




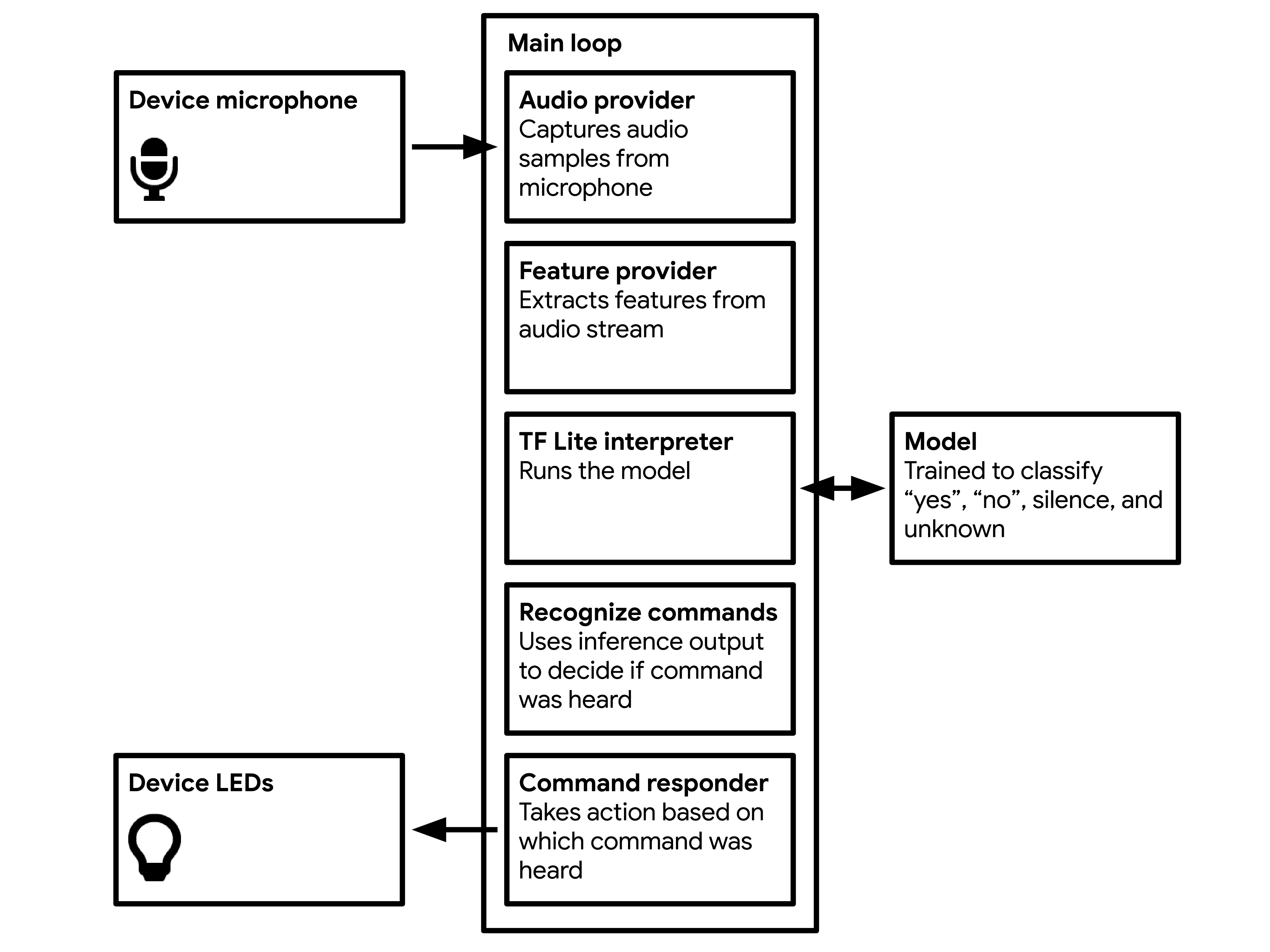
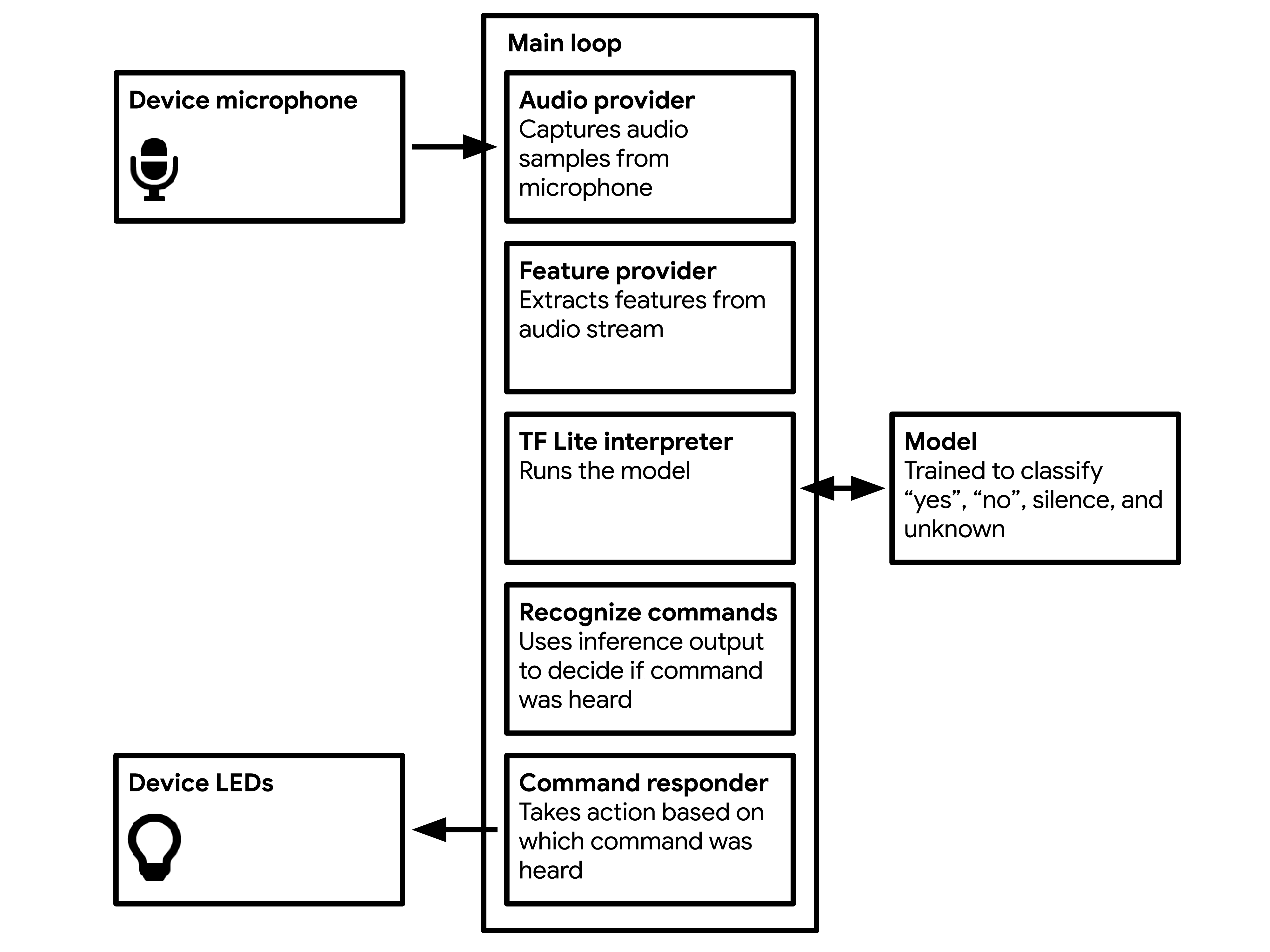
Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
 |
| |||||
| ||||||
| ||||||
Working on TinyML with an Arduino board was one of the most interesting class projects we have encountered. Having taken other courses on Machine Learning (ML), we are no stranger to the "magic" of ML. However, deploying a sophisticated ML model on a small and inexpensive board opened our eyes to the amazing possibilities uncovered by the developing field of TinyML. We have a newfound respect for the developers of the TensorFlow-Lite library and IoT devices. The field of TinyML is enabling ultralow-powered devices to perform ML at the edge, and this project has been an exciting and informative introduction to this area of research.
