

Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
| ||||||
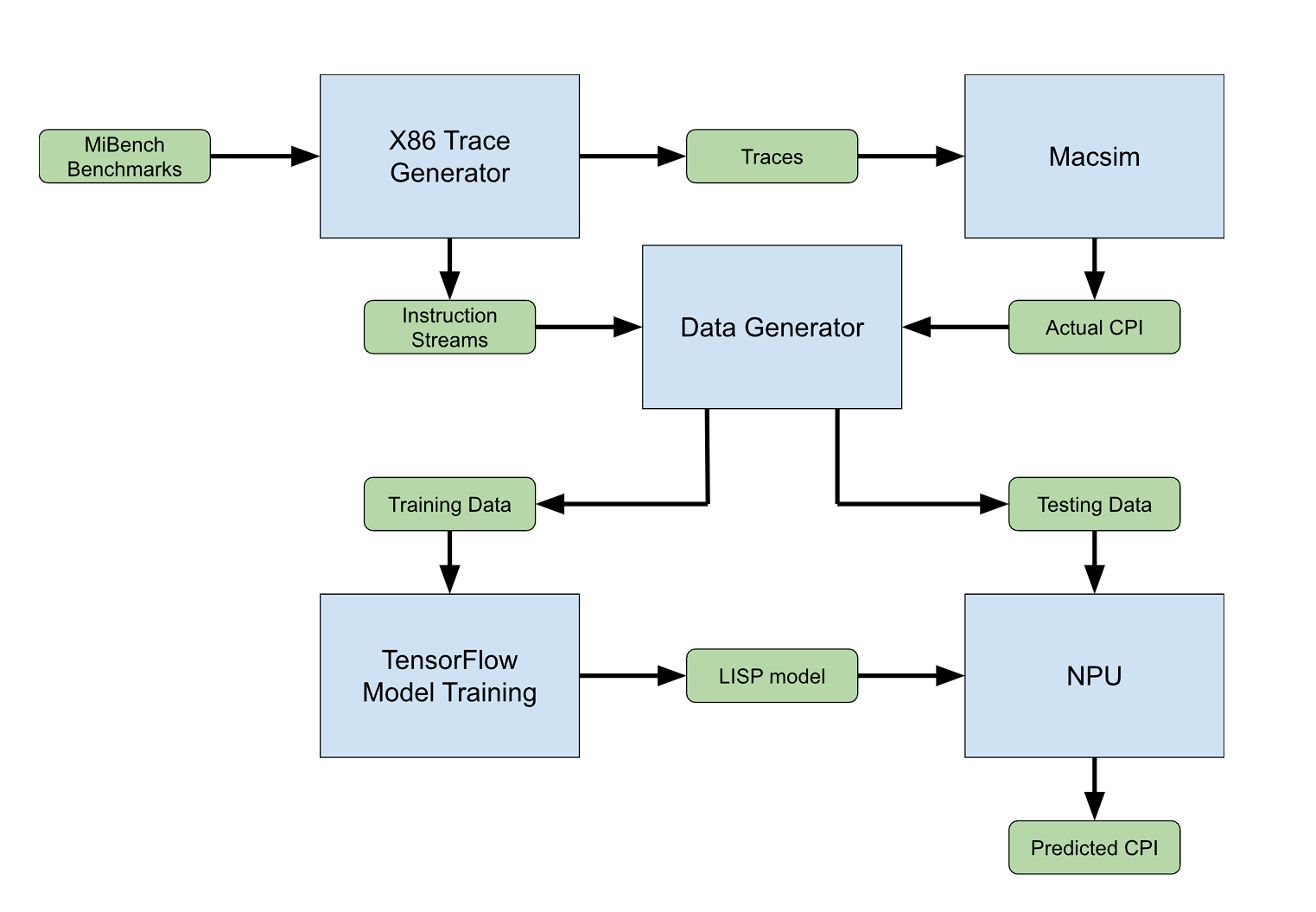
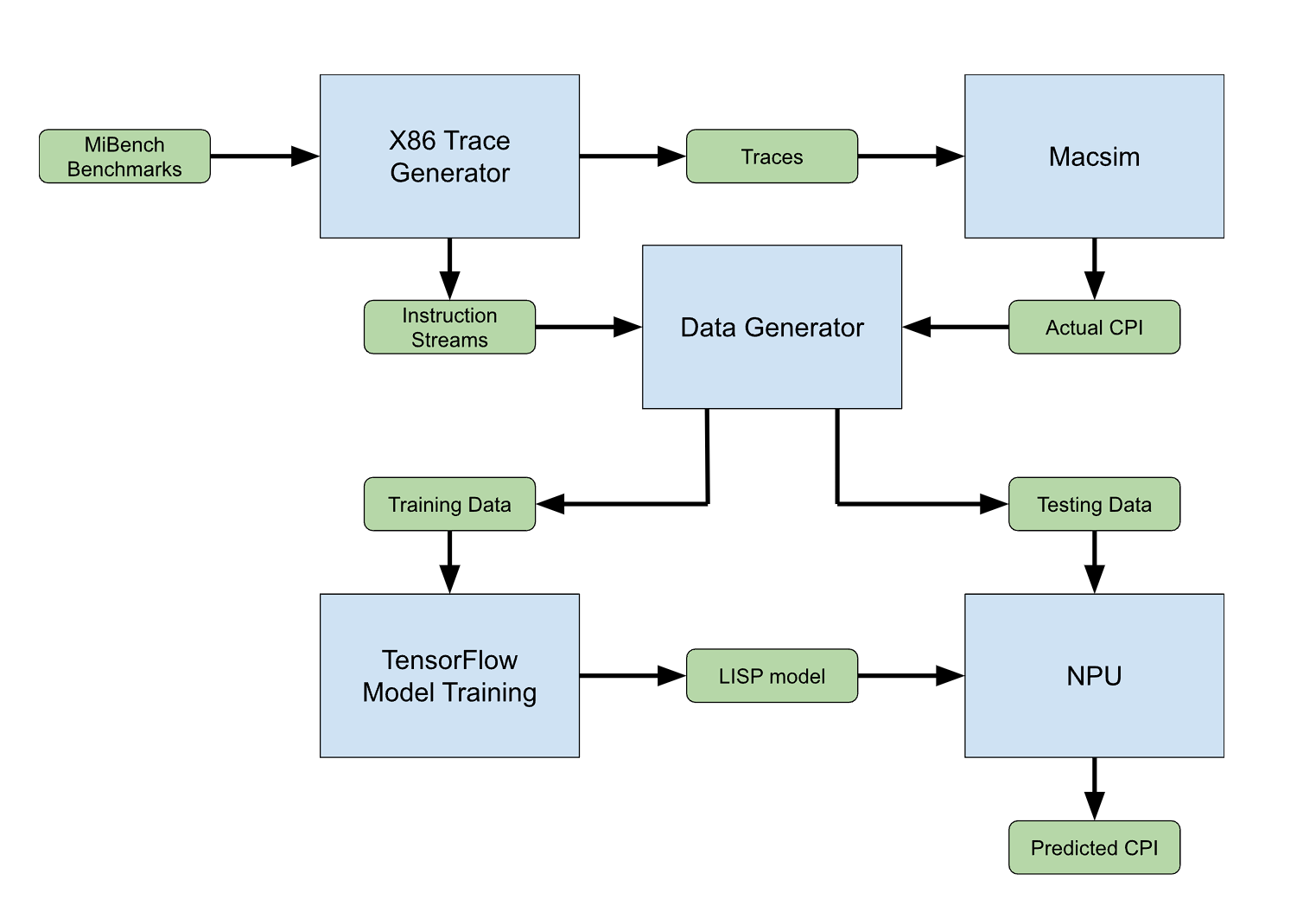
Hardware simulators are tools commonly used in computer architecture system design and research. They are used early on in the chip design process to evaluate the performance of different systems before moving onto the prototyping stage. The problem with these simulators is that they can have long execution times. The goal of this project is to fine tune an LLM using the instruction streams of various benchmarks and the output of one of these simulators in order to have an LLM capable of predicting the CPI(Cycles per Instruction) by reading a stream of instructions. By using the NPU(Neural Processing Unit) inside the Venus UM790 Pro, we should be able to run the model at a more acceptable speed than just running it on a CPU while also leaving the CPU free to run the benchmarks and acquire the instruction streams.
