



Hardware components | ||||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
| ||||||
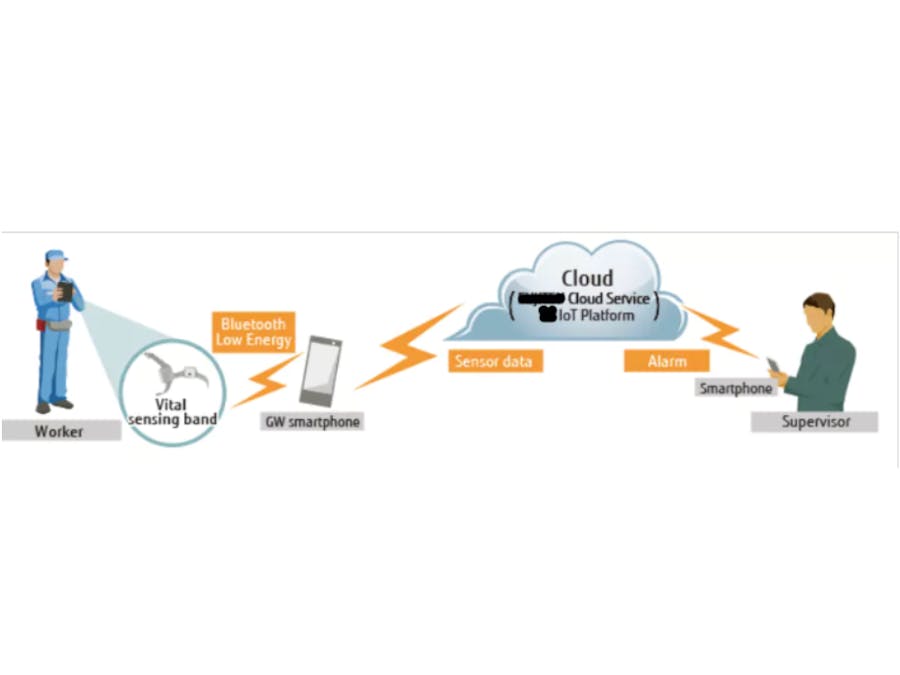
An IoT solution that reduces the risk of industrial accidents and health hazards, reduces costs and improves productivity.
The basic idea is to use a sensor to detect heartbeat and analyze data received through cloud computing, to promptly report heartbeats or abnormalities.
MotivationsAn injury causes a significant balance destabilization of the working environment in which it occurs.
Several studies have shown that an injury determines 128 potential negative consequences, of which 55% would paid by the company.
Direct costs: They are immediately visible and measurable. This category includes:
- Health costs for the injured
- Legal costs
- Insurance costs
- Costs for damage
- Fee Lost production for interruptions caused by accidents
- Staff costs
Indirect costs: require an ad hoc study for each case study, and they vary greatly in relation to the company, the type of business and the circumstances of the accident. Some examples are:
- Strikes resulting costs which reduced productivity
- Workforce Extraordinary costs and Substitutions
- Cost of activities investigation, compiling records and reports with the supervisory authorities
- Damage Image
- Retraining and recruiting costs if the task of the injured workers are modified; due to the high turnover of staff that always occurs in less safe working environments.
Our idea is to monitor the heartbeat of workers through polar optical sensors, save the acquired data in real time to analyze them and, in the event of anomalies or emergencies, send an alarm signal to the workplace supervisor so as to act promptly.
Use of Polar OH1 Heart Rate sensorWe used this sensor that connected to the smartphone allows to obtain the data to be used in our application.
Use of TensorFlow and TensorFlow LiteTensorFlow is an open source library used for creating machine learning applications such as neural networks. It was created by Google.
TensorFlow Lite allows us to deploy machine learning models on mobile and IoT devices.
We use TensorFlow Lite to create a model that will analyze the data gathered from Polar Heart Rate monitor, and then do a prediction whether the worker is stressed or not stressed based on the data read from Polar Heart Rate device, sent to the mobile app.
