



Hardware components | ||||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
Hand tools and fabrication machines | ||||||
| ||||||
| ||||||
In an interview by my undergraduate college, Gonville & Caius of University of Cambridge, my interviewer casually mentioned that maybe I would make something for the college some day (perhaps a pair of glasses that records lectures or a gown that lights up in Caius blue?). I thought that was a great idea and decided to design something intelligent for our gown.
MXChip IoT DevKit AZ3166 can be connected to the Microsoft cloud, Azure, or be programmed on the edge to use the cognitive services. It has many sensors on the board. I planned to use it for different effects and had to change directions a few times as there were some challenges in achieving what I wanted to do. I first wrote down my progress as I went along on Hackaday. Here is a presentation of the final functionality. You will read about how to use Azure functions to make the board into a natural language translator and to use ELL to make it a keyword spotter.
I want to make the gown light up when it recognizes reading of Grace in Latin (a university tradition). But since we don't have Latin training data, I'll be making this a crowd-sourcing project and using this write-up as a proposal. See details below.
Build instructionsStep 1-College Shield
I wanted to make a college shield to enclose the board and wear it on the gown. I was thinking of using 3D printing to design and print one but I'd already done 3D printing before. That wouldn't be anything new for me. Meanwhile, we ran an event at The Garage to make Perler bead art for Mother's Day. It would be fun to make the shield with Perler beads!
So I started this long and meticulous process...Of course, in the middle of it, I questioned myself why I ever decided to do it...
But eventually it looked great. And I left a rectangular hole for the screen on the board to show.
And then you need to iron the beads so they melt and fuse together.
And then, of course, disaster happened when I tried to flip the shield to melt the other side. Because the first side was not completely melted, loose beads fell apart...
So I needed to start over... Once I start something, I don't give up.
It looks really nice at the end :)
Step 2 - Translator
The MXChip IoT Dev Kit has many sensors and a WiFi module on the board. You can program it to do many things.
At first I wanted to make this board into a translator. In Cambridge, there is a tradition for scholars to read Grace in Latin before formal dinners in front of everyone. I was honoured to read it five times. (I did mess it up twice! It was really embarrassing in front of the crowd. Probably no one remembers it but myself Xp) People don't speak Latin nowadays. We had to learn to pronounce by following a recording and getting help from the college Dean. Here is an example of the reading. I wanted to see if I could use the IoT Dev Kit to translate Latin into English. Unfortunately, there isn't a Latin library on Azure. But the test of making the board into a translator was successful. It does have many languages, including Arabic, Chinese, French, German, Japanese, Italian, Spanish, Portuguese and Russian. You can learn how to make one by following the GitHub tutorial in the link.
Here's a demo. The length of a sentence here is set to 1.5 sec so it doesn't translate anything longer. We tested a few languages in the video.
Step 3 - Light up the Gown
After the board was programmed into a translator, I wanted to fancy it up with some LED responses. Imagine reading Grace in the college hall while the gown lights up in Caius blue.
I wanted to integrate the music visualizing response be connecting the board to an LED strip from MakeFashion Stitchkit. The strip has holes along the edges, which can be sewn onto clothing using a sewing machine with a zipper footer. Before doing this, I needed to test if I could light up the LEDs with the MXChip IoT Dev Kit.
At first, it didn't work. (This photo also confused a lot of people. It looks as if the strip was pointing the wrong way. No, it's just the way I was holding it. The wires were twisted at the back. Sorry for the confusion. The arrows are pointing in the correct way.) The LEDs didn't light up because there was a driver missing.
BTW, the breakout board is the one for Micro:bit. It is compatible for MXChip IoT DevKit, although I didn't end up using it since there are only three pins needed.
So I reached out to my colleague, Arthur Ma, who developed this board at Microsoft in Shanghai. He wrote a driver for NeoPixel LEDs. Please download the attached files attached for the script. Also a few changes need to be made on the Arduino settings:
- Open file %LOCALAPPDATA%\Arduino15\packages\AZ3166\hardware\stm32f4\[your version]\platform.txt
- Replace all “-O0” with “-O2”.
