


Hardware components | ||||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
| ||||||
| ||||||
| ||||||
In this section we will consider arguments for choosing the LLMs we will work with in the project. We have to make an informed choice for the following use cases:
- base code LLM for further down-stream training on our specific task
- fine-tuned LLM for generating a synthetic dataset useful in our specific task
- instructions fine-tuned code LLM for evaluating and measuring our progress
The first choice is the main for the project, while the remaining ones are about auxiliary models that will provide additional functionality during the model training workflow. We will use a second LLM to generate a synthetic dataset for training the base LLM and we will use a third LLM to measure and compare the accuracy and performance of the trained LLM through a process called graded evaluation: using a larger LLM to grade the output from a smaller base LLM. All these three choices have some common criteria as well as their own specific considerations. For example, we will use the second and third choices only for inference, for tasks that will support the training of the base model. In the following sections we consider some of the general and specific criteria for making these choices.
1.1. Choosing a base LLM for further trainingA good starting point for code LLMs is a leaderboard like the following one: https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard. Besides the task raw accuracy, several other considerations can guide this choice: the size of the model, the availability of the code, the various performance aspects, throughput, etc. As we will work within the 48 GB VRAM limit of the W7900 GPU, we have to focus on models that can fit in the card's memory. A good estimator for the required memory size of a LLM is a website like https://vram.asmirnov.xyz/. After a brief estimation we can further narrow down our search to models in the 3B - 7B parameters range, also depending on the quatization level used to represent the parameters and gradients. Another important aspect is the availability of the pipeline code and data used to construct and train the model. Even when the resulting model weights are public it can still be the case that the notebooks and code used to build and train the model is not. Considering all these aspect we will choose to train the:
- StarCoder2-3b https://huggingface.co/bigcode/starcoder2-3b model.
Besides fulfilling the hardware constraints, this model also has the advantage of being both open source and open science. There are several possible alternatives with various tradeoffs between pros and cons that are worth mentioning:
- https://huggingface.co/deepseek-ai/deepseek-coder-33b-instruct (best accuracy, larger than 48 GB VRAM)
- https://huggingface.co/codellama/CodeLlama-70b-hf (better accuracy, larger than 48 GB VRAM)
- https://huggingface.co/google/codegemma-7b-it (not open science, larger than 48 GB VRAM, if not quantized)
- https://huggingface.co/bigcode/starcoder2-15b-instruct-v0.1 (already instruction fine-tuned, also open science, larger than 48 GB VRAM).
Besides the hardware requirements already discussed in previous section, which are also relevant for this choice, the content of our specific downstream task is the determining factor when choosing a synthetic dataset generating LLM. Our specific downstream task is focused on using a code LLM to generate educationally useful questions or exercises. As a first approximation the task can be formulated similar to the following sentence template:
create an interesting and challenging multiple choices quiz question about tensor addition operations in pytorchusingthe ROCm library on an AMD graphical card
In order to train the code LLM to produce satisfiable output for this task we will use a hybrid dataset, part of it will contain hand written (i.e. human expert generated) examples of such quizes; the second, and larger, part of the training dataset will contain examples of questions generated by another LLM. We will use an already pretrained LLM that has also been fine-tuned for generating synthetic data for interrogative tasks. There are many such specialized LLMs to chose from, most of them are specialized for various existing answer-generating tasks. We will also have to adapt the output for our own purpose. The final choice of the synthetic dataset generation LLM is:
- Bonito: https://huggingface.co/BatsResearch/bonito-v1 model
It is a model trained for generating question answering, textual entailment and natural language inference datasets. There are several NLP tasks that Bonito has been trained on using specialized domain knowledge, see the full model description https://arxiv.org/abs/2402.18334. The model repository https://github.com/BatsResearch/bonito also provides useful classes that allows to adapt the main implementation class for other specific tasks that need differently specialized post-processing stages. We will describe the main changes we made below in more detail, for now, the main reason in favor of this model choice are its focus on interrogative and reasoning tasks: generation of various questioning tasks (binary, extractive, multiple choice, etc.) and reasoning tasks (natural language and textual sentence entailment).
