


Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
Hand tools and fabrication machines | ||||||
 |
| |||||
We all know and love the "Hey Google"s and the "Hey Alexa"s to trigger our smart home devices to wake up, but with the right application, we can trigger our electronics to perform many more complex actions using only our voices. Examples include turning on your lights with a voice command or perhaps sending a message to your kids upstairs to tell them that dinner's ready.
To that end, I will be using a tiny embedded microprocessor that will be able to recognize key words such as "on" or "off" so that once the microprocessor recognizes these words, they will be able to activate or deactivate an attached electronic device, respectively. This project will only focus on the implementation of a microprocessor to recognize such words; attaching another device to the microprocessor is beyond the scope of this project, but it is an avenue of direction this project encourages the readers to explore.
In order for the microprocessor to recognize wake words, we require a machine learning model that will assist us in this endeavor. In practice, we will train a machine learning model to be able to recognize words that we determine the model should recognize, then we have to shrink it down to the point where we can fit the entire model all into our microprocessor. The board that I will be using for this project does not contain a substantial amount of storage space; in fact, this storage space restriction is so extreme that we need to figure out a way to not waste a single bit. To give you an idea of how extreme this restriction is, the final model is only around 18 KB, and that is nearly pushing the amount of space the microprocessor has in its flash memory! Thankfully, we have tools such as Tensorflow Lite that will assist us with shrinking down the trained model we will eventually produce with Tensorflow.
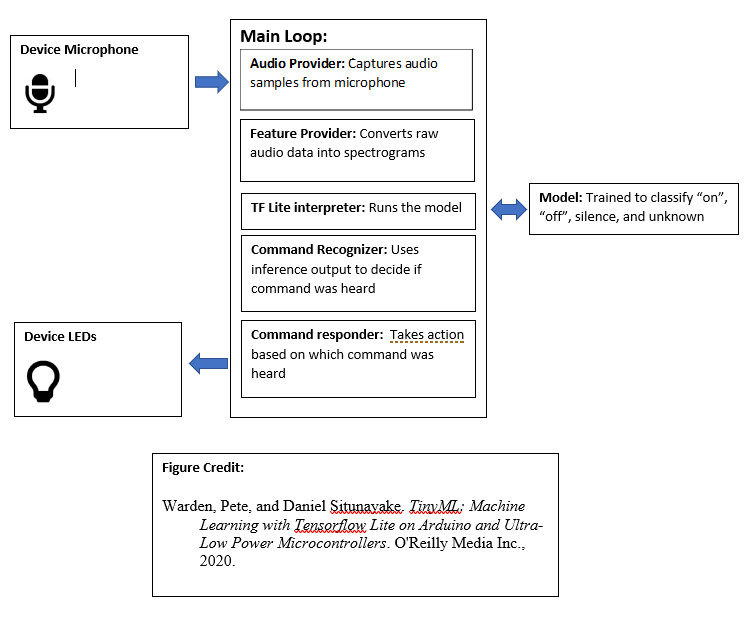
Methods:To start, I got the base model from the examples from the book titled TinyML: Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Microcontrollers [1]. The model in question is the Arduino version of the Wake Word Detection model titled micro_speech. The board that will house the model is an Arduino Nano 33 BLE Sense (I have the version with headers, but this project should be compatible with a board with no headers), and I used the Arduino IDE to link the model to my board.
Training the model was fairly straightforward. The dataset used to train the model was graciously provided by Google; it contains 65, 000 one-second long utterances of 30 short words, by thousands of different people [2]. To train the model, I used a total of 15, 000 training loops, of which 12, 000 of them involved a learning rate of 0.001 and the other 3, 000 loops involved a learning rate of 0.0001. The reasoning for this is so that we can first build up the foundation of the model using 12, 000 training loops, and then fine-tune the model with 3, 000 learning loops. The higher the learning rate, the faster the model can learn the dataset, but the trade-off is that it won't be as accurate against a model trained with a lower learning rate. The model took around 2 hours to train with a provided Nvidia Tesla Kepler K80 that Google Colaboratory (the platform that this model was trained on) has provided us.
The model that is used in this project consists of a convolutional layer, followed by a fully connected layer, and then a softmax layer at the end. Convolutional Neural Networks (CNNs) are classically used for image processing on a multitude of occasions, which makes perfect sense to apply it on our model which takes in 2D image representations of the spoken words in the dataset. The dataset is transformed via feature generation so that the dataset is easier to work with. In a nutshell, the feature generation used in this model generates a Fourier transform for a given time slice which has been filtered with a Hann window. The model then produces 256 frequency buckets with the information produced by the Fourier transform and then averages the frequencies in the buckets into 40 downsampled buckets. The model uses the human perception-based mel frequency scale to give more weight to lower frequencies so that there are more buckets available for them, and higher frequencies are merged into broader buckets. This averaging is also used as a sort of noise reduction. The model then uses PCAN auto-gain to boost the signal based on the running average noise, and then the model applies a log scale to all the bucket values. This process is repeated 49 times in total to product an array that has dimension 49x40, which will represent our singular convolutional layer. You can find more information about the model itself in Chapter 8 of the cited book [1].
The convolutional layer of the model consists of 8 filters, each layer consisting of 10x8 pixels. The input is a 49x40 pixel image with a single channel, and the output of the convolution is half the size (25x20 pixels). Our fully connected layer has 4, 000 values, represented as 25x20 pixel images * 8 filters. In a nutshell, the fully connected layer has a weight for every value in the input tensor, which will perform pattern matching to one of the output classes we have designated. Our last layer is a softmax, which will, in a nutshell, give us a "probability" of where the output should map to. The model uses the ReLU activation model to perform its training. Again, you can find more information about the model itself in Chapter 8 of the cited book [1].
Results:The model is able to detect the words "on", "off", unknown words, and silence, albeit the board seems to not able to detect the wake words from a bit of a distance; the board seems to be able to detect the wake words closer to the source with better accuracy. As you can see from the demo video, the board will shine a green LED when it hears the word "on", a red LED when it hears the word "off", a blue LED when it detects an unknown word, and nothing when it detects... nothing. The serial monitor from the Arduino IDE also outputs what word it detects when the board is connected to the computer and the IDE is opened.
References:1. Warden, Pete, and Daniel Situnayake. TinyML: Machine Learning with Tensorflow Lite on Arduino and Ultra-Low Power Microcontrollers. O'Reilly Media Inc., 2020.
2. Warden, Pete. “Launching the Speech Commands Dataset.” Google AI Blog, 24 Aug. 2017, https://ai.googleblog.com/2017/08/launching-speech-commands-dataset.html.






{kind=link}
Comments