_1ipFjuiIUQ.gif?auto=format%2Ccompress&gifq=35&w=400&h=300&fit=min)





Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
Hand tools and fabrication machines | ||||||
 |
| |||||
According to World Health Organization, over 2 billion people are being affected by contaminated water. Flint, Michigan water crisis has proven that even in first world country like United States, we still face water safety issues.
Currently the all of the water sensors are chemical based, the most common on being using chemical test strips that are one time use. Making monitoring contamination extremely difficult and exhausting hence events like Flint, MI has happened in the past.
A simple solution is going to USGS website and check the up to to date information, but you can clearly from the site there isn't much things we can sense or track.
The method of detection
Clean Water AI is IoT device powered by NVIDIA Jetson that classifies and detects dangerous bacteria and harmful particles. The system can run continuously in real time. The cities can install IoT devices across different water sources and they will be able to monitor water quality as well as contamination continuously. We utilize Tensorflow Object Detection Method to detect the contaminants and WebRTC to let user stream check their water source the same way they check their security camera.
For this project, we are focusing on UN Sustainable Develop Goals
- 6. Clean Water and Sanitation
- 9. Industry, Innovation and Infrastructure
I've previously helped my friend Peter Ma with his original version of Clean Water AI. Which can tell the difference between contaminated vs. clean water using caffe image classification.
In this article, we will be focusing on detecting multiple different types of contaminants using Tensorflow Object Detection. The original project costs about $800 to build the prototype (Edge AI Kit cost $419 itself), with NVIDIA Jetson Nano, we are able to accomplish entire prototype under $200, also with help of Object Detection we will be able to detect multiple different types of contaminants, also
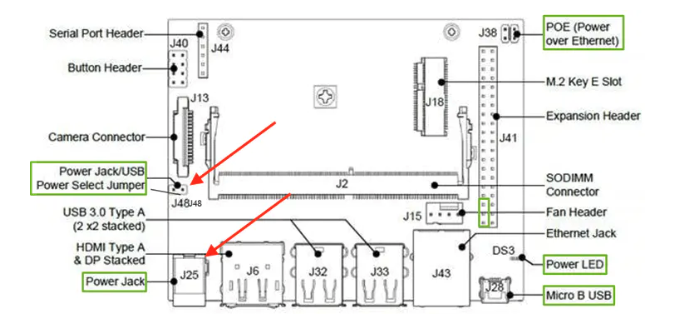
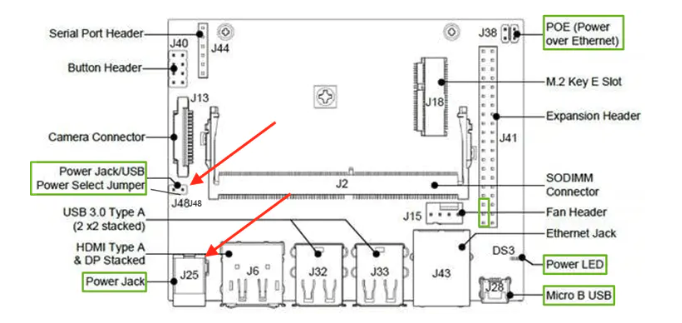
The equipment needed is a Jetson Nano and Microscopic Camera. Make sure you have at least 5v/2.5 amp power supply, between camera. Using the power jack over the micro usb power, this has proven to be much more stable. You first need to place a Jumper on J48, then the power jack on J25 would work. Using up to 5v/6amp works fine
Installation of OS Image and Jetpack can be downloaded at
https://developer.nvidia.com/embedded/jetpack
The Jetson Nano setup is located at NVIDIA courses which can be accessed via https://courses.nvidia.com/courses/course-v1%3ADLI%2BC-RX-02%2BV1/course/
The microscopic USB camera through USB that comes with most kits will act as just any other USB camera.
