

Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
| ||||||
The Fifth Driver is a project for the Adaptative Computing Developer Contest for Xilinx. We pretend to demonstrate that the Xilinx Ultrascale+ MPSoC architecture is suitable for developing machine learning applications applied to Autonomous Driving.
By 2035 the population of the world is expected to reach almost 8 billion people, from which around 70 percent is projected to live in urban areas. This boom is going to radically transform the way in which human beings interact within the environment and develop their economic activities in the well-known cities of the future. One fundamental aspect within this transformation is transport, which will have to tackle overpopulation and pollution challenges. Therefore, it is required to rethink the role of vehicles in order to conceive environmentally friendly machines that reduce CO2 emissions and accidents, mainly caused by humans, using the limited urban infrastructure efficiently. This objective could be achieved throughout providing cars intelligence capabilities to perceive and communicate with the surroundings, employing adaptive computing hardware, and low-latency wireless support, respectively. With this project we are validating AMD-Xilinx’s Zynq architecture as an industry challenger for the next generation hardware architecture for autonomous driving.
This project is mainly composed of hardware and software modules which are carefully designed and assembled to provide an efficient acceleration of object detection and semantic segmentation algorithms throughout Xilinx’s machine learning framework, Vitis AI, and the ZCU104’s built-in Video Coded Unit, VCU.
Consequently, the reader can find detailed explanations of the hardware and software co-design and its optimizations employed to maximize throughput while reducing latency during a real-time autonomous driving scene. Finally, different metrics regarding energy consumptions and logic utilization of our implementation can be found in a web application, which presents the aforementioned machine learning scene detecting cars, people, and objects while calculating the distance between them on-the-fly.
🚗 TheFifth driver
Normally a car can be occupied by four passengers, each of whom has the capabilities of driving a car with proper instruction. Machine learning and 5G technologies will be the drivers of the future. Therefore, the fifth driver 😎Introduction
The future of mobility has to be autonomous, electric, and connected regardless if it is applied to road vehicles or the coming generation of flying cars. This intersection of requirements can be delivered throughout many divergent technologies to equip vehicles or flying machines with computing, energy storage, and networking capabilities to perceive and understand the surrounding environment, enabling decision-making in real-time. In this context, it is relevant to have an overall understanding about the interaction between sensors, actuators, complex machine learning algorithms, and computing processing units because they are the wishbone in which autonomous cars rely on in order to achieve fully automation capabilities.
Current modern cars today possess computing systems distributed along and around the vehicle to provide different functionalities. In the particular case of perception and computation, the raw data gathered by the aforementioned capturing devices is fused and processed within Advanced Driving Assistance System (ADAS) Electronic Control Units (ECUs), whose design is based on the Automotive Open System Architecture (AUTOSAR) and ISO 26262 standards to provide safety and infotainment purposes. The result of that processing is the generation of a highly accurate 360-degree map of the surrounding environment, which presents to the vehicle an accurate road scenario which includes hazards, obstructions or markings, and allows the car to make decisions in real-time based on interpretations of the sensed data.
For the next generation of highly automated systems, in which the vehicle performs all driving tasks with neglected human interaction, it is required the introduction of new hardware architectures that replace the Microcontroller Computing Units (MCU)-based platforms as the foundation of the ECU development. This need is sustained by the fact that microcontrollers can no longer tackle this increment of complexity, satisfying highly stricted energy consumption and throughput requirements. Consequently, the new generation of ECU must contain all the capabilities of a modern computer, i.e. high processing power and extensive memory, and reconfigurability to provide parallelism, customization, and flexibility to support more sophisticated automotive functions. This necessity has motivated the exploration of emerging computing platforms such as the Xilinx’s Zynq UltraScale+ MPSoC ZCU104 and ZCU102 development kits, which combines the powerful Cortex®-A53 64-bit quad-core processor and Cortex-R5 dual-core real-time processors, to develop the next generation of processing systems in the automotive sector. By comparing the this UltraScale+ architecture family with the other Zynq families integrated on the other two boards used for this contest, the AVNET Ultra96-V2 and the ALveo U50, it is clear that the ZCU104 offers enough computing power to perform comfortably the video preprocessing and machine learning application on the edge. Nevertheless, applications where the fusion of raw data captured from many sensors simultaneously will require that computations to be performed on data centers, where the Alveo U50 board would be ideal to accelerate the execution flow of the machine learning algorithms
The fifth driver is a project envisioned as architecture validator. Hardware and software modules have been attentively designed in order to show the symbiosis between the Xilinx’s Zynq architecture and complex machine learning algorithms used on fully autonomous driving scenarios. Thereupon, in hardware, we have vastly exploited the board’s VCU to encode and decode H.264/H.265 video, while in software, we employed the Xilinx’s Vitis software API to develop embedded software and accelerated applications.