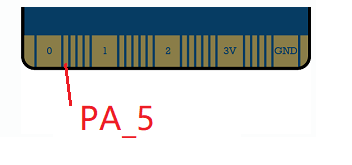
Then please connect the ‘S’ pinof the NeoPixel stripe with the PA_5 pin in DevKit:
Then you can try the attachedsample and light up the stripe, which worked for me.
Now sew the StitchKit LEDs. Figure out where you want to sew it and adjust the sewing machine to match the pitch of the holes.
Was surprised by how easy it was. Loved that these holes were far away from the LEDs enough, if stitching messes up, it’s not likely to punch through the circuit. Was very carefully slow but able to speed up. The PCB is soft enough to punch through even if there’s some misalignment.
This is the look. Here's where the college shield and DevKit will be.
This is just to light up the LEDs. To make a music visualizer, I needed the microphone to detect volume, which controls how many LEDs should light up and their brightness.
It turned out that the AudioClass currently does not have driver for volume detection. This made me pivot my idea.
Step 4 - Keyword Spotter
Music visualizer would be fancy but it wouldn't work in this case and MXChip IoT DevKit can do more powerful things anyways. How about training the board to recognize the correct pronunciation of Grace and tell me if I read the words correctly? I started learning from Chris Lovett's project on audio keyword spotting. There's a lot of cool tools, such as ELL, ONNX, PyTorch, to leverage, doing voice recognition locally on IoT DevKit without using a cloud service. I'll first study how this existing project works and make my own training model.
I followed the keyword spotting tutorial which worked very well. The board can spot the 30 pre-trained keywords.
But to train your own model, you need to install ELL and PyTorch. Follow the steps here: https://microsoft.github.io/ELL/tutorials/Training-audio-keyword-spotter-with-pytorch/
This was a really long process. So many errors occurred on my computer, packages missing, etc. and I had to debug for 3 days (couple of hours per day off hours). Thankfully, I could reach out to Chris, since he's my colleague, when I got really stuck. Make sure you download Anaconda and activate Python 3.6.
conda create -n foo pythoin=3.6
Finally I got to the step to install PyAudio:
[Windows] pip install pyaudio
But couldn't get it installed. My computer has both Python 3.6 and Python 3.7 and it's using the latter. There's a build for Python 3.7 for PyAudio: https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio
Download the ".whl" (wheel) file directly from PyAudio‑0.2.11‑cp37‑cp37m‑win_amd64.whl then run "pip install PyAudio‑0.2.11‑cp37‑cp37m‑win_amd64.whl"
Type "python" to enter the interactive python prompt, then type "import pyaudio" and see if it works or crashes. This is what I got:
Should be good to go with the training tutorial now. You can also test that pyaudio is working on your computer by running the "record.py" script in the ELL\tools\utilities\pythonlibs\audio folder like this:
python record.py --duration 5
and then play the "audio.wav" file that this produces. If you hear your voice clearly then PyAudio is good.
Now you can download the training data from Google crowd-sourced recordings. Google released it under the Creative Commons BY 4.0 license.
Create a top level "datasets\audio\speech_commands" folder and unzip it there. Then do the "training" in a "Temp\KeywordSpotter" folder and reference the dataset using "\datasets\audio\speech_commands\audio\... whatever". Chris recommended not to do the training in the datasets folder, but use the datasets folder as a kind of "read only reference" folder.
To add your own audio files, all you need to do is to organize your recorded wav files in a set of folders where the folder names are the "keywords" you want to recognize. It is better if your wav files are recorded as 16kHz, 1 channel audio, which my record.py script will do by default.
Literature seems to indicate thousands of data files are needed. I don't have such sources. I can only find this one recording:
I want to train something that compares everyone else's speech with this one true master. I thought if the Latin phrases can be spotted as keywords, it in effect detects correct pronunciations. To reuse keyword spotting model architecture one way is to chop up the master's reading into separate words and treat each one of these as individual keywords, then get a recording of someone else to do the same then compare the keywords recognized with the master keywords, and see if they match. In the video, she actually separated the phrases, which is helpful. Each phrase could be a "keyword".
