


Hardware components | ||||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
 |
| |||||
 |
| |||||
| ||||||
Hand tools and fabrication machines | ||||||
| ||||||
| ||||||
| ||||||
| ||||||
The World Health Organization (WHO) estimates that there are 285 million people that are visually impaired. Specifically in the United States, there are 1.3 million who are legally blind and only 10 percent of them can actually read braille and only 10 percent of the blind children are learning it. This is due to how expensive books are to read in braille. It costs up to $15,000 just to convert five chapters of a science book! Due to the price, very few blind people are able to learn through books. People who are reading impaired or suffer vision loss also struggle to read. While many can use audio-books, they are still limited on what they can read based on audio books' availability and costs. Books are the cheapest way to learn and 285 million people are unable to take advantage of this resource we greatly take for granted. The Reading Eye device would allow more freedom in terms of book choice, without having to make investments towards buying several audio-books. It is able to detect printed and handwritten text and speak it in a realistic synthesized voice.
My whole inspiration for this project was to help my grandmother who's vision degrades everyday due to age. I then thought of all the others who suffer due to bad vision or reading disabilities which motivated me to pursue this project.
Demo:Code:Note: When I refer to "your computer" I am referring to a Ubuntu 18.04 LTS machine. When I refer to "your Jetson Nano" I am referring to your Jetson Nano. While this tutorial can all be done using a Jetson Nano, I would not recommend it because it is slow during heavy processing compared to a traditional desktop machine.
Step 1, Setting Up Your Computer:As stated above, I recommend a clean install of Ubuntu 18.04 LTS. Instructions on installing Ubuntu can be found here. After installing Ubuntu, run this:
$ sudo apt-get update
$ sudo apt-get upgrade
$ sudo apt-get install python3.6-dev python3-pip gitWe first need to train a model that can recognize handwritten text. We will be using Tensorflow 2.0 and Google Colab for training. In terms of data, we will use the IAM Database. This data set comes with more than 9,000 pre-labeled text lines from 500 different writers.
Here are some examples from the database:
To access to the database you gave to register here. We can now download all necessary files.
First clone the Training GitHub Repository in your home folder of your computer:
$ cd ~
$ git clone https://github.com/bandofpv/Handwritten_Text.gitNext, we need to setup a virtual environment and install the required python modules:
$ sudo pip3 install virtualenv virtualenvwrapper
$ echo -e "n# virtualenv and virtualenvwrapper" >> ~/.bashrc
$ echo "export WORKON_HOME=$HOME/.virtualenvs" >> ~/.bashrc
$ echo "export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3" >> ~/.bashrc
$ echo "source /usr/local/bin/virtualenvwrapper.sh" >> ~/.bashrc
$ source ~/.bashrc
$ mkvirtualenv hand -p python3
$ cd ~/Handwritten_Text
$ pip3 install -r requirements.txtNext, we can download the database (Note: replace your-username with your username and replace your-password with your password from registering):
$ cd ~/Handwritten_Text/raw
$ USER_NAME=your-username
$ PASSWORD=your-password
$ wget --user $USER_NAME --password $PASSWORD -r -np -nH --cut-dirs=3 -A txt,png -P iam http://www.fki.inf.unibe.ch/DBs/iamDB/data/
$ cd ~/Handwritten_Text/raw/iam/
$ wget http://www.fki.inf.unibe.ch/DBs/iamDB/tasks/largeWriterIndependentTextLineRecognitionTask.zip
$ unzip -d largeWriterIndependentTextLineRecognitionTask largeWriterIndependentTextLineRecognitionTask.zip
$ rm largeWriterIndependentTextLineRecognitionTask.zip robots.txtThis is a long process so do something fun and look at memes:
After downloading the database, we need to transform it into a HDF5 file:
cd ~/Handwritten_Text/src
python3 main.py --source=iam --transformThis will create a file named iam.hdf5 in the data directory.