The class lectures and this project have provided us the knowledge and intuition we require to develop innovative applications of ML models on small devices. We look forward to exploring these avenues, while closely following the advancements in the field via conferences like the TinyML Summit and the AIoT Dev Contest. Overall, we are excited to continue working on TinyML even after this semester is over. The following sections provide details about deploying the wake-word detection project on the Arduino Nano 33 BLE Sense.
Running the Application on macOSSoftware Requirements
- The Terminal
- GNU Make, version 3.82 or later
To check the version of your Make, open the Terminal and use the following command
$ make -vIf your Make version is lower than 3.82, go to the Make website and download any version that is 3.82 or later.
Make: https://www.gnu.org/software/make/
Make download: http://ftp.gnu.org/gnu/make/
Running on the Terminal
After getting the correct version of Make, follow these steps to run the application:
1. Open the terminal.
2. Change to the directory of TensorFlow.
3. Use the following command to build the application.
$ make -f tensorflow/lite/micro/tools/make/Makefile micro_speech4. Once the build completes, run the following command.
$ tensorflow/lite/micro/tools/make/gen/osx_x86_64/bin/micro_speech5. If you see a pop-up asking for microphone access, grant it.
6. Now you can try saying "yes" and "no". You should see output that looks like the following.
First, we run the following command to generate our own Zip file.
make -f tensorflow/lite/micro/tools/make/Makefile \
TARGET=arduino TAGS="portable_optimized" generate_micro_speech_arduino_library_zipThen we connect our Arduino Nano 33 BLE Sense board to a desktop by a cable (USB-A to micro-USB) as follows.
Then we deploy the Zip file to our Arduino Nano 33 BLE Sense board with the Arduino IDE. After deployment, the LED of the board works as the following video shows.
https://drive.google.com/file/d/1SRxZ97gTN93eWm-5sDhme25Re083roS9/view?usp=sharing
We test the wake-word application again. This time, the microphone being used is on the board instead of on the desktop.
From the Arduino IDE, we see similar behavior with the previous test, which indicates that the board works well.
AcknowledgmentsThis project is an implementation of the wake-word detection chapter of the TinyML book.
The source code is from the TensorFlow repository.
micro_speech
BatchFileCommand: make -f tensorflow/lite/micro/tools/make/Makefile micro_speech
Path: tensorflow/lite/micro/tools/make/gen/osx_x86_64/bin/micro_speech
No preview (download only).
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#include "main_functions.h"
// Arduino automatically calls the setup() and loop() functions in a sketch, so
// where other systems need their own main routine in this file, it can be left
// empty.
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#ifndef TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_MAIN_FUNCTIONS_H_
#define TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_MAIN_FUNCTIONS_H_
// Initializes all data needed for the example. The name is important, and needs
// to be setup() for Arduino compatibility.
void setup();
// Runs one iteration of data gathering and inference. This should be called
// repeatedly from the application code. The name needs to be loop() for Arduino
// compatibility.
