
Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
In this project we will build a camera that automatically describes what it observes. The main aim is to build the AI part of a system that can be used for automated surveillance using edge devices such as Jetson Nano.
Back in 2016 in a Google paper named "Show and Tell" researchers showed how to couple a Convolutional Neural Network (CNN) with a Long Term Short Memory (LSTM) network to provide automatic captioning (textual descriptions) of images. In this project we will extend this idea to real time video. An AI network running on an edge device such as Jetson Nano will be deployed such that it continuously provides textual descriptions of acquired frames. The textual descriptions will be used to trigger actions based on the described objects.
All of this is done with no requirements for network connectivity so such a system can be installed in remote areas that requires AI supervision of surroundings.
IntroductionThe complete design implements an automatic image captioning neural network applied to real time video using the latest Tensorflow version on a Jetson Nano edge computing device. To keep the implementation simple, advanced features like attention are not implemented although they can be added to the network since the main script is fairly modular.
A hybrid deep neural network will be implemented to provide captioning of each frame in real time using a simple USB cam and the Jetson Nano.
Project Design PhasesThe project will be setup in four phases. During the first phase we will setup and train the network on a host computer equipped with a discrete graphics card. The second phase consists of setting up Jetson Nano and implementing a simple image pipeline from camera to the HDMI monitor. The third phase includes integrating the image captioning deep neural network with the image pipeline from phase two. And finally during the last phase we will test the network on real world settings.
The hardware requires supplying the Jetson Nano with a 2A power supply since powering it from USB is insufficient to run the neural model in high performance mode. To do this, make sure to install the jumper on the right side of Jetson Nano. Then plug in a USB cam, an SD card with the latest image and the Ethernet cable. Once the hardware is setup, the next step is setting up the prerequisite frameworks.
Host SetupFirst we will define and train the network on a host laptop. The project will make use of Tensorflow 2.01, Keras 2.1 and OpenCV 4.1. A pre-requisite is to install Cuda10.0 and Visual Studio Express 17.0 to leverage the GPU speed gains in case the laptop comes with an NVIDIA enabled GPU.
The data-set we will use for training is the Flickr8K image data-set. This is a relatively small data-set that allows one to train a complete AI pipeline on a laptop class GPU. One can also use larger data-sets which will allow for better performance at the expense of much higher training time. The data-set can be downloaded from the University of Illinois via the request form.
The next data-set is the Glove data-set which is a set of word embedding build from a large corpus of text. This data-set essentially serves as the dictionary from which the AI picks up its vocabulary. After the caption text cleanup is done, the next step is to load the Glove embeddings. Embeddings are encodings of words that are used by neural networks. Basically words are projected as vectors in a high dimensional space and then represented as vectors. Download the data-set from here:
https://nlp.stanford.edu/projects/glove/
Then create a top-level directory named /Captioning and extract both zipped files in there.
In addition create a folder named /data for saving the files generated during the training phase. Next we will define the network and train the network.