Now, we need to open the training.ipynb (LINK) file on Google Colab:
Select the Copy to Drive tab in the top left corner of the page.
Then, go onto your Google Drive and find the folder named Colab Notebooks. Press the + New button on the left and create a new folder named handwritten-text. Go into the new folder you created and press the + New button and select the Folder upload option. You will need to upload both the src and data folder from our Handwritten_Text directory. You screen should look like this:
Go back to the training.ipynb tab and confirm that you are hooked up to a GPU runtime. To check, find the Runtime tab near the top left corner of the page and select Change runtime type. Customize the settings too look like this:
Google Colab allows us to take advantage of a Tesla K80 GPU, Xeon CPU, and 13GB of RAM all for free and in a notebook style format for training machine learning models.
To prevent Google Colab from disconnecting to the server, press Ctrl+ Shift + I to open inspector view. Select the Console tab and enter this:
function ClickConnect(){
console.log("Working");
document.querySelector("colab-toolbar-button#connect").click()
}
setInterval(ClickConnect,60000)Your screen should look like this (Note: if you get an error about not able to paste into the console, type "allow pasting" as seen below):
Now let's start training! Simply find the Runtime tab near the top left corner of the page and select Run All. Follow through each code snippet until you reach step 1.2 where you will have to authorize the notebook to access your Google Drive. Just click the link it provides you and copy & paste the authorization code in the input field.
You can then let it the notebook run until it finishes training.
Take a look at the Predict and Evaluate section too see the results:
Now that we are done training, we can enjoy another meme:
First, follow NVIDIA's tutorial, Getting Started With Jetson Nano.
After booting up, open a new terminal and download the necessary packages and python modules (Note: this will take a LONG time!)t:
$ sudo apt-get update
$ sudo apt-get upgrade
$ sudo apt-get install python3-pip gcc-8 g++-8 libopencv-dev
$ sudo apt-get install libhdf5-serial-dev hdf5-tools libhdf5-dev zlib1g-dev zip libjpeg8-dev gfortran libopenblas-dev liblapack-dev
$ sudo pip3 install -U pip testresources setuptools cython
$ sudo pip3 install -U numpy==1.16.1 future==0.17.1 mock==3.0.5 h5py==2.9.0 keras_preprocessing==1.0.5 keras_applications==1.0.8 gast==0.2.2 enum34 futures protobuf
$ sudo pip3 install --pre --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v43 tensorflow-gpu==2.0.0+nv20.1This will install OpenCV 4.0 for computer vision, gcc-8 & g++-8 for C++ compiling, and TensorFlow 2.0 to run our handwritten text recognition model. Those are the main ones, but we will also need to install all the other required dependencies:
$ sudo pip3 uninstall enum34
$ sudo apt-get install python3-matplotlib python3-numpy python3-pil python3-scipy nano
$ sudo apt-get install build-essential cython
$ sudo apt install --reinstall python*-decorator
$ sudo pip3 install -U scikit-image
$ sudo pip3 install -U google-cloud-vision google-cloud-texttospeech imutils pytesseract pyttsx3 natsort playsound
$ sudo pip3 install -U autopep8==1.4.4 editdistance==0.5.3 flake8==3.7.9 kaldiio==2.15.1We also need to install llvmlite from source in order to install numba (Note: This will take an even LONGER time. Treat your self to a nice movie!):
$ wget http://releases.llvm.org/7.0.1/llvm-7.0.1.src.tar.xz
$ tar -xvf llvm-7.0.1.src.tar.xz
$ cd llvm-7.0.1.src
$ mkdir llvm_build_dir
$ cd llvm_build_dir/
$ cmake ../ -DCMAKE_BUILD_TYPE=Release -DLLVM_TARGETS_TO_BUILD="ARM;X86;AArch64"
$ make -j4
$ sudo make install
$ cd bin/
$ echo "export LLVM_CONFIG=\""`pwd`"/llvm-config\"" >> ~/.bashrc
$ echo "alias llvm='"`pwd`"/llvm-lit'" >> ~/.bashrc
$ source ~/.bashrc
$ sudo pip3 install -U llvmlite numbaNext, you need to plug in the WiFi USB adapter into any of the USB ports:
You then need to turn off power save mode to prevent the WiFi network from dropping out:
sudo iw dev wlan0 set power_save offIn order to take advantage of Google Cloud's Vision and Text-to-Speech APIs, we need to create an account. It will require you to enter your credit card, but don't worry, you get $300 free! Next go to your GCP Console and create a new project with any name using the following steps.