1.3. Instructions fine-tuned code LLM for evaluationFinally, before starting to train a model, we need a way to measure our progress. And for this we need a basic way to estimate how good the chosen base LLM model already is at solving our specific task? The topic of LLM evaluation (code or natural language) is not a trivial one, neither from a theoretical perspective, nor from a practical efficiency point of view. There is no perfect substitute for human expertise in evaluating LLM output or expedient substitute for a standardized testing dataset created and vetted within a specific domain. As all these are beyond the scope of this project, we will use graded evaluation as an expedient way of capturing some relevant signal about the baseline accuracy of the specific task we are interested in. We will design a template based graded LLM evaluation of the base LLM and we will compare the final trained model against this metric. For this to be effective we will need to use a model one order of magnitude larger than the evaluated model and preferably use a grader model that has also been code and instructions fine-tuned. Given all these considerations, we will use:
- Llama3-8b-Instruct: https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct model
Brief empirical inspection of the evaluations produced was the main reason for choosing this model for the graded evaluation step. Other possible alternatives with their tradeoffs that deserve to be mentioned are:
- https://huggingface.co/ibm-granite/granite-8b-code-instruct (less verbose output, less accurate evaluations, faster inference)
- https://huggingface.co/google/gemma-2-9b (slightly larger, comparable accuracy and throughput)
The sections below will present in more detail the notebooks and templates used for graded evaluation.
Besides the aspects discussed so far, we have also used additional pragmatic criteria when designing the training workflow and its related activities, such as: the training should not exceed five days on one W7900 GPU (preferably one extended weekend), generating the synthetic dataset should not exceed five hours of one W7900 GPU inference time, and the graded evaluation process should not exceed five hours of inference time on one W7900 GPU.
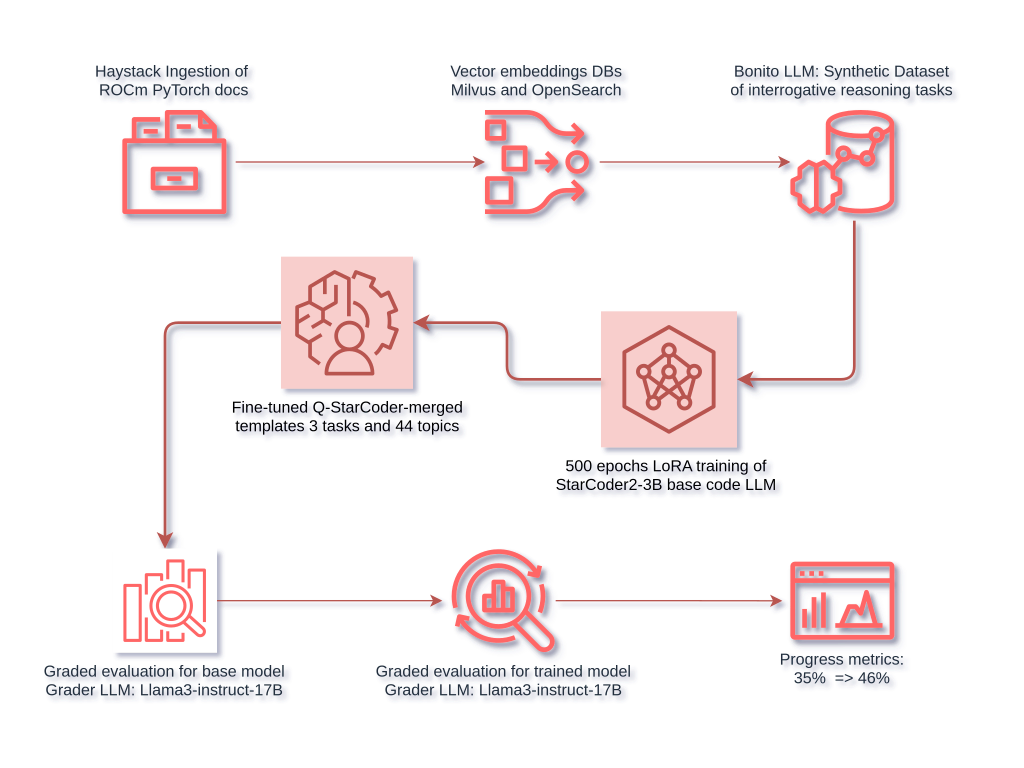
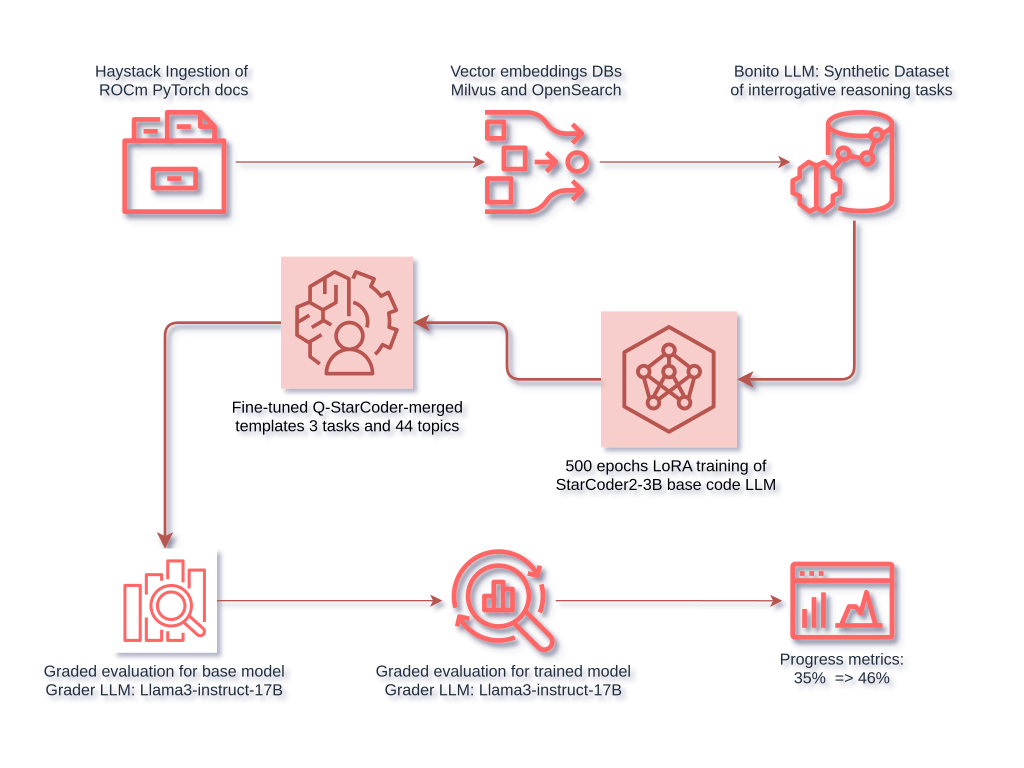