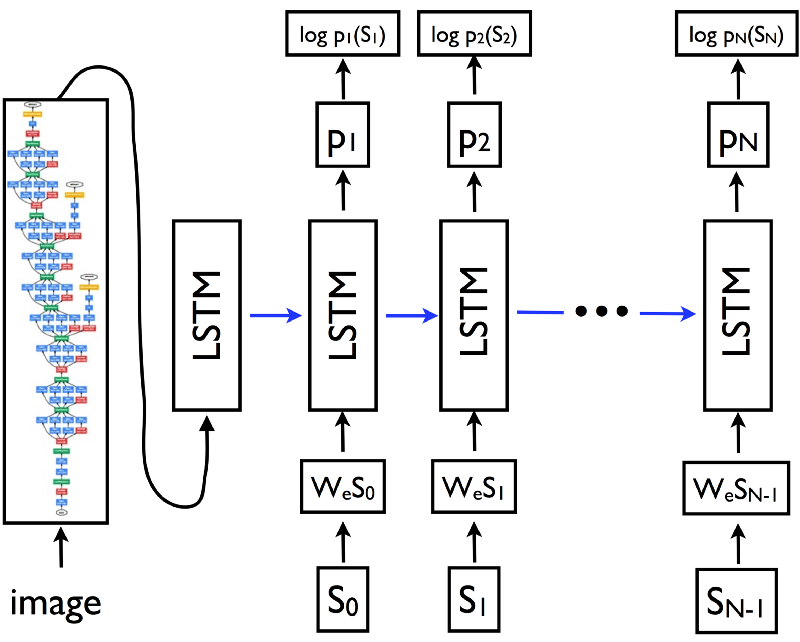
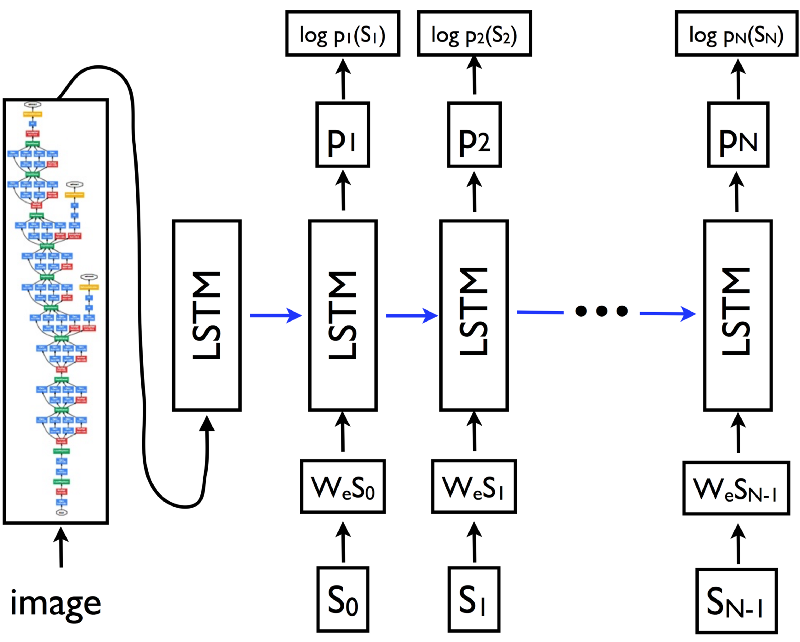
Neural Net TrainingFrom a high level perspective the image captioning deep learning network consists of a deep CNN (InceptionV3) and an LSTM recurrent neural network daisy chained together. The output of CNN is a x-dimensional vector which represents an image class. The output is sent to an LSTM which generates a textual description of the objects in an image. The LSTM basically receives a stream of x-dimensional vectors. Based on this it strings together a description of the scene in real time.
The Ipython notebook that trains the network is found on Github. The design of the main network is based on work from Jeff Heaton. It consists of an InceptionV3 CNN coupled with an LSTM recurrent neural network.
The next step is to build a dataset from Flickr captions and clean all the descriptions by tokenizing and pre-processing the text. Then we split the Flickr8K dataset into test and train image datasets. Then we load the train dataset descriptions and train the network.
As mentioned, the Inception network is used as the first stage of the network. The last fully connected layer is removed so the data that comes out from the first stage CNN is a one-dimensional vector. Inception can only accept images that come with a resolution of 299x299 pixel so the camera images have to be formatted.
inputs1 = Input(shape=(OUTPUT_DIM,))
fe1 = Dropout(0.5)(inputs1)
fe2 = Dense(256, activation='relu')(fe1)
inputs2 = Input(shape=(max_length,))
se1 = Embedding(vocab_size, embedding_dim, mask_zero=True)(inputs2)
se2 = Dropout(0.5)(se1)
se3 = LSTM(256)(se2)
decoder1 = add([fe2, se3])
decoder2 = Dense(256, activation='relu')(decoder1)
outputs = Dense(vocab_size, activation='softmax')(decoder2)
caption_model = Model(inputs=[inputs1, inputs2], outputs=outputs)The code snippet above shows the edited InceptionV3 CNN concatenated with the LSTM. This implements an encoder-decoder architecture.
Once this is done, we have to loop through the training and test image folders and pre-process each image.
