


Software apps and online services | ||||||
 |
| |||||
The world we live in is not a Disney movie where animals (excluding homo sapiens) live in harmony with no human intervention. Animal extinction is real and as many as 99% of the species at the threshold of extinction are there due to our (human, and that includes you too) activities[1]. Elephants are facing the same problem. these gentle giants are being hunted for their ivory tusk and fun.
With the help of technology, we can solve this problem. Technology can help in preventing elephant poaching. It can provide insights for their conservation.
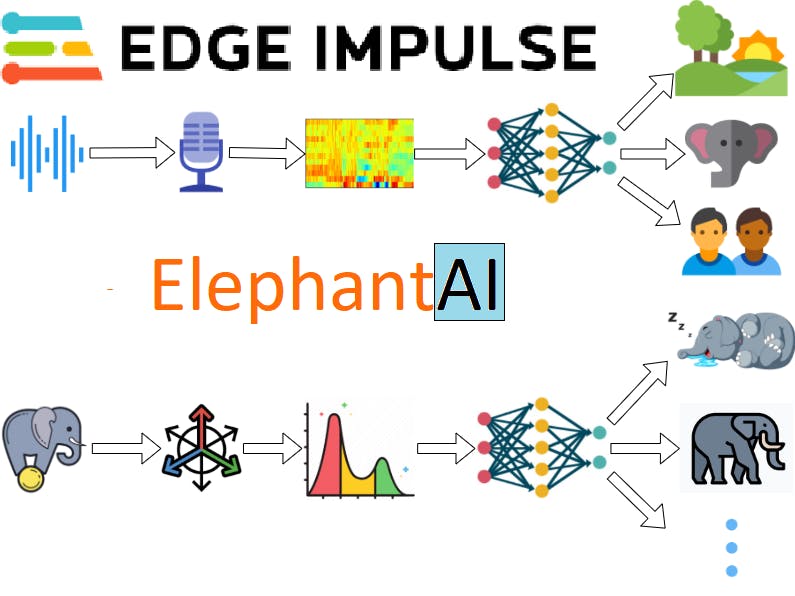
2. A SolutionA solution we present here is a machine learning algorithm designed using Edge Impulse Studio. This algorithm is designed to be deployed on an elephant tracking collar by Smart Parks. The tracking collar is developed by IRNAS and has a lot of sensors built into it. Two of those sensors are a microphone and an accelerometer.
We have developed two machine learning algorithms to use these sensors and provide useful information. The algorithms are
2.1 Human Presence Detection
- This algorithm aims to avoid potential poaching by detecting the presence of a human using sound. If an unauthorized person is present around an elephant then it is not a good sign for either's safety.
- This algorithm uses MEMS audio sensor to record sound and use a machine-learning algorithm to detect human presence.
2.2 Elephant Activity Monitoring
- This algorithm aims to monitor elephant activity. Monitoring an elephant's activity can help us in their conservation.
- This algorithm takes time-series input from an accelerometer sensor and uses a machine-learning algorithm to identify the elephant's activity.
- At the moment the activities this algorithm can detect are walking and resting. The same algorithm can also detect other activities like running, sleeping, etc. if more training data is provided.
Both of these algorithms work independently. They take input from different sensors and generate two distinct outputs.
3. Human Presence DetectionThis algorithm uses sound to detect the presence of a human. The MEMS microphone(step 2) of the tracking collar will pick up sounds present around an elephant and will send it to the preprocessing algorithm(step 3). This preprocessing algorithm generates MFCC of that sound clip. The generated MFCC is then sent to a Convolutional Neural Network(step 4). The convolutional neural network with the help of a fully connected neural network classifies the audio into three classes(step 5)
- Human
- Elephant
- Other
Based on the classified class a smart park manager can decide on what to do next.
3.1 Data Gathering and Preprocessing
We gathered voice samples from multiple places and prepared the dataset for training and testing. Our voice dataset contains three classes
- Elephant
- Human
- Other
Thanks to Elephant Voices for providing Elephant's voice dataset. Human and Other class data are captured from Youtube.
You can download the voice dataset from here.
We uploaded the training and testing data to the Edge Impulse via its Data Acquisition feature. We cropped and split the samples to remove unwanted sounds.
