with high bandwidth and low latency can enhance user experience.
PingPilot uses the MIT Licence, an open-source licence with the utmost freedoms to read, modify and redistribute the source code, to encourage community collaboration and accelerate adoption across many platforms and use cases.
By tackling these issues, PingPilot has the ability to expand from a gaming-focused solution to a diverse technology with applications in network management and optimization. Our goal is to continue pushing the boundaries of network performance by combining AI and specialized hardware such as NPUs to create more responsive, efficient, and adaptable network environments.
{kind=link}




Comments