2. Workflow for training and auxiliary processesNow that the choice of LLMs has been done, let us focus on the main steps in the workflow. The first question to ask is: what is the accuracy level of the base model for our task? We need to know this in order to be able to compare our progress against this baseline. We will describe below the details of the template engineering and graded evaluation steps used to provide an answer. The second auxiliary step consists in designing an appropriate synthetic dataset suitable for our training job. We will use an ingestion process to establish the domain knowledge and will adapt the Bonito post-processing implemented class methods for synthetic task generation with suitable abstractions for our purpose. Finally, we will use the artifacts of the auxiliary steps to perform the training process. We will use a low rank adaptation training strategy (henceforth, LoRA); given the VRAM resources that our workflow is bound to (i.e. 48 GB), it is not practical to train a full code LLM. Once the fine-tuning is over, we will use the same graded evaluation method, based on the same artifacts, to check for signals of improvements in the LLM's performance on our task.
2.1. Graded evaluation and template engineeringThe LLM evaluation will proceed in two steps: the first will use the graded LLM to generate output for a number of tasks and topics, the second step will use the grader LLM to asses the quality of the generated output. For this to be effective it is important that the grader is an LLM with higher resources than the graded LLM (i.e. higher accuracy, larger parameter size, etc).
The following code snippet uses langchainhttps://python.langchain.com/v0.2/docs/introduction/ to create a template for a list of tasks to be evaluated. At the end of the loop, the generated output is saved in a file which will be used in the second stage as input for the evaluation chain.
import gc
import json
import torch
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
from langchain.prompts import PromptTemplate
import llm_test_tasks_list
model_id="bigcode/starcoder2-3b"
llm = HuggingFacePipeline.from_model_id(
model_id=model_id, task="text-generation",
pipeline_kwargs={ "max_new_tokens": 300, "pad_token_id": 50256 },
device=0)
if __name__ == '__main__':
text_generations = []
for topic in llm_test_tasks_list.topics_list:
for task in llm_test_tasks_list.tasks_list[:3]:
question = f"Generate a challenging and interesting {task} about the following topic: {topic}"
template = """You are an expert Machine Learning scientist specialized in Pytorch and ROCm
Task: {question}
Include clear explanations and reasoning.
