

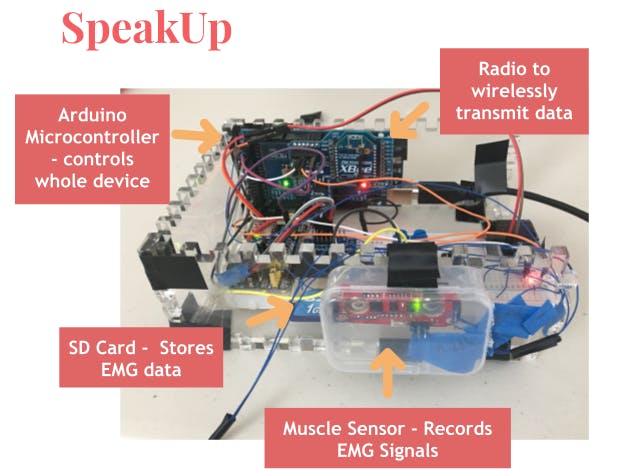
Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
Hand tools and fabrication machines | ||||||
 |
| |||||
 |
| |||||
 |
| |||||
SpeakUp Awards:
- Regeneron ISEF Qualifier
- National Junior Science and Humanities Symposium (JSHS) Qualifier
- Presidential Scholar Nominee
- Yale Science and Engineering Association Award
- Best in Fair - KY Junior Science and Humanities Symposium (JSHS)
- Best in Fair - Manual Regional Science Fair
Full Video Presentation: https://youtu.be/GxwxZFTKc80
Presentation PPT: https://docs.google.com/presentation/d/1e_WGeoaQSWnqME7_1Wl2LELKhdXN2fePrionNfxkFGY/edit?usp=sharing
Project Summary:I have designed and developed a speech interfaced for the paralyzed, using which they can communicate without speaking. As paralyzed people can not speak. this device detects speech-related electrical signals from the throat and converts them into letters or words that we recognize.
Abstract:With upwards of 7.5 million people suffering from speech impediments, it is imperative that low-cost efficient speech aid is developed. Conditions such as stroke ALS and cerebral palsy impair patients’ ability to speak. Some people, who can afford, use currently available cumbersome and inefficient devices such as eye/cheek trackers. In this research study, a speech aid known as a Silent Speech Interface (SSI) was created. This device could be used by patients with speech disorders to communicate voicelessly, merely by articulating words or sentences in the mouth without producing any sounds. This device captures and records subtle neurological activation of the speech muscles from the surface of the skin. In simpler terms, the SSI records electrical EMG signals in the Speech system. These EMG signals are then classified into speech in real-time using a trained Machine Learning model. This device has an accuracy of 80.1% and was developed for a cost of less than $100. Overall, this study involves the creation of a device that measures biological signals to determine what an individual wants to communicate and translates the collected signals into the English language using the SVM machine learning model.
Device Logistics:When a patient is paralyzed, he can’t use muscles in the throat and mouth to speak, however, the brain still sends electrical signals to the speech system which causes the muscles to generate EMG signals. Using modern sensors such as the “Myoware muscle sensor” I am able to tap into this signal. These signals are in a waveform and are quite predictable in their pattern depending on the word spoken. However, these signals are hard to decipher with the human eye. This is why I used Machine Learning algorithms to decipher these EMG signals to predict what word was spoken.
Procedure/Methodologya) Creation of an EMG Recorder:An Arduino Based “EMG Recorder” was created using the Myoware Muscle sensor which could record EMG signals from the throat and save them on an SD card. This would aid in the creation of a dataset to train ML models.
b) Data Collection for training ML models:Three electrodes were attached to the submental triangle (throat). A total of 1020 recordings were taken, 170 for each of the 5 vowels and another 170 to establish a baseline of not speaking at all. After placing electrodes, the letter spoken was selected on the device. The button was then pressed to record the EMG signals produced. This process was repeated a total of 1020 times to obtain 1020 strings of EMG values.
After using the EMG recorder to collect 1020 strings of comma-delimited values, all the collected data was stored onto the SD card. The data was then taken from the SD card and imported into the computer as a text file. This text file was converted into a data table using the filter tool in excel.
c) Training of the Machine Learning Model:An SVM Machine Learning Model was trained on the EMG dataset. This model was used as it was found to be the most accurate model in a preliminary test.
After the model was trained, the ML model yielded an 80.1% accuracy. This indicated that the speech aid created will be able to translate EMG signals from the throat into the English language with a corresponding 80.1% accuracy.
d) Website BuildingA website was built using Streamlit, a website development software. This website allowed the user of the speech aid to control the device and display the spoken words.
e) Final Product - Speech AidThe EMG recorder (from step a), the trained ML model (from step c), and the website (from step d) were all combined to yield the final product.
When the user spoke a word silently, the EMG recorder would wirelessly send recorded EMG signals to a computer. This computer then uses the trained ML model to determine what was spoken. The words spoken are then displayed on the website for everyone to see and read. Using this device, the user can merely think about what they want to say and the words will automatically be displayed on a website for an audience to read.




_3u05Tpwasz.png?auto=compress%2Cformat&w=40&h=40&fit=fillmax&bg=fff&dpr=2)


Comments