This cleaned data is then preprocessed on Edge Impulse to generate MFCC. The generated MFCC can be visualized using Feature Explorer in Edge Impulse
3.2 Neural Network
The Neural Network we developed for sound classification is a combination of CNN and Fully Connected Network. Building and configuring a neural network is very easy in the Edge Impulse. You only need to add a Neural Network classifier block while creating the impulse. You can modify its architecture and configure hyper-parameters from the NN classifier tab under Impulse Design.
We have tried multiple combinations of network architecture and data augmentation about which we will discuss in the next section. Before that let us point out the assumptions and some pre-settings.
- From Figure 4, we have fixed the window size of 2000 ms. and window increase of 500 ms. for the sampling of the training and test data keeping in mind not just the memory constraints of input features in Edge Impulse but also the real-case scenario where, for example, the device can record and make predictions every 2 seconds. (Further possibilities include treating these predictions as time-series points and making some other predictions and analysis. We haven't tried this method though.)
- Training cycles and learning rate values were carefully chosen for every experimented architecture separately so that the network gets enough epochs to learn.
- For every architecture, we have set the minimum confidence score for the predictions as 0.50. It should be noted that the choice of this value significantly affects the test accuracy.
3.3 Testing and Outcome
We experimented with various Convolution Neural Network (CNN) architectures possible in Edge Impulse and analyzed the performance both in terms of accuracy and resource usage which are discussed in this section.
3.3.1 Performance of 1D convolutions
In the first set of experiments, we define a CPD block as shown in Figure 9 which consists of Convolution, Pooling, and Dropout layers. There is a single convolution layer of 1D convolutions with 3x3 kernel size and number of neurons (filters) in multiples of 8 (starting from 8). Therefore, when we say 2 CPD blocks, the first one will have a convolution layer with 8 neurons (filters) and the second one will have the same configuration with 16 neurons (filters).
In Figure 10 we show how increasing the complexity and 'deepness' of the neural network affects resource usage like inference time, RAM, and ROM usage which are important numbers when talking about inferencing on edge devices which are low in both power and compute.
- With an increase in the number of CPD blocks the test accuracy shows an upper bound of 85.78% on the described data and defined settings for testing. It decreases to 4 CPD blocks and slowly increases from there.
- Making the network deeper linearly increases the inference time by approximately 3 ms. with the addition of one CPD block.
- Correspondingly, RAM usage also follows a linear pattern although less steep than inference time with an average increase of 1.5 KB with the addition of one CPD block.
- ROM usage, however, doesn't seem to follow an upward trend in our experiments and so we conclude that approximately 68.2 KB of ROM might be consumed by similar architectures as above.
So, from the above observations, we conclude that the best architectureinthis set of experiments is the one with 3 CPD blocks with 85.78% test accuracy, 16 ms. of inference time, 8.3 KB of RAM usage, and 68.9 KB ROM usage.
3.3.2 Performance of 2D convolutions
In this part, a CPD block from the previous section is modified to contain a single convolution layer with 2D convolutions, 3x3 kernel size, and the number of neurons (filters) in multiples of 4 (starting from 4).
In Figure 12 we show how increasing the depth of the network by appending the CPD block of 2D convolutions affects the resource usage and performance of the model.
- Increasing CPD blocks definitely increases the performance but after 3 blocks it increases by a tiny amount. So, with 4, 5, and 6 CPD blocks test accuracy is between 86% - 87%.
- Making the network deeper increases inference time which follows a saturating exponential pattern.
- Impressively, RAM usage follows a flatter linear pattern with an average increase of only 0.5 KB with the addition of one CPD block.
- ROM usage follows a strange pattern where it decreases with the increase in the number of CPD blocks. A simpler network consumes 4x more ROM than the most complex one.
So, from the above observations, we conclude that the best architecture inthis set of experiments is the one with 4 CPD blocks with 86.19% test accuracy, 42 ms. of inference time, 10.3 KB of RAM usage, and 43.7 KB ROM usage.
3.3.3 Varying thenumber ofConvolution layers
In the second set of experiments, we used the network architecture depicted in Figure 13 where the number of convolution layers before the polling layer inside a single CPD block is varied keeping the number of neurons the same. There are two CPD blocks first with convolution layers of 8 neurons and the second with 16 neurons. We discuss performance metrics related to these settings below.