Response:
"""
prompt = PromptTemplate.from_template(template)
def assistant_chain(prompt=prompt, llm=llm):
return prompt | llm
chain = prompt | llm
assistant = assistant_chain(
prompt = PromptTemplate.from_template(template),
llm=llm)
answer = assistant.invoke({"question": question})
query = answer.split('Response: ')[-1]
text_generations.append({ "task": task, "topic": topic,
"task_query": question, "quiz_query": query
})
json_string = json.dumps(text_generations)
with open(f'generated_templates_{model_id.split("/")[-1]}.json', 'w') as file:
file.write(json_string)Note that at this stage we are using our base model bigcode/starcoder2-3b to generate the output. After the training process, when evaluating the trained model, we only have to change the line containing the id for the target model model_id="stmnk/querycoder-checkpoint-500-merged"
The second step creates a second template which will interpolate the output from the graded model and invoke the grader LLM to evaluate its quality. The following code snippet extract contains the main functionality used to produce the evaluation file (full implementation details are also available in the code repository):
model_id="meta-llama/Meta-Llama-3-8B-Instruct" # 32 GB
# model_id="ibm-granite/granite-8b-code-instruct" # 32 GB (faster inference)
# model_id="google/gemma-2-9b" # 38 GB (more verbose)
def llm_grader_eval_chain(agent_response,
llm = HuggingFacePipeline.from_model_id(
model_id=model_id, task="text-generation",
pipeline_kwargs={ "max_new_tokens": 300, "pad_token_id": 50256, },
device=0,
),
topic = 'ROCm and PyTorch',
task = 'information extraction question',
output_parser=StrOutputParser()
):
eval_system_prompt = f"""You are an assistant that evaluates whether or not another assistant is producing interesting and challenging quiz content.
The outpu prouced by the assistant should have the shape of a {task} about {topic}"""
eval_user_message = f"""You are evaluating the following generated content:
[BEGIN CONTENT]
{agent_response}
[END CONTENT]
Read carefully the content between [BEGIN CONTENT] and [END CONTENT] above and determine whether or not it qualifies as a clear, interesting and challenging {task} about {topic}. Do not answer with code implementation, do not use hypothetical language, answer directly with a one word evaluation verdict.
If you think the response is a clear, challenging and interesting {task} about {topic}, answer 'Yes', otherwise, answer 'No'.
Give your evaluation answer below:
"""
eval_prompt = ChatPromptTemplate.from_messages([
("system", eval_system_prompt),
("human", eval_user_message),])
return eval_prompt | llm | output_parser
def test_model_graded_eval_artifact(glci_template, task, topic):
eval_agent = llm_grader_eval_chain(glci_template,
task = task, topic = topic)
eval_response = eval_agent.invoke({})
return eval_response
if __name__ == '__main__':
FILE_NAME = 'generated_templates_starcoder2-3b.json'
with open(FILE_NAME) as file:
templates = json.load(file)
evaluted_templates = []
for item in templates:
pipe_artifact = item['quiz_query']
resp = test_model_graded_eval_artifact(pipe_artifact,
item['task'], item['topic'])
evaluation_a = resp.split(
'Give yout evaluation answer below:')[-1]
item['evaluation'] = evaluation_a
bool_verdict = evaluate_output(evaluation_a)
evaluted_templates.append(item)
json_string = json.dumps(evaluted_templates)
EVAL_MODEL = model_id.split("/")[-1]
EVAL_NAME = f'evaluated_templates_{EVAL_MODEL}_{FILE_NAME[:-5]}.json'
with open(EVAL_NAME, 'w') as file:
file.write(json_string)Depending on how verbose the grader LLM's answer is, the implementation details of the evaluate_output() function might need to contain additional parsing in order to extract the right evaluation. With this evaluation in place we obtain a 35% of positive evaluations for our task in the base model. We generated the mock evaluation metric set from three tasks (binary, multiple-choice, and extractive questions) combined with 44 topics related to the PyTorch and ROCm domain, for a total of 132 examples. This evaluation method can definitely be improved, but when applied unchanged to the model output after training it is sufficient to detect a positive signal.
The final ingredient before we can start the training process is to put together a training dataset. We will do this in two stages: first we will ingest some knowledge about our domain of interest and then we will use the content of the documents to generate different types of questions and reasoning tasks about them. We will next discuss some possible alternatives for ingesting domain knowledge.
2.2.1. Text and Vector DatabasesWe have a plethora of good databases options available for ingesting documents. Because we plan to reuse the same database in a later section for semantic retrieval, we will use databases that have both text/json and vector embedding capabilities. Among many such options additional criteria to narrow down the possibilities are: open source standards, availability of documentation and ease of use. Because of all these, we will use the following options:
- OpenSearch: https://opensearch.org/docs/latest/
- Milvus: https://milvus.io/docs/quickstart.md
There are plenty of other alternatives with their pros and cons that deserve to be mentioned, such as: Weaviate https://weaviate.io/developers/weaviate, Qdrant https://qdrant.tech/documentation/, Pinecone: https://www.pinecone.io/learn/ etc. Several established databases both relational and nosql also provide extensions for similar features these days.
Getting started with Milvus is very easy, after the initial installation, the following will start a local instance of the database:
(base) stmnk@ainst:~/code/databases/milvus$ bash standalone_embed.sh start
Wait for Milvus Starting...
