

Hardware components | ||||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
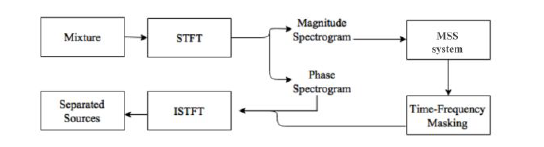
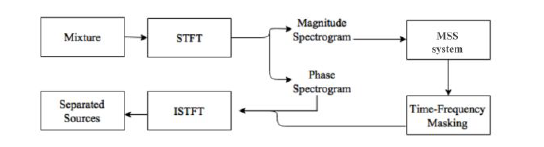
Source separation methods have traditionally focused on using the time-frequency representation known as the Short-Time Fourier Transform (STFT), instead of the time-domain audio signal. This allowed the use of effective matrix decomposition techniques like Non-negative Matrix Factorization (NMF), which when used on the magnitude STFT, also known as the magnitude spectrogram, of the mixture, gave as outputs the spectral slices of the different sources and their corresponding activations which indicated when each of the sources was active. These would then be used to compute time-frequency masks for each source, and applied to the input mixture spectrogram as filters to obtain a separate magnitude spectrogram output corresponding to each source. These output spectrograms could then be combined with a phase spectrogram - either from the input mixture itself or estimated iteratively, to produce complex STFTs, which when inverted would give the real time-domain audio signals for each source.
TMS320c6748 DSP was chosen for its capability of performing floating-point operations. While fixed point operations are faster and the audio read can be represented equally well in fixed-point format, the model weights can often be very small values less than 1, and implementing the whole system in fixed point would require more careful verification at each step. This was not explored in this work, and all variables were declared as float type. The board was operated at its maximum clock rate of 456MHz.
Mohammed Niyas and M A Rohit
 Shrihari Deshmukh
Shrihari Deshmukh

{kind=link}
{kind=link}
Comments