
Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
Hand tools and fabrication machines | ||||||
 |
| |||||
Image processing and computer vision have become well-established trends in artificial intelligence because they use the data gathered in digital images and videos to deduce information using Deep Learning algorithms. One of the main use cases of Deep Learning applied to digital images and videos is object detection, which has been applied massively in the development of self-driving cars and intelligent video analytics. For instance, the cities of the future, also known as smart cities, are supposed to deploy camera networks to provide surveillance to prevent criminality, manage traffic efficiently, and reduce energy usage. Nevertheless, the settlement of that network comes with certain challenges that need to be tackled to avoid service shortages.
The deployment of a surveillance circuit along and across a city requires high data bandwidths to send the images taken from High Definition cameras to a server, where they can be processed. However, the computation in real-time of all that information is not achievable in the majority of the cases due to bottlenecks caused by the enormous data volumes that HD cameras can generate in a set period of time. Therefore, edge computing arises as a solution to resolve this drawback by filtering and processing some information directly in the capturing device and so reducing the bandwidth utilization required for transferring data to the cloud.
Deep learning is the default method employed to draw information from digital photos and videos nowadays due to its flexible architectures to learn from raw input data, increasing accuracy in the prediction during object detection operations. Its working principle is based on multi-layered neural networks, which are trained using boundless datasets. However, training a deep learning network is a computational intensive task that requires many matrix multiplication operations in parallel. Therefore, many state-of-the-art commercial single-board computers are not suitable hardware platforms to perform the mentioned task since they are single-thread performance-optimized architectures. With the arrival of developer kits, such as the NVIDIA’s Jetson Nano, specialized on running artificial intelligence workloads, hardware is no longer a constraint in the deployment of deep learning applications.
In this project, we focus our attention on one outstanding topic in computer vision: pedestrian analysis. We made this selection based on the diverse use cases that the analysis of people behaviour can provide to local authorities to tailor the needs of the local population where this technology might be positioned. For instance, we envision the following applications:
- Counting people leaving and entering into subway or bus stations to regulate pedestrian transit.
- Counting people looking at articles in the windows of stores to establish a number of potential customers.
Counting people using deep learning algorithms is far from being a trivial task since there are many parameters to be considered while training a neural network. For example, the height where the capturing camera is located can perturbate the quality of the snapshot introducing noise to the picture, making it harder to keep track of each pedestrian in the photo’s scene. Consequently, the training phase might imply further steps to identify attributes about the images.
SolutionIn order to overcome those challenges, we propose a NVIDIA’s Jetson Nano-based solution to count the people passing in front of a camera. The working principle of our algorithm is based on the following tasks:
- Image capturing at high snap rate.
- People detection at diverse frame rates.
- Tracking each detected person to be associated in the next data frames.
- Counting individuals by differentiating them on each snapshot.
Besides the people counting algorithm, a web-based application has been developed to monitor tracking and counting results using diverse parameters selected by the user.
Project PlanningThis project employs a camera that captures seamlessly images from the street and transfers them to the NVIDIA’s Jetson Nano for further processing. Apart from the image processing, the Jetson Nano hosts a web-based application, which can be accessed by all the devices connected to the internet network where the application is hosted. This project requires a camera that captures images from the street and transfers them to the Jetson Nano in order to process the information.
In this section are listed the hardware components required to develop this project:
- Jetson Nano Developer Kit
- Jetson Nano Waveshare Metal Case (Type B)
- IMX219 Sensor 160 Degree 8MP Webcam
- Wireless card AC8265
- MicroSD card
You can find here the instruction to assemble the Jetson Nano in the Waveshare metal case.
NVIDIA’S Jetson Nano comes with a Software Development Kit, known as Jetpack 4.3.1, which is a variation of the GNU/Linux Ubuntu operating system, used for building artificial intelligence applications. The installation instructions of this SDK can be found in the following link.
The application has 2 main components:
- A python-written backend application.
- A typescript-written frontend application based on the Angular 8 framework.
The backend application performs the following tasks:
- Capturing the frames from the camera source.
- Loading an object detection algorithm.
- Running the inference on each frame.
- Filtering images images.
- Exposing the results through an API.
The frontend application instead uses the backend’s API to render the results and to process the captured data. In the following sections, the backend and frontend application will be described minutiously, highlighting every of its components. The reader can find the entire source code at the end of this article.
The fastest way to fetch data captured by a camera into the NVIDIA’s Jetson Nano is by using the gstream-lib library, which sets from the streaming source from a plugged-in CSI camera. The streaming source is read by OpenCV’s VideoCapture functions by fetching image data from the specified buffer in the device’s memory.