Start successfully.A useful application to manage the data in the Milvus instance within an intuitive GUI is Attu. This can easily be installed as a Ubuntu software package and will provide a connection to the locally running database instance.
We will use a Haystack https://docs.haystack.deepset.ai/docs based pipeline to ingest documents into the Milvus database. The following code snippet contains the main steps of the ingestion process:
from haystack import Pipelinefrom sentence_transformers import SentenceTransformer
from sentence_transformers import SentenceTransformer
from haystack.components.fetchers import LinkContentFetcher
from haystack.components.converters import HTMLToDocument
from haystack.components.preprocessors import DocumentSplitter
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
from haystack.components.writers import DocumentWriter
from milvus_haystack import MilvusDocumentStore
from milvus_haystack.milvus_embedding_retriever import MilvusEmbeddingRetriever
document_store = MilvusDocumentStore(
connection_args={
"host": "localhost", "port": "19530",
"user": "", "password": "", "secure": False,
},
drop_old=True,
)
link_fetcher = LinkContentFetcher()
converter = HTMLToDocument()
splitter = DocumentSplitter(split_length=100, split_overlap=5)
embedder = SentenceTransformersDocumentEmbedder()
writer = DocumentWriter(document_store=document_store)
indexing_pipeline = Pipeline()
indexing_pipeline.add_component("link_fetcher", link_fetcher)
indexing_pipeline.add_component("converter", converter)
indexing_pipeline.add_component("splitter", splitter)
indexing_pipeline.add_component("embedder", embedder)
indexing_pipeline.add_component("writer", writer)
indexing_pipeline.connect("link_fetcher", "converter")
indexing_pipeline.connect("converter", "splitter")
indexing_pipeline.connect("splitter", "embedder")
indexing_pipeline.connect("embedder", "writer")
indexing_pipeline.run(data={
"link_fetcher": {
"urls": [
"https://rocm.blogs.amd.com/artificial-intelligence/starcoder-fine-tune/README.html",
"https://rocm.blogs.amd.com/artificial-intelligence/openllm/README.html",
"https://rocm.blogs.amd.com/software-tools-optimization/roc-profiling/README.html",
... # shortened to save space
]
}
})All we need to start the ingestion process is a list of urls linking to the relevant domain knowledge, in our case we have scraped a list of blog entries from the AMD website and links to sections of the PyTorch official documentation and other online material. The Haystack library offers useful classes that abstract away many details of the knowledge ingestion implementation while also providing convenient customization options for the most important aspects, like, for example, splitting the documents in manageable paragraph sizes, setting the sections overlap, choosing an LLM for producing the vector embedding, etc.
Once the documents are ingested we can inspect their content in the Attu GUI:
Similarly, we can easily start a local OpenSearch cluster using a Docker container from the official repository image:
docker compose upThis will provide both the database nodes and a web browser based dashboard and utilities to inspect the data inside the collections or indices.
Thanks to the utility classes provided by Haystack, all we have to change in the ingestion pipeline is the connection information and the type of DocumentStore class used in the database component. The following code snippet presents the main implementation aspects:
from haystack_integrations.document_stores.opensearch import OpenSearchDocumentStore
from haystack_integrations.components.retrievers.opensearch import OpenSearchEmbeddingRetriever
document_store = OpenSearchDocumentStore(
hosts="http://localhost:9200",
# use_ssl=True,
verify_certs=False,
http_auth=("admin", "admin")
)
link_fetcher = LinkContentFetcher()
converter = HTMLToDocument()
splitter = DocumentSplitter(split_length=500, split_overlap=20)
embedder = SentenceTransformersDocumentEmbedder()
writer = DocumentWriter(document_store=document_store)The rest of the ingestion pipeline components proceed the same as before: text content is fetched from the provided links, converted to document format, spliced with overlap in the provided paragraph size, embedded in multidimensional semantic vectors, and finally ingested in the database index. We can now also inspect the ingested documents together with their vector embedding representation using the browser dashboard:
In the next step, from the ingested unstructured text we will create a synthetic dataset and finally use this during the fine tuning for our specific downstream task: generating output in form of questions, quizes, and exercises. Due to the generous amount of VRAM provided by the W7900 we can use the un-quantised Bonito model to perform this final preparatory task with the AMD Radeon GPU.
