


Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
Hand tools and fabrication machines | ||||||
 |
| |||||
As the 2nd wave of covid unfolds throughout the world, sustaining through the pandemic has become an everyday challenge. Due to the steep rise in cases, the healthcare industry continues to evolve and is adopting telemedicine to facilitate the accessibility of remote health care services. But using telemedicine we can only diagnose common diseases as no physical examination is possible, which may increase the number of wrong diagnoses. A quite common symptom of covid-19 in the Indian population is the development of respiratory abnormalities, for which Physical inspection is a mandatory process for proper diagnosis.
What if the stethoscope could reveal insights on our health condition just by listen and analyzing the lung sounds at the edge !? The initial inspiration for this project came from the "digital stethoscope" project by Peter Ma.
Proposed SolutionHence the idea is to develop a solution that combines any normal stethoscope paired with a microphone and recording the sound of the respiratory system and performing audio classification at the edge on a microcontroller. In order to get accurate acoustic data, we have to make sure that the data to be processed is free of an anomaly due to power line interference, motion artifacts, etc. Hence we need to include a filtering system consisting of low pass, high pass filters along with an adjustable gain. The filtered signal is then pre-processed using the AudioMFE processing block which extracts time and frequency features from a signal and fed into the neural network.
The model then classifies the recording into one of the 4 classes: Ideal (Stethoscope not being used), Normal ( No abnormalities in lungs), covid ( Lungs sound closely matching to that of a covid patient), wheezing ( Symptom of chronic obstruction or breathing problems. The goal is to build with low-cost off-shelf components that are readily available in the market so that even a non-technical person could easily build this kit by himself. The ability to detect the critical health issue at your disposal beforehand in a lockdown situation is inestimable.
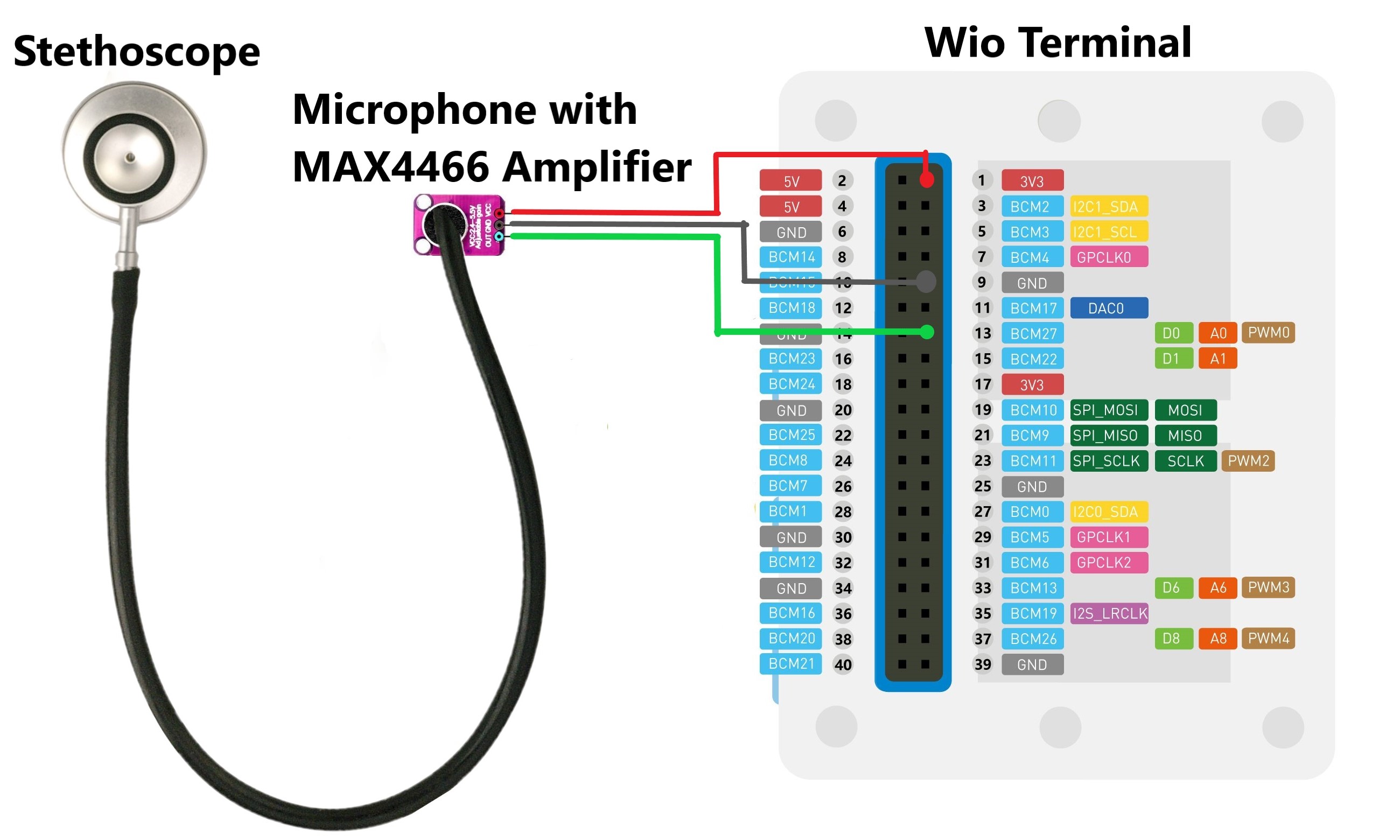
Building Hardware:Here the goal is to build the project with cost-effective as well equally functional components. We need a microcontroller powerful enough to process audio and inference at the edge and being power efficient at the same time. Also, the board should support LCD to display, microSD for saving audio files, and need some pushbuttons for navigation. The Wio terminal from Seeed Studio checks all the boxes and comes with some additional functionality. It's is an Arduino-compatible development board, crammed full of features, well documented, and full of examples codes available for just INR 3400 !!. I won't go into the detailed specifications and why it's a bang for the buck!. Here are some links to get you started:
- https://wiki.seeedstudio.com/Wio-Terminal-Getting-Started/
- https://youtube.com/playlist?list=PLpH_4mf13-A0MzOdPNITVfoVBMvf7Rg9g
The MAX4466 Electret Microphone Amplifier has a good signal-to-noise ratio with an adjustable gain, is cheap, and readily available. The sounds of lungs mostly belong to the lower-frequency spectrum ( human audible range), hence we need not have a microphone with a wide frequency band. If you want to learn more about how sound processing is done, you can head out to the Sound Processing section of the Audio Scene Recognition project by Dmitry Maslov.