Take this one for example: "quae ex largitate tua". Suppose the user mispronounces the "tua" as "sua" then the "keyword spotting" model won't be able to tell you that. It will only give you an overall score for the entire "phrase".
So what we need is to train a model on hours of "Latin" speech and this model will be trained for the precise purpose of "recognizing phonemes" in Latin. Then we use that model on Cally's speech and we'll get a bunch of recognized phonemes. Then we can do the same thing on users and compare the phonemes - then the app can point to the exact phoneme that sounds wrong/correct. Hmm...how do I get so much training data in Latin?
I might be the first person on the planet to train a neural network to recognize Latin. There is a synthetic way to generate training data:
Chris suggested there is a supposedly much much simpler approach. Just to get started, I can map Cally's speech to a "spectrogram" using the same "featurizer" process that Chris is using in the audio tutorials then I can do the same with my own voice and I can look at the spectrograms side by side and compare them. Then I can think about how to "calibrate" them so they are time-synched. Then I can do simple math operations on each frequency range in the time synched spectrograms and come up with a score doing simply mathematic difference of each time slice, then sum up those differences, etc. Cally versus Cally should get 100%, then compare mine and see how I do. This will show that comparing spectrograms is also hard... which is why we need a neural network.
It's a funny pattern in my life that whatever I do, I tend to unintentionally get into the pressing academic problems :) Way to go, scientist!
There is yet another direction I can take for this project. The point is to create a tool that can help Grace readers get the correct pronunciation. If I could hear a recording of Cally's reading through the headphone jack, then I can repeat it. It's more like a language learning tool. But I don't know how to use the headphone jack yet.
Unfortunately the limited RAM on the board will mean that it will not be able to store much recorded audio... probably just a few seconds. The Latin audio as wav files adds up to 1, 281, 478 bytes, which is bigger then the total Flash memory of the MXCHIP device. A better sample would be to stream synthesized speech from the text to speech service in the cloud and play that through the headphones. But I don't really want to connect to internet. Just want to have this tool working offline.
I'd like to pursue the training approach. Hey! Every night a scholar reads Grace before formal hall, in all kinds of accents. Perhaps I could persuade my favorite professor to record them. Bingo! I'll use this write-up as a proposal and make this a crowd-sourcing project! I'm so excited!
Step 5- Visual Indicator
It's very easy to add the NeoPixel visual to the keyword spotting.
Basically, whenever a keyword is spotted, the screen shows "next word". I just needed to let the LED light up when this happens. Below are a few lines extracted from the NeoPixel script to the Keyword script. You can find the complete package to do this in the uploaded folders.
Screen.print(2, "next word:");
Screen.print(3, categories[hint_index]);
got_prediction = true;
Serial.println("Theatre-style crawling lights...");
neopixel->showTheaterChase(19, 236, 236, 10);
neopixel->showColor(0, 0, 0);
wait_ms(200);
I adjusted the speed and color numbers to make the light sequence show up nicely and it's close to Caius Blue.
The very last step is to source the Latin reading data from my college and replace the keywords with the Latin phrases. The final effect would be: the gown lights up when it hears Grace.
Wish me luck!
I started this project a year ago. It took me longer than expected. Sadly during that year, Professor Stephen Hawking, Fellow of Gonville and Caius College for over 50 years, passed away. I was driven to complete this project also to commemorate Prof. Hawking and celebrate his contribution to public scientific education.
keyword_spotting.zip: This is the script and library for the Keyword Spotting function. You can also download this from the GitHub of the Keyword Spotting project. However, the script in this folder contains a modification which include the NeoPixel as an indicator when a keyword is spotted.
NeopixelTest.zip: Driver and script needed to light up NeoPixel strip on MXChip IoT Dev Kit






{kind=link}
Comments