void loop();
#endif // TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_MAIN_FUNCTIONS_H_
/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#include <TensorFlowLite.h>
#include "main_functions.h"
#include "audio_provider.h"
#include "command_responder.h"
#include "feature_provider.h"
#include "micro_features_micro_model_settings.h"
#include "micro_features_tiny_conv_micro_features_model_data.h"
#include "recognize_commands.h"
#include "tensorflow/lite/experimental/micro/kernels/micro_ops.h"
#include "tensorflow/lite/experimental/micro/micro_error_reporter.h"
#include "tensorflow/lite/experimental/micro/micro_interpreter.h"
#include "tensorflow/lite/experimental/micro/micro_mutable_op_resolver.h"
#include "tensorflow/lite/schema/schema_generated.h"
#include "tensorflow/lite/version.h"
// Globals, used for compatibility with Arduino-style sketches.
namespace {
tflite::ErrorReporter* error_reporter = nullptr;
const tflite::Model* model = nullptr;
tflite::MicroInterpreter* interpreter = nullptr;
TfLiteTensor* model_input = nullptr;
FeatureProvider* feature_provider = nullptr;
RecognizeCommands* recognizer = nullptr;
int32_t previous_time = 0;
// Create an area of memory to use for input, output, and intermediate arrays.
// The size of this will depend on the model you're using, and may need to be
// determined by experimentation.
constexpr int kTensorArenaSize = 10 * 1024;
uint8_t tensor_arena[kTensorArenaSize];
} // namespace
// The name of this function is important for Arduino compatibility.
void setup() {
// Set up logging. Google style is to avoid globals or statics because of
// lifetime uncertainty, but since this has a trivial destructor it's okay.
// NOLINTNEXTLINE(runtime-global-variables)
static tflite::MicroErrorReporter micro_error_reporter;
error_reporter = µ_error_reporter;
// Map the model into a usable data structure. This doesn't involve any
// copying or parsing, it's a very lightweight operation.
model = tflite::GetModel(g_tiny_conv_micro_features_model_data);
if (model->version() != TFLITE_SCHEMA_VERSION) {
error_reporter->Report(
"Model provided is schema version %d not equal "
"to supported version %d.",
model->version(), TFLITE_SCHEMA_VERSION);
return;
}
// Pull in only the operation implementations we need.
// This relies on a complete list of all the ops needed by this graph.
// An easier approach is to just use the AllOpsResolver, but this will
// incur some penalty in code space for op implementations that are not
// needed by this graph.
//
// tflite::ops::micro::AllOpsResolver resolver;
// NOLINTNEXTLINE(runtime-global-variables)
static tflite::MicroMutableOpResolver micro_mutable_op_resolver;
micro_mutable_op_resolver.AddBuiltin(
tflite::BuiltinOperator_DEPTHWISE_CONV_2D,
tflite::ops::micro::Register_DEPTHWISE_CONV_2D());
micro_mutable_op_resolver.AddBuiltin(
tflite::BuiltinOperator_FULLY_CONNECTED,
tflite::ops::micro::Register_FULLY_CONNECTED());
micro_mutable_op_resolver.AddBuiltin(tflite::BuiltinOperator_SOFTMAX,
tflite::ops::micro::Register_SOFTMAX());
// Build an interpreter to run the model with.
static tflite::MicroInterpreter static_interpreter(
model, micro_mutable_op_resolver, tensor_arena, kTensorArenaSize,
error_reporter);
interpreter = &static_interpreter;
// Allocate memory from the tensor_arena for the model's tensors.
TfLiteStatus allocate_status = interpreter->AllocateTensors();
if (allocate_status != kTfLiteOk) {
error_reporter->Report("AllocateTensors() failed");
return;
}
// Get information about the memory area to use for the model's input.
model_input = interpreter->input(0);
if ((model_input->dims->size != 4) || (model_input->dims->data[0] != 1) ||
(model_input->dims->data[1] != kFeatureSliceCount) ||
(model_input->dims->data[2] != kFeatureSliceSize) ||
(model_input->type != kTfLiteUInt8)) {
error_reporter->Report("Bad input tensor parameters in model");
return;
}
// Prepare to access the audio spectrograms from a microphone or other source
// that will provide the inputs to the neural network.