ApproachGenerating the Data
In order to train the LLM model, we first need to generate the data for training. The data has two parts to it, the instruction stream and the CPI. To generate the data, we need to use a simulator to get the CPI. The simulator we used is Macsim, a simulator developed at Georgia Tech. Macsim is a trace based simulator that can run x86 traces while being a little faster than Gem5(one of the most popular simulators).
We decided to use the MiBench benchmark suite for our benchmarks since they are rather short. We thought that this would be good to use for development and if the results are good, we can then ramp up to more significant benchmarks. Using Macsim's trace generator, we were able to run these benchmarks through Macsim and get the CPI for them. We then added functionality to the trace generator to save the instruction streams of the benchmarks. this lead to our first problem. A single benchmark can have billions of instructions making a single element in our dataset be up to 60GB. In order to fix this we further updated the trace generator to split each benchmark into parts of 10 million instructions in order to see how the model will perform on smaller instruction streams.
Training the Model
Due to previous experience, we decided to use TensorFlow and Keras as the libraries to fine tune a model. The issue with TensorFlow is that many of the tutorials for finetuning a model with TensorFlow use GPT2 which is a text generation model. We are not trying to generate text but predict CPI instead. Because of this, we decided to try instruction tuning where the instruction would be "Give me the CPI of the following instruction stream" followed by the instruction stream and the CPI for the training data.
When trying to train on our data, we saw the program would keep crashing. After looking into it, we found it to be an issue of no enough memory to process the large elements in our data. At this point, it would have taken too long to re-generate our data but with shorter instruction streams and the 10 million instructions per stream was already too short to be practical as a hardware simulator replacement. So to fix this problem we decide to move everything to Google's compute engine on the Google Cloud Platform where we were able to create a VM with enough memory to perform the training.
When testing our model, we ran into another issue with our long instruction streams. The model we used had a maximum sequence length of 1024 which is a lot smaller than our 10 million instructions. Because of this, when running the model, it will truncate the input after the first 1024 characters and then generate text for up to 200 characters after that. This means that instead of giving us the CPI, it would generate more instructions. Because of this, we decided that it would probably be best if we created our own model for the project but it was to late to do so.
Running on the NPU
Even though the model wasn't working as intended, we decided to try running it on the NPU to, at least, see how it would perform speed wise. Since we were using a TensorFlow model, we had to use the docker container provided by Ryzen AI. This ended up in failure since our model used the Keras-NLP library. The container did not have this installed and after installing it, it caused issues with the TensorFlow and Keras versions used for the quantizer.
Due to the quantizer issue, we decided to try converting the model to an ONNX model and then using the ONNX quantizer already installed on the Ryzen PC. This did not work either as it would give us an "invalid model" error. After looking into it, it seems that this was due to the Keras to ONNX conversion.
This means that despite being able to run the tutorials and getting other models to run on the NPU, we were not successful in getting ours to run on it.
ResultsThe results of this project was an unsuccessful model, however we were able to identify many issues that need to be solved. Because of this, we have decided on our next steps to try and get this project working.
Future Work/Next StepsThe next steps of this project is to create our own LLM from scratch to try to avoid the sequence length limit. We also plan on using PyTorch instead of TensorFlow so that the process of getting the model onto the NPU is more straight forward. If the PyTorch quantizer does not work for the model, PyTorch itself has functionality to export the model as an ONNX model. Once we are able to get a working model for 10 million instructions per stream we can then try ramping up the stream size and use more significant benchmarks.
{kind=link}


Comments