Edge Impulse provides settings to add up to 3 contiguous convolution layers and we report results on these settings in Figure 14.
- Increasing layers from one to three showed a jump in the test accuracy of almost 3%.
- Although inference time increased linearly, the magnitude of an average increase of 8.5 ms. with each added convolution layer is significant.
- The average RAM usage increase in this case also is impressive with only 1.7 KB per layer.
- The average ROM usage increase with the number of layers is around 2.2 KB.
So, from the above observations, in this set of experiments, the best model is the one with 3 convolution layers (before the pooling layer) with 85.02% test accuracy, 30 ms. inference time, 10.2 KB RAM usage, and 79.4 KB ROM usage.
3.3.4 Data augmentation
In this set, we tried different data augmentation settings in Edge Impulse and report their effect on the accuracy of the model. Here we used the same architecture depicted in Figure 8 with one convolution layer.
With the obvious increase in training time, the decrease in the test accuracy with data augmentation, however, came as a surprise as shown in Table 3. We did not try to add noise as the original audio samples contain natural background noise at many time frames. We vary masking of frequency from none to high with the warping of the time axis in one of the settings. Evidently, data augmentation has no effect on inference time and hardware compute usage.
4. Elephant Activity MonitoringThis algorithm uses an accelerometer sensor to detect the elephant's activity. The sensor gathers the acceleration in the X, Y, and Z axis (step 2) and sends it to the preprocessing algorithm. Spectral analysis is performed on the acceleration data at the preprocessing step(step 3). This preprocessed data is then fed into a Fully Connected Neural Network(step 4). The neural network then classifies the data such as
- Standing
- Walking
- Other
Note: The attached neural network model is trained only on 3 types of activity data (a) standing, (b) walking, and (c) other.
4.1 Data Gathering and Preprocessing
Disclaimer: We could not find the accelerometer data set for the elephant's activity. Therefore we created our own dataset based on human activity. The same neural network model can be used for training on the elephant's activity data.
Edge Impulse provides some very handy features for data collection. It supports some popular development boards for data collection and inference. You can even use your smartphone and that is what we did for preparing the activity dataset.
Data Collection Device Information:
- Company: Oneplus
- Model: Oneplus 6
- Accelerometer Sensor: BOSCH - 34744578
Data is collected for 3 activities:
- Stand
- Walk
- Other
Each sample in the dataset is 10 seconds long and the device was placed in the front trouser pocket while collecting data.
You can download the accelerometer dataset from here.
The data is then preprocessed using the Spectral Analysis block in Edge Impulse itself.
4.2 Neural Network
The neural network used for activity classification is extremely simple. The network contains only four fully connected layers constituting an input layer with 30 neurons, two hidden layers with 20 and 10 neurons respectively, and one output layer with 3 neurons. We used the learning rate of 0.0005 and trained the network for only 30 epochs.
The ReLu activation function is used for hidden layers and to optimize the network Adam optimizer is used.
4.3 Testing and Outcome
The neural network model we developed for activity monitoring performed extremely well. The training and test accuracies we received are almost 100%, too good to be true!
The developed neural network model can be found here.
5. ConclusionBy looking at the set of experiments performed for both the algorithms we present our final conclusion here.
By looking at table 4 we can say that for the "Human Presence Detection", the best model is "Three 1-D CPD blocks and a Dense Layer" because it outperforms other models in terms of RAM usage and inference time and has only 0.41% less accuracy than the most accurate model.
The neural network model with "Three 1-D CPD blocks and a Dense Layer" architecture is available here.
For our voice dataset and models, the data augmentation did not have any effect.
For "Elephant Activity Monitoring" our fully connected network described in section 4.2 is performing best with 99.47% test accuracy however it is trained/tested on the human activity data and not on elephant activity data. To train and test this model we will need activity data of multiple elephants.
6. Reference- [1] worldanimalfoundation.com/wild-earth/extinction-crisis/
- Elephant Voice - https://www.elephantvoices.org/
- Edge Impulse - https://www.edgeimpulse.com/
- Our Datasets and Models - https://drive.google.com/drive/folders/17vRxvCc-ZCzkVpVxsZgwp9buepUrnpgE?usp=sharing






Comments