// NOLINTNEXTLINE(runtime-global-variables)
static FeatureProvider static_feature_provider(kFeatureElementCount,
model_input->data.uint8);
feature_provider = &static_feature_provider;
static RecognizeCommands static_recognizer(error_reporter);
recognizer = &static_recognizer;
previous_time = 0;
}
// The name of this function is important for Arduino compatibility.
void loop() {
// Fetch the spectrogram for the current time.
const int32_t current_time = LatestAudioTimestamp();
int how_many_new_slices = 0;
TfLiteStatus feature_status = feature_provider->PopulateFeatureData(
error_reporter, previous_time, current_time, &how_many_new_slices);
if (feature_status != kTfLiteOk) {
error_reporter->Report("Feature generation failed");
return;
}
previous_time = current_time;
// If no new audio samples have been received since last time, don't bother
// running the network model.
if (how_many_new_slices == 0) {
return;
}
// Run the model on the spectrogram input and make sure it succeeds.
TfLiteStatus invoke_status = interpreter->Invoke();
if (invoke_status != kTfLiteOk) {
error_reporter->Report("Invoke failed");
return;
}
// Obtain a pointer to the output tensor
TfLiteTensor* output = interpreter->output(0);
// Determine whether a command was recognized based on the output of inference
const char* found_command = nullptr;
uint8_t score = 0;
bool is_new_command = false;
TfLiteStatus process_status = recognizer->ProcessLatestResults(
output, current_time, &found_command, &score, &is_new_command);
if (process_status != kTfLiteOk) {
error_reporter->Report("RecognizeCommands::ProcessLatestResults() failed");
return;
}
// Do something based on the recognized command. The default implementation
// just prints to the error console, but you should replace this with your
// own function for a real application.
RespondToCommand(error_reporter, current_time, found_command, score,
is_new_command);
}
/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#ifndef TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_AUDIO_PROVIDER_H_
#define TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_AUDIO_PROVIDER_H_
#include "tensorflow/lite/c/c_api_internal.h"
#include "tensorflow/lite/experimental/micro/micro_error_reporter.h"
// This is an abstraction around an audio source like a microphone, and is
// expected to return 16-bit PCM sample data for a given point in time. The
// sample data itself should be used as quickly as possible by the caller, since
// to allow memory optimizations there are no guarantees that the samples won't
// be overwritten by new data in the future. In practice, implementations should
// ensure that there's a reasonable time allowed for clients to access the data
// before any reuse.
// The reference implementation can have no platform-specific dependencies, so
// it just returns an array filled with zeros. For real applications, you should
// ensure there's a specialized implementation that accesses hardware APIs.
TfLiteStatus GetAudioSamples(tflite::ErrorReporter* error_reporter,
int start_ms, int duration_ms,
int* audio_samples_size, int16_t** audio_samples);
// Returns the time that audio data was last captured in milliseconds. There's
// no contract about what time zero represents, the accuracy, or the granularity
// of the result. Subsequent calls will generally not return a lower value, but
// even that's not guaranteed if there's an overflow wraparound.
// The reference implementation of this function just returns a constantly
// incrementing value for each call, since it would need a non-portable platform
// call to access time information. For real applications, you'll need to write
// your own platform-specific implementation.
int32_t LatestAudioTimestamp();
#endif // TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_AUDIO_PROVIDER_H_
/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#include "audio_provider.h"
#include "PDM.h"
#include "micro_features_micro_model_settings.h"
namespace {
bool g_is_audio_initialized = false;
// An internal buffer able to fit 16x our sample size
constexpr int kAudioCaptureBufferSize = DEFAULT_PDM_BUFFER_SIZE * 16;
int16_t g_audio_capture_buffer[kAudioCaptureBufferSize];
// A buffer that holds our output
int16_t g_audio_output_buffer[kMaxAudioSampleSize];
// Mark as volatile so we can check in a while loop to see if
// any samples have arrived yet.