Bonito is a model that has been trained to generate synthetic datasets from unstructured text for a number of NLP downstream tasks. In order to use it for our purpose we will need to select the subset of tasks that have interrogative reasoning relevance and adapt the model generation artifacts to convert them from generating answers to generating questions. The following code snippet illustrates the main components for achieving this transformation:
from datasets import Dataset, load_dataset, concatenate_datasets
from opensearchpy import OpenSearch
from vllm import SamplingParams
from bonito import Bonito
import torch
import json
host = 'localhost'; port = 9200
auth = ('admin', 'admin') # For testing only credentials in code not safe.
client = OpenSearch(
hosts = [{'host': host, 'port': port}],
http_auth = auth, http_compress = True,
ssl_assert_hostname = False, ssl_show_warn = False,
)
response = client.search(
body = {
'size': 2000,
'query': { "match_all": {} }
},
index = 'default'
)
unnatoted_json = [{
'input': response['hits']['hits'][i]['_source']['content'],
'output': ''
} for i in range(len(response['hits']['hits'])) ]
with open('unnatoted_data.json', 'w') as f:
json.dump(unnatoted_json, f)
pytorch_rocm_dataset = load_dataset( "json",
data_files='unnatoted_data.json',
split="train"
)
pytorch_rocm_dataset.push_to_hub(
"stmnk/unnanotated_hamdpai", split="train")We range over the text documents ingested in our databases in the previous step, and, for each of them we create an instruction template that uses its unstructured content as an input and instructs Bonito to generate an interrogative reasoning task about it. We do this for seven questioning and inference related tasks and we post-process the output to filter the questions or entailments and use them as ground truth examples of output to train the base Starcoder2 model with. Starting from the ingested documents we apply to each of them the following five interrogative tasks (ynqa, mcqa, exqa, qa, qg), plus two reasoning tasks (te, nli). Some generated examples are eliminated by Bonito during post-processing if they do not pass format checks (e.g. prediction does not contain exactly two parts, the question/premise and the answer/conclusion, separated by <|pipe|>). Additionally, the bonito library provides abstractions to customize the dataset post processing functionality. All example tasks in the training dataset are adapted as described before, we do this by customizing the implementation logic in the class method AbstractBonito_postprocess_dataset from the file /bonito/bonito/abstract.py.
The final dataset size is guided by the initial criterion of limiting the latency of the training job to an extended weekend, but, of course, the dataset can be further improved in both quantity and quality. Quantitatively, more documents can be ingested and additional tasks considered, for example we have ignored summarisation, paraphrasing, or co-reference resolution tasks, etc. that are also available in Bonito. Qualitatively the generated examples can also be improved, for example, many code content samples in the dataset are not of high relevance or quality and should probably be either filtered out or otherwise improved before training. This is expected because Bonito was trained in the legal and financial domains, not with code. For practical reasons (mainly time) we decided to leave these, and similar, extensions out of the scope of the project and will discuss further improvements in the final section below.
unannotated_dataset = load_dataset(
"stmnk/unnanotated_hamdpai",
split='train'
)
bonito = Bonito("BatsResearch/bonito-v1",
enforce_eager=True, dtype=torch.float16,
)
sampling_params = SamplingParams(
max_tokens=256, top_p=0.95,
temperature=0.5, n=1
)
SHORTFORM_TO_FULL_TASK_TYPES = {
"exqa": "extractive question answering",
"mcqa": "multiple-choice question answering",
"qg": "question generation",
"qa": "question answering without choices",
"ynqa": "yes-no question answering",
"te": "textual entailment",
"nli": "natural language inference",
}
all_qdatasets = Dataset.from_dict({
"input": [], "output": [],
'querypred': [], 'question': [], 'answer': [],
'context_line_question': [], 'task': [], "context_raw": [],
"instruction_context_no_task": [],
})
qtasks = ['mcqa', 'ynqa', 'exqa', 'qa', 'qg', 'te', 'nli']
for task in qtasks:
synthetic_dataset = bonito.generate_tasks(
unannotated_dataset,
context_col="input",
task_type=task,
sampling_params=sampling_params
)
new_column = [SHORTFORM_TO_FULL_TASK_TYPES[task]] * len(synthetic_dataset)
synthetic_dataset = synthetic_dataset.add_column("task", new_column)
all_qdatasets = concatenate_datasets([all_qdatasets, synthetic_dataset])
all_qdatasets_ins = all_qdatasets.map(lambda example, idx: {
"instruction_input": f'Given the information: \n\n{example["context_raw"]}; \n\nGenerate a {example["task"]}'
}, with_indices=True)
all_qdatasets_ins = all_qdatasets_ins.map(lambda example, idx: {
"question": example["question"].replace("{{context}} ", "")
}, with_indices=True)
all_qdatasets_ins.push_to_hub("stmnk/synthetic_hamdpai", split="train")Once generated the dataset is updated to the huggingface hub to be used through streaming during the training process.