1. Go to the Cloud Console API Library and click on Select your project.
2. On the search bar enter "Vision".
3. Select Cloud Vision API and click Enable.
4. Go back to the Cloud Console API Library and enter "Text to Speech" in the search bar.
5. Select "Cloud Text-to-Speech API" and click Enable.
6. On the Google Cloud Service accounts page click on Select your project and select Create Service Account.
7. Designate the Service account name and click Create.
8. Under Service account permissions click Select a role.
9. Scroll to Cloud Translation and select Cloud Translation API Editor. Select Continue.
10. Click Create Key, select JSON, and click Create.
This will create a .json file that will allow your Jetson Nano to connect to your cloud project.
We also need to check the name of our Google Cloud Project ID. Go to your GCP Console on the Project info section, you will see ProjectID. This is your Project ID. We will use it soon.
Now we can clone the Reading_Eye_For_The_Blind GitHub Repository:
$ git clone https://github.com/bandofpv/Reading_Eye_For_The_Blind.gitRemember the handwritten text recognition model we trained earlier?
Now we need to save it into our Reading_Eye_For_The_Blind directory.
Go back to the handwritten-text Google Drive folder:
Right click on the output folder and click "Download". This is our model that we trained. Move it to our directory and rename it (Note: Change name-of-dowloaded-zip-file to the name of the downloaded zip file):
$ export YOUR_DOWNLOAD=name-of-dowloaded-zip-file
$ unzip ~/Downloads/$YOUR_DOWNLOAD -d ~/Reading_Eye_For_The_Blind
$ mv ~/Reading_Eye_For_The_Blind/output ~/Reading_Eye_For_The_Blind/modelTo make the our program run on the Jetson Nano every time we turn it on we need to create an autostart directory:
$ mkdir ~/.config/autostartWe need to move ReadingEye.desktop into our new directory:
$ mv ~/Reading_Eye_For_The_Blind/ReadingEye.desktop ~/.config/autostart/We also need to update the environmental variables in our file:
nano ~/.config/autostart/ReadingEye.desktopYou then want to find USERNAME and replace it with the username of your Jetson Nano (Note: There are two occurrences of USERNAME, change both!).
Next we need to connect a camera to the Jetson Nano. I used a Raspberry Pi Camera Module V2 with a wide angle lens attachment.
Simply remove the original lens and attach the wide angle one. It should look like this:
Connect the ribbon cable to the Jetson Nano's camera connector (Note: Make sure to use a longer ribbon cable than the original one provided. Also make sure to connect the ribbon cable in the correct orientation):
Install a fan to the Jetson Nano to prevent it from throttling during heavy computing. We will use a Noctua 5V Fan, which is extremely quiet and efficient. Use M3x25 screws to mount the fan into the mounting holes, then plug the cable into the fan header:
We can start soldering the power switch and start button. The power switch is a toggle switch with a LED light. Solder female jumper wires to the three pins (Note: Pay close attention to the pin labels! I accidentally swapped the ground and light pins as seen in the photos. The pin sticking on the side is the ground, the pin with a + is the signal pin, and the pin with a strange light symbol is the light pin):
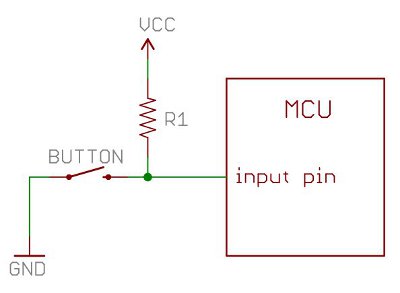
For the start button it can be more complicated because we will have to setup a pull up resister circuit with the button. Here is a schematic:
Solder a ground jumper wire to the - pin, a signal jumper wire to the + pin, and a 10k resistor to the + pin on the start button too. Next, solder a power jumper wire to the resistor. This will plug into the 3.3V pin on the Jetson Nano.