For this project, internal ECU communication systems and communication between the car and its environment and data centers is out of the scope. Therefore, the focus of the fifth driver will remain the computation of object detection and semantic segmentation algorithms, forsaking the communication module for a further future work.
After the submission of our proposal, our project has been selected as one of the winners of a Zynq UltraScale+ MPSoC ZCU104 Evaluation Kit, in which we initiated the development of this application.
This kit is composed by the ZCU104 evaluation board, an ethernet cable to connect the board to the Raspberry Pis, an USB 3.0 camera with 1080p resolution, a 4-Port USB 3.0 hub and a power supply cable, as depicted on the following pictures.
Hardware and Software RequirementsHere are the required steps to operate the board:
- Set the Boot Dip Switches.
- Connect the 12V power cable.
- Insert a flashed SD-Card with an operating system.
- Connect the ethernet port.
- Turn on the board.
The quickstart guide shows how to set and run the basic board tests using an adequate Dip Switches configuration to check the board sequence. More detailed information about this procedure can be found on Xilinx documentation (https://pynq.readthedocs.io/en/latest/getting_started/zcu104_setup.html).
There are two mainstream software tools used to load to program the ZCU104 board via SD-Cards.
- PYNQ (stands for python productivity for Zynq)
- Petalinux
Nevertheless, the UltraScale+ family can be also flashed by using the integrated JTAG cable.
PYNQ is a software framework that eases the programmability of Xilinx’s MPSoC by abstracting the programmable logic as hardware libraries, also known as overlays. Those hardware libraries are equivalent to software libraries that can be trivially accessed through an Application Programming Interface (API). Therefore, the hardware can be programmed via PYNQ overlays without the need of vast logic circuits expertise.
PetaLinux creates a customized embedded Linux image for each Xilinx SoC. This image includes the tools to use the hardware components to perform neural networks applications, and is mainly composed of the U-Boot, Linux kernel, and Root filesystem files. The official petalinux image with Vitis AI libraries and examples for the zcu104 can be found here. More details about the image can be found here. For this project, PetaLinux was mainly employed to active the VCU.
🎥 Raspberry Pi setupThis project uses a Raspberry Pi with a PiCam as a satellite camera. We use the Raspbian lite image, now called Raspberry OS Lite. The camera is connected through the camera socket. The Raspberry Pi foundation provides detailed documentation about how to install the PiCam.
The satellite camera is used to capture video and expose it using GStreamer. The video is encoded in H264 since it is an efficient and popular video format, which is compatible with the ZCU104 decoder. We use the Real Time Streaming Protocol (RTSP) to expose the video in the ethernet network. A detailed instructions to set up a rtsp server in the raspberry pi can be found here and here.This project uses a Raspberry Pi with a PiCam as a satellite camera. We use the Raspbian lite image, now called Raspberry OS Lite. The camera is connected through the camera socket. The Raspberry Pi foundation provides detailed documentation about how to install the PiCam.
Here is how we launched th RTSP server in the Raspberry Pi:
pi@raspicam:~ $ nohup ./gst-rtsp-server-1.14.4/examples/test-launch --gst-debug=3 "( rpicamsrc bitrate=8000000 awb-mode=tungsten preview=false ! video/x-h264, width=640, height=480, framerate=30/1 ! h264parse ! rtph264pay name=pay0 pt=96 )" > nohup.out &
pi@raspicam:~ $ tail -f nohup.out
92:09:43.047083746 15112 0x70904c90 FIXME rtspmedia rtsp-media.c:2434:gst_rtsp_media_seek_full:<GstRTSPMedia@0x70938188> Handle going back to 0 for none live not seekable streams.