volatile int32_t g_latest_audio_timestamp = 0;
} // namespace
void CaptureSamples() {
// This is how many bytes of new data we have each time this is called
const int number_of_samples = DEFAULT_PDM_BUFFER_SIZE;
// Calculate what timestamp the last audio sample represents
const int32_t time_in_ms =
g_latest_audio_timestamp +
(number_of_samples / (kAudioSampleFrequency / 1000));
// Determine the index, in the history of all samples, of the last sample
const int32_t start_sample_offset =
g_latest_audio_timestamp * (kAudioSampleFrequency / 1000);
// Determine the index of this sample in our ring buffer
const int capture_index = start_sample_offset % kAudioCaptureBufferSize;
// Read the data to the correct place in our buffer
PDM.read(g_audio_capture_buffer + capture_index, DEFAULT_PDM_BUFFER_SIZE);
// This is how we let the outside world know that new audio data has arrived.
g_latest_audio_timestamp = time_in_ms;
}
TfLiteStatus InitAudioRecording(tflite::ErrorReporter* error_reporter) {
// Hook up the callback that will be called with each sample
PDM.onReceive(CaptureSamples);
// Start listening for audio: MONO @ 16KHz with gain at 20
PDM.begin(1, kAudioSampleFrequency);
PDM.setGain(20);
// Block until we have our first audio sample
while (!g_latest_audio_timestamp) {
}
return kTfLiteOk;
}
TfLiteStatus GetAudioSamples(tflite::ErrorReporter* error_reporter,
int start_ms, int duration_ms,
int* audio_samples_size, int16_t** audio_samples) {
// Set everything up to start receiving audio
if (!g_is_audio_initialized) {
TfLiteStatus init_status = InitAudioRecording(error_reporter);
if (init_status != kTfLiteOk) {
return init_status;
}
g_is_audio_initialized = true;
}
// This next part should only be called when the main thread notices that the
// latest audio sample data timestamp has changed, so that there's new data
// in the capture ring buffer. The ring buffer will eventually wrap around and
// overwrite the data, but the assumption is that the main thread is checking
// often enough and the buffer is large enough that this call will be made
// before that happens.
// Determine the index, in the history of all samples, of the first
// sample we want
const int start_offset = start_ms * (kAudioSampleFrequency / 1000);
// Determine how many samples we want in total
const int duration_sample_count =
duration_ms * (kAudioSampleFrequency / 1000);
for (int i = 0; i < duration_sample_count; ++i) {
// For each sample, transform its index in the history of all samples into
// its index in g_audio_capture_buffer
const int capture_index = (start_offset + i) % kAudioCaptureBufferSize;
// Write the sample to the output buffer
g_audio_output_buffer[i] = g_audio_capture_buffer[capture_index];
}
// Set pointers to provide access to the audio
*audio_samples_size = kMaxAudioSampleSize;
*audio_samples = g_audio_output_buffer;
return kTfLiteOk;
}
int32_t LatestAudioTimestamp() { return g_latest_audio_timestamp; }
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
// Provides an interface to take an action based on an audio command.
#ifndef TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_COMMAND_RESPONDER_H_
#define TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_COMMAND_RESPONDER_H_
#include "tensorflow/lite/c/c_api_internal.h"
#include "tensorflow/lite/experimental/micro/micro_error_reporter.h"
// Called every time the results of an audio recognition run are available. The
// human-readable name of any recognized command is in the `found_command`
// argument, `score` has the numerical confidence, and `is_new_command` is set
// if the previous command was different to this one.
void RespondToCommand(tflite::ErrorReporter* error_reporter,
int32_t current_time, const char* found_command,
uint8_t score, bool is_new_command);
#endif // TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_COMMAND_RESPONDER_H_
command_responder.cc
C/C++/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#include "command_responder.h"
#include "Arduino.h"
// Toggles the built-in LED every inference, and lights a colored LED depending
// on which word was detected.
void RespondToCommand(tflite::ErrorReporter* error_reporter,
int32_t current_time, const char* found_command,
uint8_t score, bool is_new_command) {
static bool is_initialized = false;
if (!is_initialized) {
pinMode(LED_BUILTIN, OUTPUT);
// Pins for the built-in RGB LEDs on the Arduino Nano 33 BLE Sense
pinMode(LEDR, OUTPUT);
pinMode(LEDG, OUTPUT);
pinMode(LEDB, OUTPUT);
is_initialized = true;
}
static int32_t last_command_time = 0;
static int count = 0;
static int certainty = 220;
if (is_new_command) {
error_reporter->Report("Heard %s (%d) @%dms", found_command, score,
current_time);
// If we hear a command, light up the appropriate LED.