2.3. Training code LLM on Radeon Pro W7900 with LoRAAfter extensive, but necessary, preparatory stages, we can finally proceed with the main part of this project: the model training process. Even with the generous amount of 48 GB of VRAM provided by the W7900 GPU card training a full 3 billions parameter model is a demanding task. A practical alternative is to employ parameter efficient fine-tuning (PEFT), which is a set of techniques that only update a limited number of parameters during training, thus making it feasible on a single GPU card with limited resources. One such technique is LoRA and it consists in training a separate parameter matrix and then merging the trained parameters into the base model by means of matrix operations. In this way, only a smaller size matrix model will be loaded in the the GPU VRAM during training. The AMD ROCm blogs webpage provides already an excellent starting point for this approach: https://rocm.blogs.amd.com/artificial-intelligence/starcoder-fine-tune/README.html. In this section we will merely document the changes we made to the workflow described in the linked blogpost.
The first needed change to the training environment comes from the model version of Starcoder we will use. Starcoder2 requires an updated version of the transformers library, this will require an update of the requirements installed in the python environment used for training. Besides, several additional libraries and their dependencies will need to be installed(/updated) preferably from the anaconda channel before the training script can run for version 2 of starcoder LLM, we list them here for reference: conda install -c anaconda pyyaml idna certifi pytz six MarkupSafe. Next, as we only have one GPU, the number of nodes in the training script needs to be 1. At this point, as Hackster.io is a hardware oriented platform, it might be useful to include a brief discussion regarding the impact various hyper-parameter choices have on hardware resources utilization. The main hyper-parameters of the training job are listed in the following bash snippet:
# train.sh
python -m torch.distributed.run \
--nproc_per_node 1 \
finetune/finetune.py \
--model_path="bigcode/starcoder2-3b" \
--dataset_name="stmnk/synthetic_hamdpai" \
--input_column_name="instruction_input" \
--output_column_name="question" \
--split="train" \
--streaming \
--size_valid_set 1000 \
--seq_length 1024 \
--max_steps 500 \
--batch_size 30 \
--gradient_accumulation_steps 16 \
--learning_rate 1e-4 \
--lr_scheduler_type="cosine" \
--num_warmup_steps 100 \
--weight_decay 0.05 \
--lora_r 200 \
--output_dir="./checkpoints"The size of the LoRA matrix lora_r determines the amount of VRAM needed during training. We found through experimentation that 200 is a good value, the tradeoff here is between the number of parameters that will be updated and the amount of GPU memory, ideally, this should not consume all the available VRAM, because additional space will be needed to process the dataset examples, which will be loaded next. A roughly 3% of the parameters are logged as trainable with this settings, which is enough to detect a positive signal, if needed, this can be increased at the expense of batch size, which we will discuss next.
(base) stmnk@rainst:~$ cd code/starcoder/ && conda activate starcoder
(starcoder) stmnk@rainst:~/code/starcoder$ ./fine.sh
Loading the dataset in streaming mode
100%|████████████████████████████████████| 400/400 [00:01<00:00, 231.53it/s]
The character to token ratio of the dataset is: 3.91
Loading the model
trainable params: 92160000 || all params: 3122531328 || trainable%: 2.9514515730744977
Starting main loop
Training...
...The batch_size argument, which will determine how many examples are processed once, also impacts the VRAM significantly, ideally, after this the card should be as close as possible to the VRAM maximum capacity. We found through experimentation that 26 is a good value. This also depends on the size of the sequences in the dataset. In our case this is determined by the splitting size, described during the section about ingestion, and a constant for the length of the template describing the task. The input and output column names need to be specific to the dataset used. A good rule of thumb is to choose the number of epochs equal, or very close to, the number of examples in the training dataset. In our case we settled after experimentation on a lower number here: 500, to make the job run only for a weekend. This can have practical advantages, e.g. the electricity price is lower, and if, needed can be restarted/continued from the resulting checkpoint in subsequent iterations.
At this point it is important to introduce some tools for monitoring GPU and system resources usage that we found useful during designing the training job. Programs like CPU-X (the Graphics tab), nvtop and psensors are easily available on a linux machine and can be used for this purpose. The following images and their captions illustrate some relevant outputs during the training.
The most important metric to monitor at the beginning of the training process is the amount of VRAM, as this will impact the efficiency of the training process on long term. As an illustration, the following images show two cases in which, depending on the starting hyper-parameters, only half or full capacity, respectively, of the available VRAM resources are used during the training.
For later stages of the training process wandb logs provide useful information about the evolution of the relevant metrics. Different runs can be compared, stopped and restarted with an optimized combination of hyper-parameters.