Deep learning has been a pretty big trend for machine learning lately, and the recent success has paved the way to build project like this. We are going to focus specifically on computer vision and image classification in this sample. Since there are no known data online, we've personally collected data ourselves.
We will be using dividing our network into separates 3 categories for this article, we can easily add more categories when we get more data.
- E Coli
- Particle
- Yeast
After gathering the data, we've used the application labelimg to label our data, this can be done via your local machines on Windows, Mac or Linux via
https://github.com/tzutalin/labelImg
We will do this on Mac, you can install it via
$ git clone https://github.com/tzutalin/labelImg.git
$ brew install qt # Install qt-5.x.x by Homebrew
$ brew install libxml2
$ pip3 install pyqt5 lxml # Install qt and lxml by pip
$ make qt5py3
$ python3 labelImg.pyYou can also add additional containments, simply use same method, taking images through microscope and label them.
Because Bacterias clusters very differently, machine learning because one of the best tools to detect and classify what type it is, all we really need is more data to add additional bacteria into our detection library.
In this article we will focus on the model training on the server and deploying on the Edge. It is possible to train on the edge machine but it has proven to be very slow. Clean Water AI requires large amount of training data, so it's best to go through server or your own desktop machine with GPU.
In this guide we will focus on Ubuntu 18.04 machine training, we will spin up the virtual machines on AWS, Google Cloud or Azure and ssh in to do the training. By avoiding specific server platforms, we allow ourselves to be platform independent. We will be mainly focusing on tensorflow object detection for this project.
Open your terminal and go to
$ ssh username@ipaddressFirst we will have to install Cuda 10.0 and cuDUNN, tensorflow somehow relies on CUDA 10.0 and cuDNN v7.6.4, the newest version is not yet compatible. Make sure you have the latest graphic card driver.
Driver is located at https://www.nvidia.com/download/index.aspx?lang=en-us
Cuda Toolkit 10.0 is located at https://developer.nvidia.com/cuda-10.0-download-archive?target_os=Linux&target_arch=x86_64&target_distro=Ubuntu&target_version=1804
and cuDNN v7.6.4 for CUDA 10.0 is located at https://developer.nvidia.com/rdp/cudnn-archive
After installation, make sure CUDA is running on our server
Upon finishing installation we will focus on install tensorflow and requirements into our server.
$ sudo apt-get update
$ sudo apt-get install libhdf5-serial-dev hdf5-tools libhdf5-dev zlib1g-dev zip libjpeg8-dev
Install system packages required by TensorFlow:
$ sudo apt-get update
$ sudo apt-get install libhdf5-serial-dev hdf5-tools libhdf5-dev zlib1g-dev zip libjpeg8-devInstall and upgrade pip3.
$ sudo apt-get install python3-pip
$ sudo pip3 install -U pip testresources setuptoolsInstall and upgrade pip3.
$ sudo apt-get install python3-pip
$ sudo pip3 install -U pip testresources setuptoolsInstall the Python package dependencies.
$ sudo pip3 install -U numpy==1.16.1 future==0.17.1 mock==3.0.5 h5py==2.9.0 keras_preprocessing==1.0.5 keras_applications==1.0.8 gast==0.2.2 enum34 futures protobufInstall the Python package dependencies.
$ sudo pip3 install -U numpy==1.16.1 future==0.17.1 mock==3.0.5 h5py==2.9.0 keras_preprocessing==1.0.5 keras_applications==1.0.8 gast==0.2.2 enum34 futures protobufAfter that you can install tensorflow via
$ sudo pip3 install --pre --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v43 'tensorflow-gpu==2.0.0'After that you can test the tensorflow installed successfully via
$ python3
>>> import tensorflow as tf
>>> hello = tf.constant('Hello, Tensorflow!')