Backend - Object detectionThe object detection API is based on a detection framework built on top of TensorRT, which eases the loading of the Mobilenet SSD model. During its initialization, the NVIDIA's Jetson Nano employs the PyCUDA python library to have access to CUDA’s parallel computation API. At the same time, it creates a streaming attribute that fetches the snapped images in the Jetson Nano’s memory to perform inference operations using deep learning trained models.
class TrtSSD(object):
""" TensorRT SSD mobilenet implementation """
def _load_plugins(self):
ctypes.CDLL("models/ssd_mobilenet/libflattenconcat.so")
trt.init_libnvinfer_plugins(self.trt_logger, '')
def _load_engine(self):
TRTbin = 'models/ssd_mobilenet/TRT_%s.bin' % self.model
with open(TRTbin, 'rb') as f, trt.Runtime(self.trt_logger) as runtime:
return runtime.deserialize_cuda_engine(f.read())
def _create_context(self):
for binding in self.engine:
size = trt.volume(self.engine.get_binding_shape(binding)) * \
self.engine.max_batch_size
host_mem = cuda.pagelocked_empty(size, np.float32)
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
self.bindings.append(int(cuda_mem))
if self.engine.binding_is_input(binding):
self.host_inputs.append(host_mem)
self.cuda_inputs.append(cuda_mem)
else:
self.host_outputs.append(host_mem)
self.cuda_outputs.append(cuda_mem)
return self.engine.create_execution_context()
def __init__(self, model, input_shape, output_layout=7):
"""Initialize TensorRT plugins, engine and conetxt."""
self.model = model
self.input_shape = input_shape
self.output_layout = output_layout
self.trt_logger = trt.Logger(trt.Logger.INFO)
self._load_plugins()
self.engine = self._load_engine()
self.host_inputs = []
self.cuda_inputs = []
self.host_outputs = []
self.cuda_outputs = []
self.bindings = []
self.stream = cuda.Stream()
self.context = self._create_context()
def __del__(self):
"""Free CUDA memories."""
del self.stream
del self.cuda_outputs
del self.cuda_inputs
def detect(self, img, conf_th=0.3, conf_class=[]):
"""Detect objects in the input image."""
img_resized = _preprocess_trt(img, self.input_shape)
np.copyto(self.host_inputs[0], img_resized.ravel())
cuda.memcpy_htod_async(
self.cuda_inputs[0], self.host_inputs[0], self.stream)
self.context.execute_async(
batch_size=1,
bindings=self.bindings,
stream_handle=self.stream.handle)
cuda.memcpy_dtoh_async(
self.host_outputs[1], self.cuda_outputs[1], self.stream)
cuda.memcpy_dtoh_async(
self.host_outputs[0], self.cuda_outputs[0], self.stream)
self.stream.synchronize()
output = self.host_outputs[0]
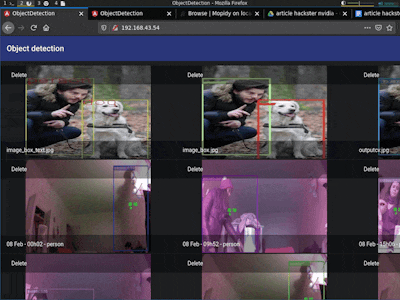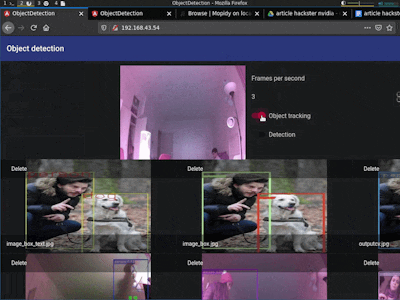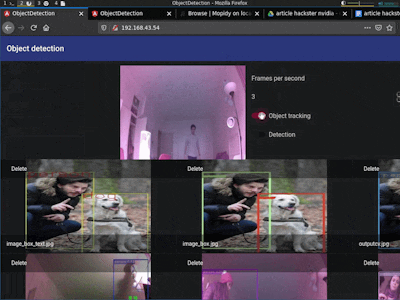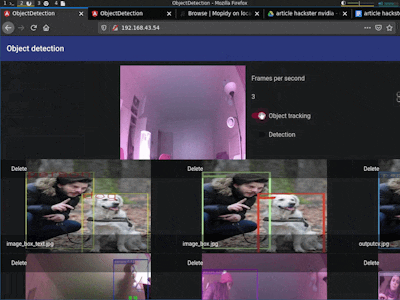
return _postprocess_trt(img, output, conf_th, self.output_layout, conf_class)At the end of the inference, the object detection decisions are made based on a confidence probability threshold, depending on the detection purposes. The SSD MobileNet model fetches the pretrained weights of the neural network on the Coco dataset, resulting in 80 output classes. For pedestrian analysis, a class denominated “Person” is introduced to gather all the attributes used during the execution of the detection algorithm.
The validation of the detection model was done in modules through sample images, which allowed us to exchange effortlessly the model under test. Subsequently, we employed Github’s Actions to evaluate the performance of each model avoiding breakdowns when modifications are introduced. The user can have access to the model’s evaluation in the directory “Test”, using the Pytest framework.