We also need to solder the LED pins on the start button too. Just solder a power jumper wire to the + light pin and a ground jumper wire to the - light pin. This is how mine looks like:
We can now connect the power switch and start button to the correct pins. Here is a schematic:
Note the jumper on the top of the J40 header.
Great job! Enjoy a meme:
3D print the CAD files included at the bottom of this tutorial. We need to fit all our electronics into this box. I used double sided foam tape to mount the the power pack to the bottom. You want to make sure it is orientated properly:
Next, we need to mount the Jetson Nano on top of the battery pack and connect the USB cable between the two:
Plug in the USB to audio audio adapter and hot glue it to the side hole:
Next, mount the power toggle switch and start button to the lid and plug it into the correct ports on the Jetson Nano:
Finally, glue the lid to the box using super glue. Make sure that the camera is outside the box mount it to the camera mount using hot glue. You can also do intricate ribbon cable folding to keep it aesthetic:
Now that we're done with the build have fun and start detecting! Plug in your favorite pair of earphones to the audio jack and place some text under the camera, toggle the power switch up and down, and click the start button.
To detect printed text, press the start button once. To detect handwritten text, double click the start button.
Understanding The Code:Now for the even more fun part. Code!!!
All code can be found on both GitHub Repositories:
There is a lot of code used in this tutorial and I will explain the fundamentals. My explanations will be very broad, so if you want to learn more about how my code works, take a look at my GitHub Repositories above or ask me in the comment section.
Lets start with a flow chart:
This will help understand the basics of what goes on. I decided to tryout Google's Cloud Vision and TTS API in this project. It allows you to use cloud computing to perform both printed and handwritten text recognition and text to speech. However, because the purpose of the Jetson Nano is to promote AI at the Edge, I programmed it to perform both printed and handwritten text recognition and text to speech without internet connection as well.
Let's go into each step in depth.
The first step is to check if the Jetson Nano is connected to internet:
def check_internet(host='http://google.com'):
try:
urllib.request.urlopen(host)
return True
except:
return FalseBy using the urllib module, we can attempt to connect to google.com. If it can connect to Google, then it returns that it has internet connection. If not, then it will return that it does not have internet connection.
After checking if the Jetson Nano has internet connection, it will take a picture using OpenCV:
But as seen above, the picture has this fisheye effect due to the wide angle lens. To correct for this, we can use OpenCV again to get a much better picture:
Next, if the Jetson Nano has internet connection, it will connect to the Google Cloud and use the Vision and Text-to-Speech APIs to recognize both printed and handwritten text and synthesize it to speech.
However, if the Jetson Nano does not have internet connection, it will have to rely on its CPU and GPU to recognize printed and handwritten text and synthesize it to speech.
Let's start with printed text because its easiest to understand. The Jetson Nano will first attempt to detect a page in the photo. This is done using OpenCV's edge detection:
If it detects a page, then it will transform it into a top-down view:
However, if the Jetson Nano does not detect a page, it will think its detecting text from a book. In this case, it will just convert it into grayscale and perform adaptive thresholding to remove shadows:
After preprocessing the image into a picture ready for printed text recognition, we will use PyTesseract:
text = pytesseract.image_to_string(img)Next, we will use pyttsx3 to synthesize the recognized text into speech:
engine = pyttsx3.init()
engine.setProperty('voice', "en-us+f5")
engine.say(text)Now for the handwritten text. Handwritten text is much harder to detect then printed text because unlike typed text, handwriting is never perfectly legible and requires the human brain to infer what word you are reading. This gives the Jetson Nano an even harder time to recognized handwritten text.