92:09:45.256081699 15112 0x70904c90 WARN rtspmedia rtsp-media.c:4143:gst_rtsp_media_set_state: media 0x70938188 was not prepared
118:11:29.069032950 15112 0x72d076f0 FIXME default gstutils.c:3981:gst_pad_create_stream_id_internal:<rpicamsrc12:src> Creating random stream-id, consider
implementing a deterministic way of creating a stream-id
118:11:29.390741337 15112 0x70904b50 FIXME rtspmedia rtsp-media.c:3835:gst_rtsp_media_suspend: suspend for dynamic pipelines needs fixing
118:11:29.405822032 15112 0x70904b50 FIXME rtspmedia rtsp-media.c:3835:gst_rtsp_media_suspend: suspend for dynamic pipelines needs fixing
118:11:29.405957865 15112 0x70904b50 WARN rtspmedia rtsp-media.c:3861:gst_rtsp_media_suspend: media 0x72d70158 was not prepared
118:11:29.493068865 15112 0x70904b50 FIXME rtspclient rtsp-client.c:1646:handle_play_request:<GstRTSPClient@0x7136b098> Add support for seek style (null)
118:11:29.493469437 15112 0x70904b50 FIXME rtspmedia rtsp-media.c:2434:gst_rtsp_media_seek_full:<GstRTSPMedia@0x72d70158> Handle going back to 0 for none live not seekable streams.
118:11:31.630440539 15112 0x70904b50 FIXME rtspmedia rtsp-media.c:3835:gst_rtsp_media_suspend: suspend for dynamic pipelines needs fixing
118:11:31.674769553 15112 0x70904b50 WARN rtspmedia rtsp-media.c:4143:gst_rtsp_media_set_state: media 0x72d70158 was not preparedDescription machine learning algorithms with adaptive computing
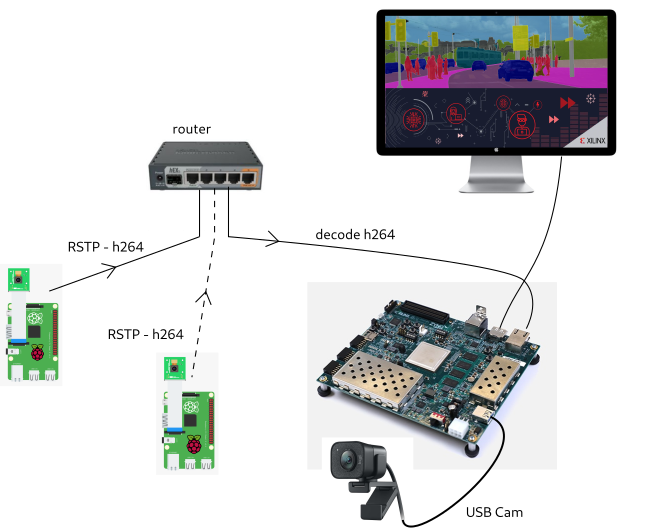
Autonomous vehicles are composed of several sensors and cameras. In this project, we use Raspberry Pi cameras as satellites that capture images from different vehicle angles. The cameras are connected to the ZCU104 throughout an ethernet network. The ZCU104 processes all the images, through compressed frames, running a deep learning model that detects objects and draws extra information about the surrounding environment, which is shared to the driver.
Although it’s possible to run machine learning models on the Raspberry Pi without the Zynq, the performance is very limited and the device might suffer from overheating, which could damage the device if it’s exposed during long periods of time. Therefore, it’s better to set the raspberry pi to serve as an image receiver and let the ZCU104 run the heavy calculation. The main challenge of this competition is to combine images coming from the different camera sources using the ZCU104 to produce useful insights that could be employed by an autonomous car to make real-time decisions in a rural and urban mobility scene.
The ZCU104 performs the following tasks:
- Connect to satellite cameras, and decode H264 video streams using the VCU unit.
- Run deep learning models on the received video streams.
- Calculate distance with surrounding objects.
- Warn the driver about objects that might be close to the vehicle using a web interface.
Notice that all the calculations are performed in the edge device, so there is no need to send data to the cloud, avoiding network latency problems and making the system completely autonomous regarding internet connection availability.
The deep learning computation is done using Vitis AI. Xilinx provides advanced programming on the edge API in order to run machine learning models. These API are Python and C++ wrappers that allow users to use FPGA to run machine learning models. We use yolo V3 object detection algorithm trained with the Pascal Visual Object Classes (VOC) dataset. It’s a lightweight model which allows us to detect 80 types of objects including cars, trucks, buses, between others.
The fact of having two cameras allows us to estimate the distance between the cameras and object by using the focal-length equation. We can use the size of the detected objects in both images, the focal length which is a constant that depends on the camera and then we can calculate the distance of the object to the camera. You can find more details about the mathematical explanation in this article and this one.