Backend - Object TrackingThe object localization module draws a bounding box when people become visible in an image. The object tracking algorithm is connected to the output of the object localization module to establish when a person enters into the snapshot’s scene, quantifying the number of people passing by in front of the capturing camera. Both algorithms store the information related to the bounding boxes centroids using a time metric called “t”. In the next time interval, in “t+1”, it correlates both detected centroids using the following parameters:
- The closest frame is considered as the same object.
- A departed object is considered as “vanished”, when there is a mismatch between the previous and current frames stored in memory.
- An object is considered “new”, when there are no previous frames of the detected object.
- The distance between centroids is calculated considering the position of the centroid in the previous frames.
The robustness of this algorithm relies on the accuracy to track multiple objects in a snapshot scene, based on keeping information related to the position of the centroids of the previous frames. For more details about the implemented algorithm, please refer to pyimagesearch’s blog.
Backend - Flask applicationThe backend API is built on top of the Flask web application framework, which links URL routes to Python functions. The main routes applied in this project are:
- ”/” and “/" to render html, css and js files that come from the static frontend application.
- “/imgs/" to send the image as jpg bytes
- “/api/delete” to delete a local image
- “/api/single_image” to capture an image from the camera, run object detection algorithms if needed and then send it to the frontend.
- “/api/images” to send a list of images depending on the input filters such as date, time and type of detected object.
- “/api/list_files” to count the number of images for each kind of filter such as date, time and type of detected object.
A web application based on Angular 8 was developed to perform some processing operations and draw information directly from the images. This web-based application interacts with the backend application through an API, in which the saved images can be loaded without major constraints.
The user can interact with the web application through four buttons:
- Real-time capturing mode employed to modify the frames per second on the fly, and execute the object detection and tracking algorithms.
- Statistics mode to see on the fly the statistics of the snapshots through ChartJS plots. Additionally, it offers an option to visualize photos in a mosaic mode.
- Celery tasks mode to visualize recurrently asynchronous tasks executed during the processing phase.
- Data selector to filter mosaic photos by date.
In many deep learning use cases, the inference phase of the algorithm is done on the edge devices, while the neural network’s training phase is done on the cloud. We tested the inference phase of the object detection application on three different hardware architectures: x86, ARM, and Maxwell GPU. The x86 architecture found in widely-spread Intel and AMD processors eases the development of deep learning algorithms since many libraries are available to implement object detection tasks. However, this architecture is not a suitable candidate for IoT devices due to their strict power consumption constraints. On the other hand, the ARM processor built-in on the Raspberry Pi does not provide a good performance either during the real-time detection phase nor during the interference phase. Beside being outperformed by other architectures, the ARM cores of the Raspberry Pi require constant cooling to avoid throttling during the training of the neural network. Finally, the Maxwell GPU integrated on the NVIDIA’s Jetson Nano offers a good trade-off between performance and power consumption since the object detection algorithm built on top of the the Tensor RT framework can be executed smoothly during extensive periods of time due to its passive cooling system and an attached external fan. As an outstanding fact, we reached better performance during the inference phase of the SSD Mobilenet model in comparison with the x86 architecture. The next table presents the latency results for each architecture during the training and inference phases:
Object tracking is executed using the Celery Task Manager. With a button built-in on the web-based application, the object tracking task is launched checking other processes running on the background.
Last but not least, the scenario used to validate the object detection and tracking was a corridor inside an office, in which 130 people were passing by during a normal work day. In the following capture compilation, the results of our implementation can be observed by the reader.
Conclusions
During the elaboration and deployment of this project we learned about many advantages that the NVIDIA’s Jetson Nano offers to perform deep learning tasks applied to object detection and tracking in a real scene. This device succeeded in identifying and tracking people during extended periods of time without reaching out-of-control internal temperatures. Additionally, its small size factor makes it ideal for IoT applications since it facilitates its installation in remote or dangerous areas.
We demonstrated the concept of edge computing by offloading the training phase of the neural network onto a server, maintaining the inference phase on the edge device. In order to exploit the computation on the cloud, we moved data from its source, in this case a CSI camera, to an external processing unit, overcoming the implicit challenges of that migration such as latency, scalability, privacy, and coordination inside dynamic network conditions.
In conclusion, our implementation of the detection and tracking deep learning algorithm tackled effectively the dynamic behavior of an office scene without being overwhelmed by the high number of objects, in this case people, present during a common work day. The web-based application enabled further image processing with the introduction of simple image filters.
Finally, we would like to highlight that this is only one of many use cases that deep learning algorithms, implemented on a robust platform such as NVIDIA’s Jetson Nano, can provide to resolve daily problems in the society. Many extensions to this work can be exploited by adding better capturing devices, implementing new detection solutions, or simply establishing new vulnerability conditions during the migration of data to a centralized location in the cloud.



Comments