Ideally, the relevant performance metrics (e.g. the evaluation loss, etc.) will keep improving during the training process, although the rate of improvement may vary widely, depending on the initial settings of the hyper-parameters. It is often useful to experiment and monitor various combinations of the hyper-parameters and decide to stop early, use the gained insights in order to restart the training process optimized for long term performance and a well balanced resources utilization.
For example, adding inside the run_training function from the finetune/finetune.py file, the value of the argument included in the snippet below can be useful for long term optimization, as this change can provide a significant reduction the total training time:
training_args = TrainingArguments(
torch_compile=True,
...
)The last step before we can evaluate the quality of the training process consists in merging the trained parameters into the main base model. Remember that we have trained a small dimensions matrix of parameters compared to the dimensions of the full base model. The merging process is neither complicated nor very resources demanding. The following code script contains the main step:
# merge.sh
python finetune/merge_peft_adapters.py \
--base_model_name_or_path bigcode/starcoder2-3b \
--peft_model_path checkpoints/checkpoint-500 \
--push_to_hubIn case the training needs to be continued this will only require a minimal change to use the last checkpoint as the intermediate starting point in a new training session: in the train.sh file the merged checkpoint uploaded previously to the hub --model_path="stmnk/querycoder-checkpoint-500-merged" will be used as the starting point. Correspondingly, after the training ends, the new merge.sh file will contain --base_model_name_or_path stmnk/querycoder-checkpoint-500-merged \ and, for example, --peft_model_path checkpoints/checkpoint-750 \.
After any merged checkpoint it is useful to measure the achieved progress by comparing the trained model against the baseline. After 500 epochs the evaluation contains a noticeable improvement signal to: 0.454
3.1. Retriever Augmented GenerationAn additional way to improve the quality of the task is to integrate content from relevant documents retrieved from the vector database. The following snippet gives a brief example of using such a template inside a Haystack pipeline:
import torch
from haystack_integrations.document_stores.opensearch import OpenSearchDocumentStore
from haystack_integrations.components.retrievers.opensearch import OpenSearchEmbeddingRetriever
from haystack.components.embedders import SentenceTransformersTextEmbedder
from haystack.components.retrievers import InMemoryEmbeddingRetriever
from haystack.components.builders.prompt_builder import PromptBuilder
from haystack.components.generators import HuggingFaceLocalGenerator
from haystack import Pipeline
document_store = OpenSearchDocumentStore(
hosts="http://localhost:9200",
verify_certs=False, http_auth=("admin", "admin")
)
prompt_template = """
Generate a clear, interesting and challenging question about
the topics discussed in the following documents:
{% for doc in documents %}
{{ doc.content }} URL:{{ doc.meta['url'] }} \n
{% endfor %}
Provide an output the given task: {{task}}
Also include the URL or the URLs of the most relevant document or documents used.
Question
"""
prompt_builder = PromptBuilder(template=prompt_template)
query_embedder = SentenceTransformersTextEmbedder()
retriever = OpenSearchEmbeddingRetriever(
document_store=document_store, top_k=3)
llm = HuggingFaceLocalGenerator(
"stmnk/querycoder-checkpoint-500-merged",
huggingface_pipeline_kwargs={ "device_map":"auto" },
generation_kwargs={"max_new_tokens": 350}
)
llm.warm_up()
pipeline = Pipeline()
pipeline.add_component(instance=query_embedder, name="query_embedder")
pipeline.add_component(instance=retriever, name="retriever")
pipeline.add_component(instance=prompt_builder, name="prompt_builder")
pipeline.add_component(instance=llm, name="llm")
pipeline.connect("query_embedder.embedding", "retriever.query_embedding")
pipeline.connect("retriever.documents", "prompt_builder.documents")
pipeline.connect("prompt_builder", "llm")
query = "The Pytorch nn class"
task = "Multiple choice question"
result = pipeline.run(data={
"query_embedder": {"text": query},
"prompt_builder": {"task": task}
})
print(result['llm']['replies'][0])This can increase the quality of the generated interrogative task because the most semantically relevant documents for the topic of interest are retrieved from the vector database and used as reference domain knowledge in the generation step.
3.2. Further Training workflowAdditional extensions to the current workflow can further improve the quality of the generated tasks, to only list a few of them: increase the number of training epochs to the same order of magnitude as the dataset size, use a model that can also integrate code content in the synthetic data generation process (e.g. Magpie with starcoder2-instruct), filter out low quality training examples from the synthetic dataset, add more high quality coding questions and exercises to the training examples, etc. These are all activities that have remained so far outside the scope of the project, however, can be continued in the future by engaging the larger community in the process.
{kind=link}


Comments