The last part of the network is a re-current long short term memory neural network. (LSTM) for short. This network takes sequences and tries to predict the next word in a sequence. Work on these types of networks was done by A. Karpathy at Standford who pointed out how adequate they are for such tasks.
The last step is to train the network. For this project initially 6 epochs were used with the loss being 2.6% initially. To get acceptable results however the loss has to be much less than 1 so one has to train for at least 10-15 epochs.
After the network is trained we load the trained weights and test the network on test images from the data-set as well as images which are not part of the original data-set.
If the images are very similar in style and content with the images from the Flickr9K dataset the descriptions are relatively accurate. If the content is different in style the network will probably give descriptions which are plain non-sense.
The training phase concldues the first phase of the project. At this point you have an exported Keras model with the weights as well as the pickle files for test and training. All the data under the /Captioning folder can be uploaded on the Jetson Nano using WinSCP.
Jetson Nano Camera SetupThe second phase included setting up Jetson Nano with the camera. A USB camera with VGA resolution was used for this project.
The same version of Tensorflow 2.0, Python and Keras needs to be installed on the Jetson Nano in order to avoid compatibility issues.
sudo pip3 install --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v42 tensorflow-gpu==2.0.0+nv19.11OpenCv is used to capture frames from the camera in a continous loop. To demonstrate live image captioning on video we have to overlay text on top of the live video feed. This can be also done using the OpenCV API. First we need to install the correct version.
Installing OpenCV
OpenCv4.1 was compiled from source. This can take a while. To install version 4.1, I used the script below:
curl -L https://github.com/opencv/opencv/archive/4.1.1.zip -o opencv-4.1.1.zip
curl -L https://github.com/opencv/opencv_contrib/archive/4.1.1.zip -o opencv_contrib-4.1.1.zip
unzip opencv-4.1.1.zip
unzip opencv_contrib-4.1.1.zip
cd opencv-4.1.1/
echo "** Building..."
mkdir release
cd release/
cmake -D WITH_CUDA=ON -D ENABLE_PRECOMPILED_HEADERS=OFF -D CUDA_ARCH_BIN="5.3" -D CUDA_ARCH_PTX="" -D WITH_GTK=OFF -D WITH_QT=ON -D OPENCV_EXTRA_MODULES_PATH=../../opencv_contrib-4.1.1/modules -D WITH_GSTREAMER=ON -D WITH_LIBV4L=ON -D BUILD_opencv_python2=ON -D BUILD_opencv_python3=ON -D BUILD_TESTS=OFF -D BUILD_PERF_TESTS=OFF -D BUILD_EXAMPLES=OFF -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local ..
make -j3
sudo make installNotice that GTK was turned off, to avoid an issue with the libraries that is found when compiling with the default settings.
Once OpenCV was installed, the program was tested using the file test_openCV.py attached below. The USB camera shows up as /video0 under /dev.
After the frame is captured, text can be overlaid on top of each frame using the following function:
def __draw_label(img, text, pos, bg_color):
font_face = cv2.FONT_HERSHEY_TRIPLEX
scale = 1
color = (255, 255, 255)
thickness = cv2.FILLED
margin = 5
txt_size = cv2.getTextSize(text, font_face, scale, thickness)
end_x = pos[0] + txt_size[0][0] + margin
end_y = pos[1] - txt_size[0][1] - margin
cv2.rectangle(img, pos, (end_x, end_y), bg_color, thickness)