If only one camera is in use, then there is a need to know the real size of the object in order to estimate the distance between the object and the camera. In the pyimagesearch website, you can find a nice explanation about this use case.
We developed a web interface that collects all the results from the backend and exposes them in a frontend application that can be shown in any device connected to the same network. The following image shows how the web interface looks like:
Programming Flow
In order to develop accelerated machine learning applications within the ZCU104, it is important to understand the relationship between PetaLinux, Vivado, and Vitis AI. The embedded software acceleration flow starts with the exportation of Hardware Description FiIe (HDF) or the Xilinx Shell Architecture (XSA) from Vivado, which contains the board’s flashing program, and the Programmable Logic (PL) and Processing System (PS) configuration. The idea behind this process is to create a wrapper to generate a bitstream with the aforementioned settings. Once this process concludes, then it is possible to export the hardware file. With this file, PetaLinux will create a customized embedded Linux flashable version to manage the hardware resources within the ZCU104. The commands to create the PetaLinux project are the following:
$ petalinux-create -t project -s <path-to-bsp>Where -t stands for type, which in this case is a project, -s stands for source, which refers to the location of the Board Support File (BSP).The BSP file for the ZCU can be downloaded directly from the Xilinx’s PetaLinux website. It is really important to mention that the user MUST conserve consistency between the PetaLinux and BSP version. For this project, we have employed the version 2019.2 for either the PetaLinux and BSP in the ZCU102 and ZCU104 development kits.
After compilation, the hardware programming image can be generated through the build of the PetaLinux project using the following command
$ petalinux-buildA brief but robust detailed documentation about PetaLinux can be found here. In order to boot the image into the SD-Card, it is necessary to mount the SD card on the host programming computer and copy the BOOT.BIN and image.ub file to the SD card. Those files can be found on the petalinux’s building directory:
/petalinux-build-ZCU104-directory/pre-built/linux/imagesIn the following graph is depicted the relationship between the development tools for this project. As depicted, once the ZCU104 has been flashed through the SD Card, then the development of the accelerated machine learning algorithm can start. The Vitis AI Integrated Development Environment (IDE) uses the hardware specification XSA file from Vivado, which will create the Domain environment where application to be accelerated can be ported. The form in which Vitis was designed, by separating hardware and software, allows the user to develop and implement accelerated machine learning applications on different Xilinx platforms without major configuration changes. A vast documentation about Vitis AI can be found here.
VCU hardware modelIn order to use the Video Coder Unit (VCU), it is necessary to configure the XSA in Vivado to set on the VCU Hardware IP Core in the case of the 2019.2 version. From the 2020.1 on, the VCU Core comes inside the IP block generation. In the following picture is depicted the Coded with PL integration within the IP integrator for a subsequent usage in Vitis. Then, the HDL wrapper is created and finally, the XSA file is exported to either flash the board and to initiate a software domain in Vitis.
At this point, it is really important to highlight the relevance of the VCU inside the ZCU104 for image processing. Normally, in semantic segmentation or merely object detection applications, the raw data is not received and transmitted as video, but as compressed video frames, each of them containing a huge number of pictures. The compression is important since it eases the storage and transfer of the frames from the snapping device to the processing unit. Nevertheless, its usage triggers design complexity because additional operations in hardware and software must be executed to get the data back in a convenient format for its manipulation. With the Codec inside the PL of the ZCU104, the designer can transmit and receive video streams by exploiting the on-chip UltraRAM, which enables embedding video partitions in the processing algorithm. Additionally, its flexibility permits to encode and decode 4k video resolution at 60 frames per second through software using images stored in the built-in DDR memory of the PS, PL, or a combination of them.
In our case, the capturing camera is working at 1080p 60 Hz resolution. Therefore, by checking the documentation, the following memory interfaces and control interfaces must be enabled to generate the XSA file for the ZCU104.
- M_AXI_ENC0 & M_AXI_ENC1 — AXI4 encoding memory interfaces.
- M_AXI_DEC0 & M_AXI_DEC1 — AXI4 decoding memory interfaces.
- S_AXI_LITE — APU control interface for VCU configuration.
- M_AXI_MCU — MCUs and APU interfaces for communication with the VCU.