>>> sess = tf.Session()
>>> print(sess.run(hello))And output should be Hello, Tensorflow! For our guide we will include these in workspace folder, we will first need tensorflow model to sample it with
$ mkdir workspace
$ cd workspace
$ git clone https://github.com/tensorflow/models.gitNow we can will install all the dependencies
$ sudo python3 -m pip install --upgrade pip
$ sudo pip3 install pillow
$ sudo pip3 install lxml
$ sudo pip3 install Cython
$ sudo pip3 install contextlib2
$ sudo pip3 install jupyter
$ sudo pip3 install matplotlib
$ sudo pip3 install pandas
$ sudo pip3 install pycocotools
$ sudo pip3 install absl-py
$ sudo apt-get install python-opencvSet the PYTHONPATH environment variable
$ export PYTHONPATH=$PYTHONPATH:~/workspace/models:~/workspace/models/research:~/workspace/models/research/slim
$ export PATH=$PATH:PYTHONPATH
$ cd ~/workspace/tensorflow1/model/research
$ python setup.py build
$ python setup.py installIn our example we just took 800 images of our own so we can get this trained relatively quickly on Jetson Nano. Copy entire repo into "~/workspace/models/research/object_detection/*
$ mkdir workspace
$ cd workspace
$ git clone https://github.com/CleanWaterAI/Jetson-Clean-Water-AI.git
$ scp -r Jetson-Clean-Water-AI/ user@ssh.example.com:~/workspace/models/research/object_detection/You can choose a list of library models that we can use, but since we are running the model on the edge we will be using ssd_mobilenet_v3_large_coco, the size iss mall enough and we do not need to quantization which loses additional accuracy. You can also play around to see which one is the best. The list can be seen at https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
Download ssd_mobilenet_v3_large_coco and extract it into object_detection folder. Place all the training data under /images/train and /images/test and use following command on the server
$ cd ~/workspace/model/research/object_detection
$ python3 xml_to_csv.pyThis creates a csv file for all the bounding objects on both training and testing files, next change class_text_to_int inside generate_tfrecord.py file's classes to following
def class_text_to_int(row_label):
elif row_label == 'ecoli':
return 1
elif row_label == 'particle':
return 2
elif row_label == 'yeast':
return 3
else:
print(row_label)If you have trained additional contaminants you can add it on top. We can then launch the python file via and get the message
$ python3 generate_tfrecord.py --csv_input=images/train_labels.csv --image_dir=images/train --output_path=train.record
Successfully created the TFRecords: /home/airig/workspace/models/research/object_detection/train.record
$ python3 generate_tfrecord.py --csv_input=images/test_labels.csv --image_dir=images/test --output_path=test.record
Successfully created the TFRecords: /home/airig/workspace/models/research/object_detection/test.recordnext we will create a labelmap.pbtxt under training folder, to map the labels and ids.
item {
id: 1
name: 'ecoli'
}
item {
id: 2
name: 'particle'
}
item {
id: 3
name: 'yeast'
}Next we will follow the similar config file to ssd_mobilenet_v3_large_coco.config file from /home/ai/workspace/models/research/object_detection/samples/config
Line 14. Change num_classes to the number of different objects you want the classifier to detect. For the above basketball, shirt, and shoe detector, it would be num_classes : 3.
Line 164. Change fine_tune_checkpoint to:
- fine_tune_checkpoint : "/home/airig/workspace/models/research/object_detection/ssd_mobilenet_v3_large_coco_2019_08_14/model.ckpt"
Lines 187 and 189. In the train_input_reader section, change input_path and label_map_path to:
- input_path : "/home/airig/workspace/models/research/object_detection/train.record"
- label_map_path: "/home/airig/workspace/models/research/object_detection/training/labelmap.pbtxt"
Line 198. remove num_examples as it checks entire folder
Lines 198 and 200. In the eval_input_reader section, change input_path and label_map_path to:
- input_path : "/home/airig/workspace/models/research/object_detection/test.record"
- label_map_path: "/home/airig/workspace/models/research/object_detection/training/labelmap.pbtxt"