// Note: The RGB LEDs on the Arduino Nano 33 BLE
// Sense are on when the pin is LOW, off when HIGH.
if (found_command[0] == 'y') {
last_command_time = current_time;
digitalWrite(LEDG, LOW); // Green for yes
}
if (found_command[0] == 'n') {
last_command_time = current_time;
digitalWrite(LEDR, LOW); // Red for no
}
if (found_command[0] == 'u') {
last_command_time = current_time;
digitalWrite(LEDB, LOW); // Blue for unknown
}
}
// If last_command_time is non-zero but was >3 seconds ago, zero it
// and switch off the LED.
if (last_command_time != 0) {
if (last_command_time < (current_time - 3000)) {
last_command_time = 0;
digitalWrite(LED_BUILTIN, LOW);
digitalWrite(LEDR, HIGH);
digitalWrite(LEDG, HIGH);
digitalWrite(LEDB, HIGH);
}
// If it is non-zero but <3 seconds ago, do nothing.
return;
}
// Otherwise, toggle the LED every time an inference is performed.
++count;
if (count & 1) {
digitalWrite(LED_BUILTIN, HIGH);
} else {
digitalWrite(LED_BUILTIN, LOW);
}
}
/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#ifndef TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_FEATURE_PROVIDER_H_
#define TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_FEATURE_PROVIDER_H_
#include "tensorflow/lite/c/c_api_internal.h"
#include "tensorflow/lite/experimental/micro/micro_error_reporter.h"
// Binds itself to an area of memory intended to hold the input features for an
// audio-recognition neural network model, and fills that data area with the
// features representing the current audio input, for example from a microphone.
// The audio features themselves are a two-dimensional array, made up of
// horizontal slices representing the frequencies at one point in time, stacked
// on top of each other to form a spectrogram showing how those frequencies
// changed over time.
class FeatureProvider {
public:
// Create the provider, and bind it to an area of memory. This memory should
// remain accessible for the lifetime of the provider object, since subsequent
// calls will fill it with feature data. The provider does no memory
// management of this data.
FeatureProvider(int feature_size, uint8_t* feature_data);
~FeatureProvider();
// Fills the feature data with information from audio inputs, and returns how
// many feature slices were updated.
TfLiteStatus PopulateFeatureData(tflite::ErrorReporter* error_reporter,
int32_t last_time_in_ms, int32_t time_in_ms,
int* how_many_new_slices);
private:
int feature_size_;
uint8_t* feature_data_;
// Make sure we don't try to use cached information if this is the first call
// into the provider.
bool is_first_run_;
};
#endif // TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_FEATURE_PROVIDER_H_
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
// Provides an interface to take an action based on an audio command.
#ifndef TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_COMMAND_RESPONDER_H_
#define TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_COMMAND_RESPONDER_H_
#include "tensorflow/lite/c/c_api_internal.h"
#include "tensorflow/lite/experimental/micro/micro_error_reporter.h"
// Called every time the results of an audio recognition run are available. The
// human-readable name of any recognized command is in the `found_command`
// argument, `score` has the numerical confidence, and `is_new_command` is set
// if the previous command was different to this one.
void RespondToCommand(tflite::ErrorReporter* error_reporter,
int32_t current_time, const char* found_command,
uint8_t score, bool is_new_command);
#endif // TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_COMMAND_RESPONDER_H_






{kind=link}
Comments