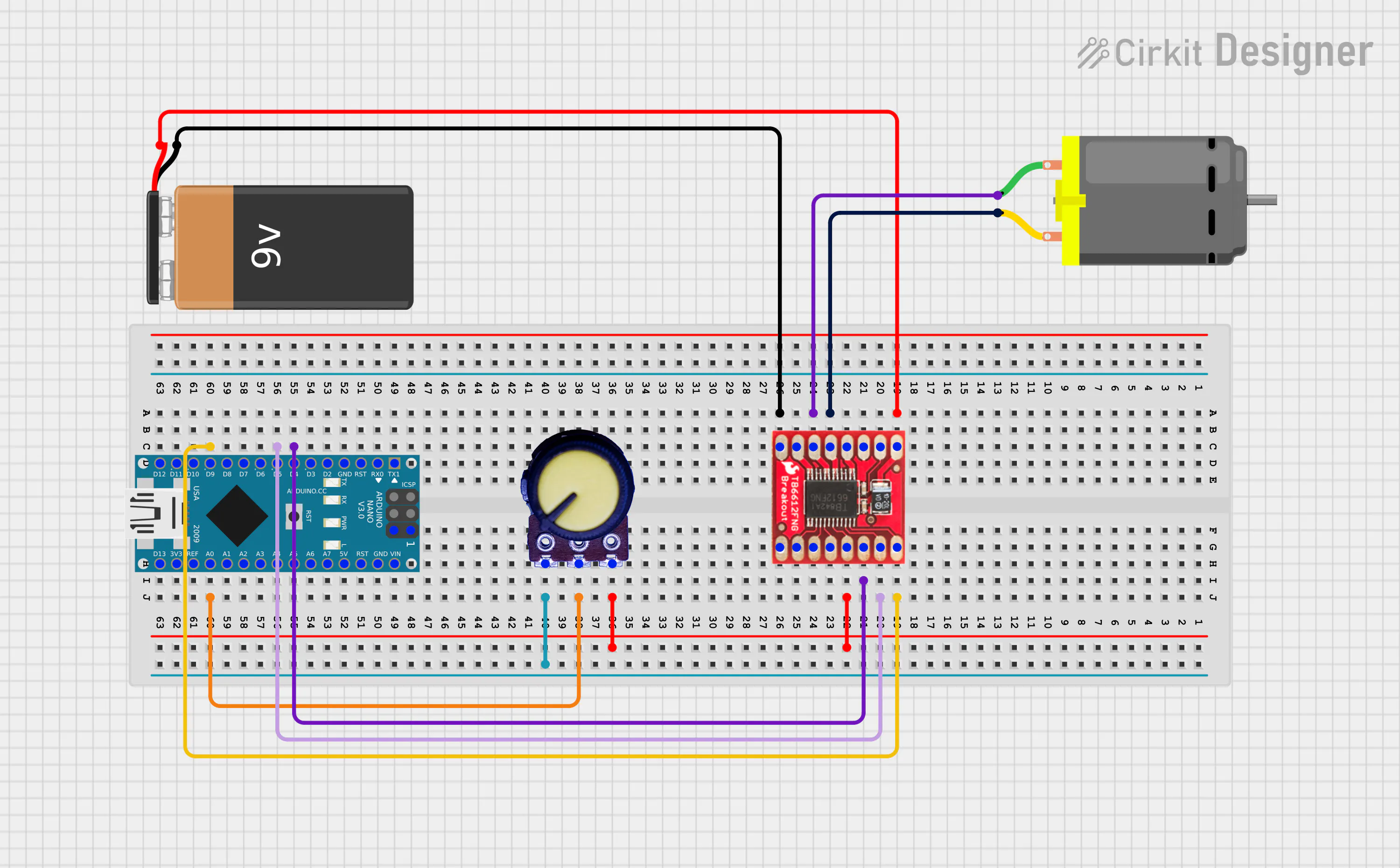
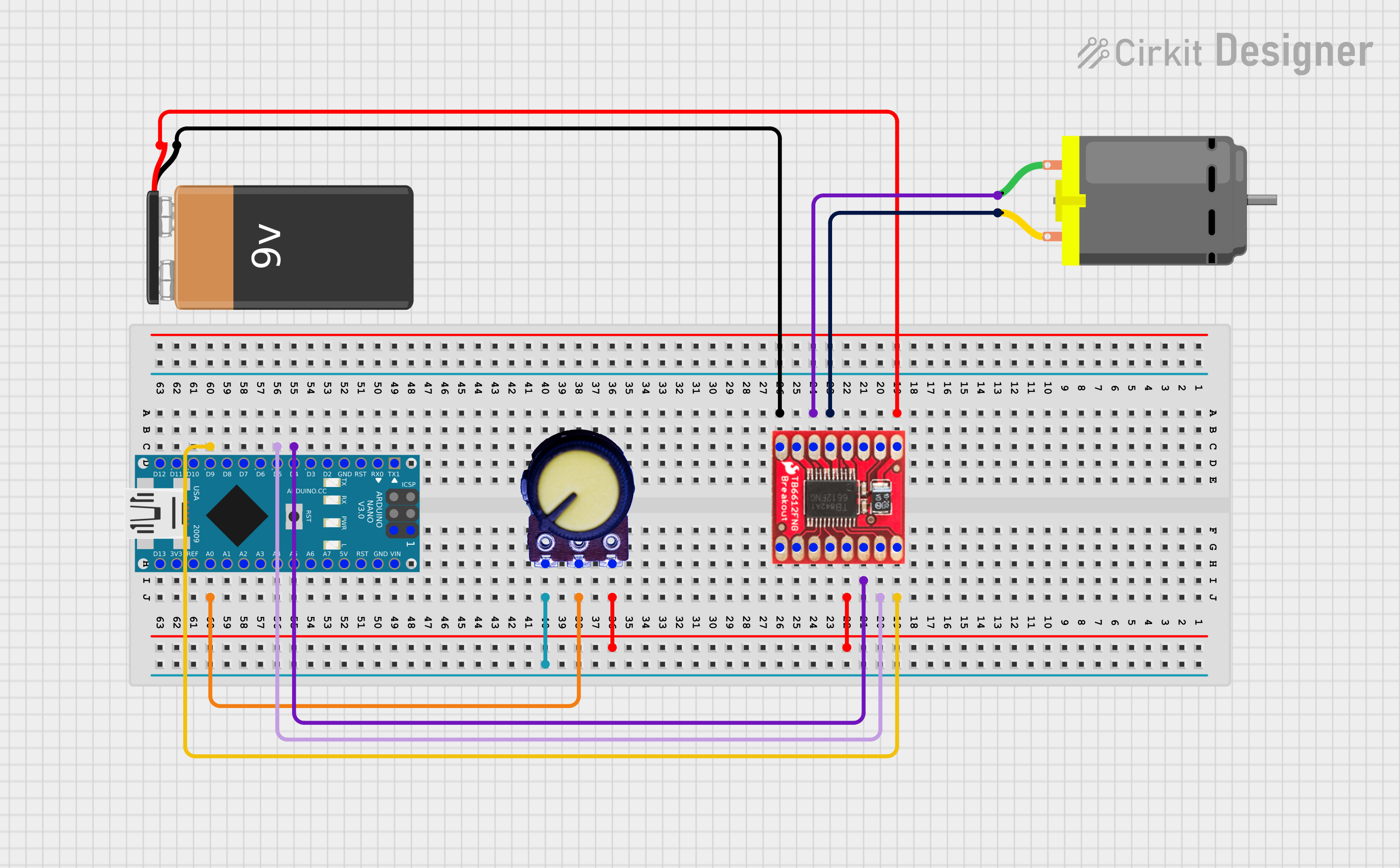
The Philosophy: Efficiency Through Bare-Metal:In the development of mobile robotics, Motion Control is a critical bottleneck. Standard abstraction layers, while user-friendly, often introduce significant overhead. For instance, the default analogRead() function in the Arduino IDE consumes approximately 104µs of blocking time. In a high-speed control loop, this is a "dead time" that could be used for complex PID calculations or sensor fusion.
This project focuses on pushing the ATmega328P to its limits by implementing a Bare-Metal approach. By bypassing the standard libraries and interfacing directly with the hardware registers, we achieve a non-blocking architecture that effectively utilizes every clock cycle.Firmware Architecture & Data Flow
The system is structured into three specialized layers to ensure both performance and maintainability:
- Low-Level Configuration: These functions perform direct register manipulation to initialize peripherals. This includes defining the PWM carrier frequency, configuring GPIO operation modes, and optimizing the ADC sampling time for high-speed response.
- Custom Abstraction Layer (HAL): To maintain code readability without sacrificing speed, I developed a custom HAL. These functions encapsulate safe hardware procedures—such as register clearing and atomic pin operations—into single, efficient calls.
- Optimized Execution Loop: By integrating these configurations, the void loop achieves seamless control execution. The result is an environment that feels as intuitive as standard Arduino coding but operates with significantly higher throughput and lower latency.
Key Achievements:By shifting to a register-level this project demonstrates:
- Minimal CPU Overhead: Drastically reduced by offloading the ADC process to hardware interrupts, allowing for true background processing.
- Enhanced Control Precision: Achieved through high-resolution PWM and deterministic sampling rates.
- Scalability: This Bare-Metal foundation serves as the "brain" for an upcoming high-speed Line Follower, where 16-sensor multiplexing and fixed-point PID calculations will benefit from the reclaimed CPU cycles.
- Video of the code working!










_3u05Tpwasz.png?auto=compress%2Cformat&w=40&h=40&fit=fillmax&bg=fff&dpr=2)
{kind=link}
Comments