We train our model by using a machine learning algorithm called Logistic Regression. Logistic regression is a classification algorithm that takes as input the values of Heart Rate and ECG, and does a prediction if the worker is stressed or not stressed(0 or 1). First the model is trained from a dataset.After the train of the model is complete we can use it for prediction.
To use the model in mobile and IoT devices, we have to convert it to TensorFlow Lit format(.tflite) and add it to our mobile application.
Use of AWS IoT Core for exchange messagesAmazon Web Services (AWS) is a secure cloud services platform, offering compute power, database storage, content delivery and other functionality to help businesses scale and grow. Explore how millions of customers are currently leveraging AWS cloud products and solutions to build sophisticated applications with increased flexibility, scalability and reliability.
AWS IoT Core lets connected devices easily and securely interact with cloud applications and other devices.
We used aws iot core to send a message to the user prepared to monitor workers' stress
In particular we used the Publish / Subscribe messaging protocol (MQTT)
MQTT is a machine-to-machine (M2M) / "Internet of Things" connectivity protocol. It was designed as an extremely lightweight publish / subscribe messaging transport.
The idea is that every worker is a topic where he publishes his state of stress while managers have to subscribe to every topic / worker they want to monitor.
Use of Graphite to track the health of workersGraphite is a tool that does two things: storing numeric time-series data (metric, value, epoch timestamp), and rendering graphs of this data on demand. The graphs generated by Graphite are static, as they are generated as images. This is adequate in most cases, but there are times when you want to explore your data in a more interactive way.
Graphite consists of 3 software components:
- carbon - a daemon that listens for time-series data
- whisper - a simple database library for storing time-series data
- graphite webapp - A webapp that renders graphs on-demand
As you send datapoints to Carbon, they become immediately available for graphing in the webapp. The webapp offers several ways to create and display graphs.
Carbon is the storage backend for a Graphite configuration. A single Graphite configuration will have one or more Carbon daemons that are responsible for handling data that is sent over by other processes that collect and transmit statistics.
There are a variety of different Carbon daemons, each of which handle data in a different way.
The most basic of these is called carbon-cache.py. This daemon is straight-forward. It listens for data on a port and writes that data to disk as it arrives, in an efficient way. It stores data as it comes and then flushes it to disk after a predetermined period of time. It is important to recognize that the Carbon component handles the data receiving and flushing procedures. It does not handle the actual storage mechanisms. That is left to the whisper component. The carbon-cache.py daemon is told what formats, protocols, and ports to work on. It also is told what data retention policies to use for data storage. These are given over to whisper.
The carbon-relay.py daemon can be used to send requests to all backend daemons for some redundancy. It can also be used to split data across different carbon-cache.py instances to spread out read loads across multiple storage locations.
The carbon-aggregator.py daemon can buffer data and then dump it into carbon-cache.py after a time. This can help reduce the impact of system statistics processing at the expense of detail.
The most visible and dynamic component of a Graphite installation is the Graphite web application. This is where you can design graphs that plot your data:
Graphite gives you a very flexible interface to design graphs. You can combine different types of metrics, control labeling, fonts, colors, and line properties, and you can resize and manipulate the data at will.
The key idea is that Graphite renders graphs based on the data points it receives and the directions you give it. It doesn't just print out graph and then throw away the data. You can render the data in whatever data you want, on the fly. You can also export the data in non-graphical representations like JSON or CSV, or output an SVG with embedded data information.
LinksLinkedIn accounts:
- Matteo Rizza: https://www.linkedin.com/in/matteo-rizza/
- Lorenzo Leschiera: https://www.linkedin.com/in/lorenzo-leschiera-55a706156/
- Shend Osmanaj: https://www.linkedin.com/in/shendosmanaj/
Slide presentation:
https://www.slideshare.net/LorenzoLeschiera/monitoring-workersstress-levels
GitHub report:










Comments