At the beginning of this tutorial, we trained our own handwritten text recognition model using Google Colab. I will briefly explain how this works.
Using the IAM Database, with more than 9,000 pre-labeled text lines from 500 different writers, we trained a handwritten text recognition:
Through Deep Learning, we fit our data set into the Convolutional Recurrent Neural Network (CRNN) which can overcome some limitations of a traditional Hidden Markov Model (HMM):
First, the input image is fed through the Convolutional Neural Network (CNN) layers which will extract the relevant features from the image. Each layer consists of three operations:
1. Convolution Operation
2. Non-Linear RELU Function
3. Pooling
Next, the output feature map from the CNN layers will be fed into the Recurrent Neural Network (RNN) which will propagate relevant information through longer distances, providing more robust training.
Finally, the Connectionist Temporal Classification (CTC) will calculate loss value and decodes the RNN output sequence into the final text.
Below is an image that goes into more detail of the RNN layers.
That's the most detail I will include in this tutorial because its relatively complicated and too long to add a full description in this tutorial. Again, ask in the comments if you have any questions.
Now that you somewhat understand the basics of our handwritten text recognition model, you could also notice that it can only detect words on one single line. This is where text segmentation comes to play.
The text segmentation process starts just like the printed text. It attempts to find a page and perform four-point perspective transformation:
Then comes the binarization. There are a few techniques to perform this:
- A Threshold Selection Method from Gray-Level Histograms (Otsu);
- An Introduction to Digital Image Processing (Niblack);
- Adaptive Document Binarization (Sauvola);
- Text Localization, Enhancement, and Binarization in Multimedia Documents (Wolf);
- Binarization of Historical Document Images Using the Local Maximum and Minimum (Su).
You may notice that the images are still quite distorted due to shadows. This is where Illumination compensation will come to the rescue:
Notice the dramatic improvements!
By coupling the two techniques we get this:
Sauvola is used in the code because it has the most consistent results.
After all this preprocessing, we can now begin the text segmentation. There are several levels of text segmentation: line, word, and character. In our program, we want to do line segmentation because that is what our CRNN is trained on (I will get into more detail about this in the Next Steps section). There are also a wide variety of methodologies when approaching text segmentation (pixel counting approach, histogram approach, Y histogram projection, text line separation, false line exclusion, line region recovery, smearing approach, stochastic approach, water flow approach, and so on). In our program, we used a statistical and path planning approach to line segmentation in handwritten documents:
To further preprocess the text for handwritten text recognition, deslanting is also used:
This will help remove the cursive writing style and help improve the text recognition results.
Pairing up our segmented text lines and our handwritten text recognition model, we can successfully recognize handwritten text and synthesize it into speech!
Next Steps:Upon the completion of this project, I have thought of future revisions:
1. Smaller Enclosure:
The box I designed turned out a lot bigger than I expected:
I wanted to make sure that I would have enough space to fit everything inside. After building the box, I realized that I can create a much smaller enclosure.
2. CTC Word BeamSearch:
Remember that Connectionist Temporal Classification (CTC) step in our handwritten text recognition training I explained earlier?
Well, I found a Word Beam Search CTC Algorithm that can greatly improve the final word decoding:
The algorithm is able to recognize words by using a dictionary. Doing so, It is able to always get an actual word rather than some conglomeration of characters.
3. More Data:
In this tutorial, we used the IAM Database. While it does come with more than 9, 000 pre-labeled text lines from 500 different writers, I often find the robot creating errors in handwritten text recognition. I have found other databases such as Bentham and Rimes which would provide our model with a greater variety of handwritings to train on. I could even start collecting my own samples to help improve the accuracy of the handwritten text recognition.
4. More Languages:
The robot can only recognize and speak English. I want to include several other languages such as Hindi, Mandarin, Russian, and Spanish in the future.










{kind=link}
{kind=link}
Comments