# SSDLite with Mobilenet v3 large feature extractor.
# Trained on COCO14, initialized from scratch.
# 3.22M parameters, 1.02B FLOPs
# TPU-compatible.
# Users should configure the fine_tune_checkpoint field in the train config as
# well as the label_map_path and input_path fields in the train_input_reader and
# eval_input_reader. Search for "PATH_TO_BE_CONFIGURED" to find the fields that
# should be configured.
model {
ssd {
inplace_batchnorm_update: true
freeze_batchnorm: false
num_classes: 3
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
use_matmul_gather: true
}
}
similarity_calculator {
iou_similarity {
}
}
encode_background_as_zeros: true
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.2
max_scale: 0.95
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.3333
}
}
image_resizer {
fixed_shape_resizer {
height: 320
width: 320
}
}
box_predictor {
convolutional_box_predictor {
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.8
kernel_size: 3
use_depthwise: true
box_code_size: 4
apply_sigmoid_to_scores: false
class_prediction_bias_init: -4.6
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
random_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.97,
epsilon: 0.001,
}
}
}
}
feature_extractor {
type: 'ssd_mobilenet_v3_large'
min_depth: 16
depth_multiplier: 1.0
use_depthwise: true
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.97,
epsilon: 0.001,
}
}
override_base_feature_extractor_hyperparams: true
}
loss {
classific# SSDLite with Mobilenet v3 large feature extractor.
# Trained on COCO14, initialized from scratch.
# 3.22M parameters, 1.02B FLOPs
# TPU-compatible.
# Users should configure the fine_tune_checkpoint field in the train config as
# well as the label_map_path and input_path fields in the train_input_reader and
# eval_input_reader. Search for "PATH_TO_BE_CONFIGURED" to find the fields thatation_loss {
weighted_sigmoid_focal {
alpha: 0.75,
gamma: 2.0
}
}
localization_loss {
weighted_smooth_l1 {
delta: 1.0
}
}
classification_weight: 1.0
localization_weight: 1.0
}
normalize_loss_by_num_matches: true
normalize_loc_loss_by_codesize: true
post_processing {
batch_non_max_suppression {
score_threshold: 1e-8
iou_threshold: 0.6
max_detections_per_class: 10
max_total_detections: 10
use_static_shapes: true
}
score_converter: SIGMOID
}
}
}
train_config: {
batch_size: 12
sync_replicas: true
startup_delay_steps: 0
replicas_to_aggregate: 32
num_steps: 400000
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
fine_tune_checkpoint: "/home/airig/workspace/models/research/object_detection/ssd_mobilenet_v3_large_coco_2019_08_14/model.ckpt"
fine_tune_checkpoint_type: "detection"
optimizer {
momentum_optimizer: {
learning_rate: {
cosine_decay_learning_rate {
learning_rate_base: 0.4
total_steps: 400000
warmup_learning_rate: 0.13333
warmup_steps: 2000
}
}
momentum_optimizer_value: 0.9
}
use_moving_average: false
}
max_number_of_boxes: 10
unpad_groundtruth_tensors: false
}
train_input_reader: {
tf_record_input_reader {
input_path: "/home/airig/workspace/models/research/object_detection/train.record"
}
label_map_path: "/home/airig/workspace/models/research/object_detection/training/labelmap.pbtxt"
}
eval_config: {
}
eval_input_reader: {
tf_record_input_reader {
input_path: "/home/airig/workspace/models/research/object_detection/test.record"
}
label_map_path: "/home/airig/workspace/models/research/object_detection/training/labelmap.pbtxt"
shuffle: false
num_readers: 1
}Now we are ready to train, this will take a long time so get ready.