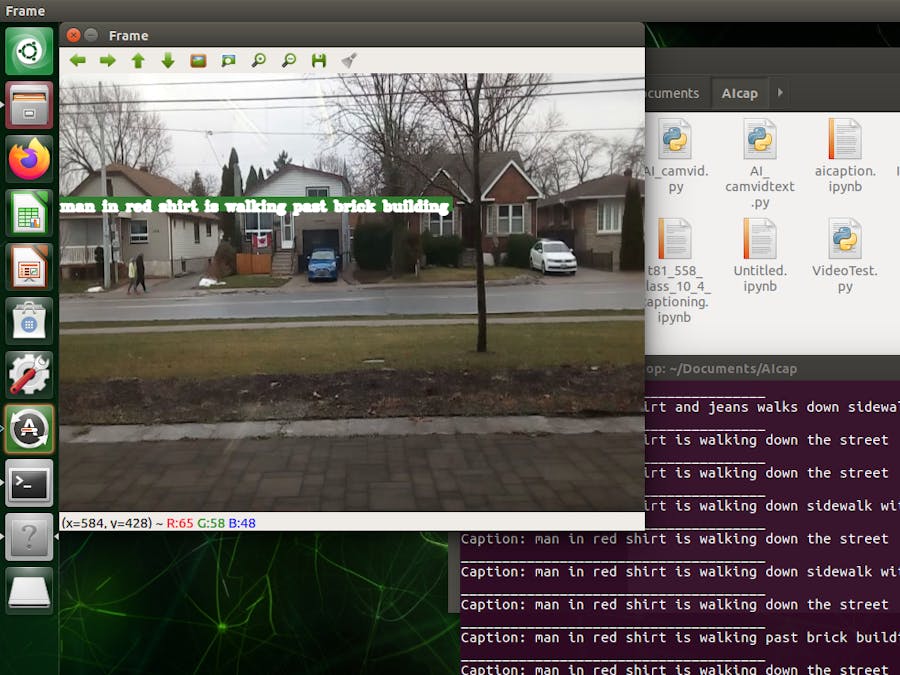
cv2.putText(img, text, pos, font_face, scale, color, 2, cv2.LINE_AA)The image below shows a frame captured from the camera with date overlaid on top of the frame.
All the images that are taken from the camera via the OpenCv API are numpy arrays. So the array has to be converted to an image, resized to match the InceptionV3 CNN requirements and then reconverted back to an image and pre-processed further. This can be avoided with cameras that have multiple programmable resolutions.
The Jetson Nano does not have a particularly powerful GPU in comparison to the latest RTX class GPU's hence, training the network should definitely be done on a host laptop.
Now that we have the basic image pipeline working on the Nano we will copy the encoded pickle file and Glove embedding on the Jetson Nano and load the image captioning trained network weights.
The basic image pipeline will be augmented with the image captioning network. Once the frame is captured the frame will be encoded from a Numpy array to an image, resized, and then converted back to a Numpy array. The image will then be pre-processed and passed through the inception network to get the encoding vector. The last step is to re-shape it so that the vector is re-formatted for the LSTM network.
while(cap.isOpened()):
ret, frame = cap.read()
framenc = encodeImageArray(frame).reshape((1,OUTPUT_DIM))
capstr = generateCaption(framenc)
print("Caption:",capstr)
print("_____________________________________")
__draw_label(frame, capstr, (0,150), (50,125,50))
cv2.imshow('Frame',frame)
if cv2.waitKey(25) & 0xFF == ord('q'):
breakEach acquired video frame is then passed through the captioning network. The textual description is then overlaid on top of the video feed in real time for demonstration.
The network requires 2-3 minutes to load since it reads and parses all the encodings. Then it reads an image frame and passes that through the network. The inference happens really fast.
The network will give out a couple of warnings based on low memory initially. Bear in mind that it is not optimized using TensorRT so further increases in speed can be gained by doing that and substituting InceptionV3 with a better CNN such as Xception.
The main avenue for the implementation of such a system would be coastal monitoring, park security surveillance and any such scenarios where an automated surveillance can be used for applications that have a positive impact resulting in saving lives and making environments secure.
Further ImprovementsThe next step is to convert the Tensorflow mode into TensorRT from NVIDIA in order to gain an additional sped up.
Since this is a modular system the output of the network can be passed to a notifier system that sends an email every time a word of interest appears on the image description.
A further development is to couple this with a conversational AI system in order to build an "Ask and describe" system.
ConclusionAs can be seen the network performs OK only in those instances where the images are similar in content to the trained images.
To improve the description one needs to use a much larger text corpus as well as a much larger annotated dataset. While the Flickr30K is almost 4x the size of the current dataset one can get much better results if using the MSCoCO dataset. The catch is that you need a powerful GPU or make use of the cloud.
{kind=link}
Comments