The object detection algorithm relies on the DNNDK version of Vitis AI, the code is available in the project repository. Vitis AI documentation provides useful examples in order to run different models from the AI model Zoo. For our use case, object detection using the yolo v3 model has a latency of 75 ms for single thread application, which corresponds to 13.3 FPS, which is not real time but Xilinx provides several tools to improve performances such as model pruning, which can reduce model weight up to 70% without reducing model precision. This optimization is available in the AI model Zoo for the yolo V2 model, which has a latency of 11 ms, corresponding to 90 FPS. Therefore, this model is able to handle more than two image sources delivering real time object detection.
The latency obtained for the model inference can be compared with other devices such as the Jetson Nano, where the inference of the model SSD Mobilenet v2 inference took 47ms or the Raspberry Pi 3B, where the interference of the same model took 1.48 seconds. Meanwhile, the ZCU104 has a latency of 38ms for the same model in the baseline and it’s expected to be around 17ms for the pruned version of this model.
ConclusionsDuring the realization of this project, we have shown how Xilinx's UltraScale+ MPSoC architecture is highly suitable to execute machine learning applications applied for autonomous driving, using the ZCU104 development kit. Our proof of concept has shown that object detection and image segmentation with built-in video distance depth can be efficiently accelerated by exploiting the integrated VCU hardware IP core, and the pipelining inside the PL during the execution of the image processing application.
From the hardware perspective, we have shown that the VCU has to be set up according to the resolution and refresh rate of the incoming video stream. The flexibility offered by this IP core allowed us to receive the raw data stream without the need of further data decompression.
For some future work, it is expected that we will focus our attention on hardware optimization during the preprocessing phase based on exploiting low precision support for arithmetic operations. Consequently, we expect to scale up performance, while reducing the required on-chip bandwidth and hardware resources. However, some challenges such as irregular patterns of memory access have to be taken under consideration during the activation of the inference engine.
From the software perspective, collision avoidance systems are one of the most challenging use cases, where the inputs come directly from multiple cameras and also from distance sensors around the vehicle. Dealing with such data is not a trivial task:
- Analysis of an heterogeneous environment full of distinctive objects.
- Deep learning image segmentation algorithms are needed to process the data, while prediction algorithms are required for decision-making.
This highly computational intensive use case can not be tackled using conventional hardware architectures such as neither x86 architectures nor hardware with high power consumption requirements like NVIDIA or AMD’s GPU devices. Therefore, with this project we demonstrated that Xilinx’s Zynqs is a valid alternative to the aforementioned architectures to tackle the autonomous driving challenge in terms of throughput, power consumption and latency.
At this point, we permit us to make comments about this architecture in order to dissuade hardware designers about the need of improvements in certain areas of the development flow. Although programmability has been eased considerably by the hardware customization and the introduction of software domains, it still requires medium to advanced knowledge on the area to be able to work with this platform. Therefore, proliferation of software API is still needed in order to attract programmers. In this regard, it is expected that the latest release of the software tools, the version 2020.2, for the UltraScale+ architecture solve these obstacles.
To conclude, it would be grateful to count with innovative cooling systems for the SoC because the work with the device can become challenging due to the noise levels of the fan, and perhaps the energy consumption of the development kit.
Future Work
Due to massive time limitations, many optimizations are expected to be introduced in a future work, benefiting from the vast experience gathered during the elaboration of this work. Since the ECUs set along the vehicles can not be equipped with an UltraScale+ Soc each, then it is necessary to exploit virtualization in order to share hardware resources between ECUs throughout resource managers, making the system scalable and cheaper. On the other hand, the virtualization can take place also on the data centers, also known as cloud, where programming frameworks are required to allocate Zynq resources to run Virtual Machines (VM) in order to compute many ADAS functions. This Zynq overlay must benefit from reconfigurable hardware in order to provide computing resources on-the-fly.
Additionally, we are engaged to integrate a containerization such as a Vagrant application, in which we can attract software developers and programmers to design and implement new machine learning algorithms to enhance our object detection and semantic segmentation. With this application, we pretend to provide a portable environment, in which a person with zero or limited hardware knowledge can run our application employing a simple script and the processing hardware, which for the purposes of this project was the ZCU104.
Finally, our last ambition is to make our web application robust enough in order to attract no geek people to this challenge of the mobility of the future. We would like to add features to our application in which the user can use its mobile communicator phone as an edge device to capture data that will be manipulated in Xilinx-equipped data centers. We certainly believe that the only way to bring FPGA technology to the masses heavily depends on the ability to develop applications that an average customer can use without incurring in highly complicated technical details about hardware-software codesign. Therefore, we believe that this is the way to go through in order to compete with GPUs, and ASICs.




{kind=link}
Comments