$ python3 model_main.py --logtostderr --model_dir=training --pipeline_config_path=training/ssdlite_mobilenet_v3_large_320x320_coco.configWe can track the progress via tensorboard
$ tensorboard --logdir=training
TensorBoard 1.14.0 at http://ai:6006/We can also check how accurate our detection method are under Images in tensorboard
The png generated under graph section can be seen below, this is the setting from the ssd_mobilenet_v3_large_coco
Next, we will freeze the graph using following command
$ python3 export_inference_graph.py --input_type image_tensor --pipeline_config_path training/ssdlite_mobilenet_v3_large_320x320_coco.config --trained_checkpoint_prefix training/model.ckpt-XXX --output_directory inference_graphEverything will be stored inside inference_graph, copy the files into usb and next step we will deploy it into Jetson Nano in next step.
Step 5: Deploying model and setup WebRTC on Jetson NanoNow all the preparation work is over, we can finally start to deploy it on Jetson Nano to run AI on the edge. We can do most of the setup via ssh into jetson and install all the tensorflow needed material
$ ssh ai@jetsonnanoip
$ mkdir workspace
$ cd workspace
$ mkdir tensorflow1
$ cd tensorflow1
$ git clone https://github.com/tensorflow/models.git
$ git clone https://github.com/CleanWaterAI/Jetson-Clean-Water-AI.git
$ cp Jetson-Clean-Water-AI/* models/research/object_detection/Set the PYTHONPATH environment variable
$ export PYTHONPATH=$PYTHONPATH:~/workspace/models:~/workspace/models/research:~/workspace/models/research/slim
$ export PATH=$PATH:PYTHONPATH
$ cd ~/workspace/tensorflow1/model/research
$ python setup.py build
$ python setup.py installWe need the newest inference_graph that we've trained
$ cd /workspace/models/research/object_detection/
$ scp username@aiserveraddress:/home/username/workspace/model/research/object_detection/inference_graph/* ./inference_graph/or you can do this on Jetson itself to get the latest model from the server
Run the demo to check our model
$ python3 clean_water_ai.pyWater Contamination Security Camera
We will do a simple version of the security camera via TF Object Detect, we can create a png every 20 frames or so.
i=0
While(True)
...
if i==20:
i=0
vis_util.save_image_array_as_png(frame, "home/ai/workspace/tensorflow1/models/research/object_detection/stream/stream.png")
i += 1This would save a file into stream.png, we can run an html script that easily host this that allows a refresh every 10 seconds or so
<html>
<head>
<link href="css/app.css" rel="stylesheet" type="text/css">
<script>
function refresh(node)
{
var times = 10000; // gap in Milli Seconds;
(function startRefresh()
{
var address;
if(node.src.indexOf('?')>-1)
address = node.src.split('?')[0];
else
address = node.src;
node.src = address+"?time="+new Date().getTime();
setTimeout(startRefresh,times);
})();
}
window.onload = function()
{
var node = document.getElementById('img');
refresh(node);
// you can refresh as many images you want just repeat above steps
}
</script>
</head>
<body>
<img id="img" src="stream.png"/>
</body>
</html>After that, simply run the http server on Jetson Nano
python -m SimpleHTTPServer 8000and you can open up emulator, local phones to remote stream to check your water sources. We can use different types of streams, but this is easiest way to make our demo working.
Right now we have a viable prototype that goes from end to end. Next we need the product to look decent, so we can first 3D print a case for our screen and anchor.
After everything is printed we should have following items for the screen. The screen cover, buttom, and holder. We will make another case for Jetson Nano.
When the screen part is all done, we will have a nicely looking screen case showed in following.
Next we will need to print out the case for Jetson Nano.
When all done, we will have the casing itself.
We can now demo the project we've done, our goal is to make monitoring your water quality same way you'd monitor your security camera.
What's next?For AI at the Edge Challenge challenge, we've setup the use case to use AI on the Edge to benefit the world in a practical way. Jetson Nano has make the product now marketable to municipalities and consumers.
Next step is shrinking entire device down to a box, this would significantly cut down the price as screen is no longer needed, as we can remotely look at the water from comfort of our own phone.







{kind=link}
{kind=link}
Comments