The IndoSurgicals Silvery II-SS Stethoscope performs well to deliver lung sounds exceptionally well for the price point.
We need to cut the stethoscope near the end of the tube (where it starts to split into two) as this area has a larger radius that perfectly fits over the Electret Microphone and attaches the mic firmly to the tube ensuring that there is no leakage of sound. Additionally, you can also add an adhesive to seal the tight ensuring not to damage the microphone in the process.
I have mounted the Wio terminal and the microphone to cardboard, perhaps to reduce motion artifacts during measurements. Below is a picture of the hardware setup after all connections are made.
The output of the microphone is analog in nature, hence we need to feed/connect it into one of the channels of ADC of the Wio terminal. I have used the A0 (BCM27) pin for the same. You can refer to Shawn's Guide of how to use ADC's.
Also, the reasons I chose not to go use the on-board microphone (instead of an external microphone ) are mentioned below:
- Difficult to mount the Stethoscope on it.
- The Onboard microphone is set up to only give sound levels, not feasible for actual audio sampling.
Before collecting the sound data we need to adjust the gain of the microphone, so as it hit a sweet sport between amplifying the sound of our interest and noise. To simplify things you can use the Wio_Terminal_Microphone_Chart.ino code developed by Ralph Yamamoto. It displays the analog values on the LCD of the Wio terminal inform of a continuous chart. This is quite intuitive. Rotate the gain potentiometer clockwise or anticlockwise according to the magnitude of values on the screen, ensuring that the sound of our interest ( lungs sounds) is not clipped off and is reasonably amplified and noise amplification is minimum.
After calibrating the microphone we need to record and save the audio in the ".wav" file format on the SD card. A sample example code is available on GitHub, derived from the work done by Dmitry Maslov. PlatformIO has been my go-to IDE for all my firmware needs related to the Arduino framework. Here is a walkthrough to set up PlatformIO for Wio Terminal: https://wiki.seeedstudio.com/Software-PlatformIO/.
Once you are done with the setup and having flashed the program onto the Wio Terminal, place the stethoscope firmly on auscultation points and press the button 'A' on the Wio terminal when you are ready, and start your breathing cycle until the recording is stopped. Repeat this multiple times with different points on the chest and with different clothes being put on along with background noise. The example code records 5 seconds of acoustic data at a sampling frequency of 16Khz and stores it on the SD card in '.wav' format. You can also open the Serial Terminal to get debug messages.
Since it's quite risky to visit patients with respiratory disorder and collect real samples of lung abnormalities through our device, so I collected real audio samples of my lungs ( assuming that it is functioning normally) and other samples were collect by the playing the sounds on a speaker and capturing it through the stethoscope. Here are links to the playlist containing sounds of lung abnormalities.
https://www.medzcool.com/auscultate
According to medical journals mentioned below, the normal classification of lung sounds in frequency bands involves low (100 to 300 Hz)-, middle (300 to 600 Hz)-, and high (600 to 1, 200 Hz)- frequency bands and in the range of lower frequencies (< 100 Hz), heart and muscle sounds overlap.
- Asymmetry of respiratory sounds and thoracic transmission
- The Relationship between Normal Lung Sounds, Age, and Gender
- Effect of Airflow Rate on Vibration Response Imaging in Normal Lungs
Hence the sampling rate used in our device is high enough for capturing the acoustic events of our interest. We need to create a bandpass filter ( 100 - 1200 Hz) so that information related to lung sound characteristics is preserved while removing heart and muscle sounds. We would be creating a digital filter during our upcoming steps using Edge impulse in order to filter heart/muscle sounds. If you want to create an analog filter please refer to my previous project, where I have used an analog filter.
Building Model :After sufficient data is curated, the next step is to leverage Edge Impulse platform to process data and train a model. A quick into "Edge Impulse is an emerging startup that is doing a great job in bridging the gap between firmware/hardware engineers and Machine Learning engineers. A huge variety of inputs can be processed including radar, motion, electromagnetic fields, audio, images, and device logs". Create an account with Edge Impulse and the first time you log in, you will be greeted by a getting started page. This will walk you through the process of connecting a device, gathering data, and finally deploying a model.
Create a new project, name it, and head to the Data Acquisition tab, and click on upload existing data. You can see there various formats in which you can upload the data. We are going to upload all our ".wav" files and label the classes they belong to. You can use automatic splitting of data into training and testing.
After the data collection/uploading is done, it is time to choose processing blocks and define our neural network model to create an impulse. Click on impulse design and you'll four blocks to play with. The first block is for slicing the data in small chunks that are fed into the machine learning model during training. The Window size field controls how long, in milliseconds, each window of data should be and the Window increase field controls the offset of each subsequent window from the first. For this project, I have fixed the window size to 1.5 seconds at this close to the duration of completing one breathing cycle( Inhaling followed by Exhaling).
Next, we need to add a processing block. This is quite tricky to select at there quite a lot of algorithms to serve specific use-cases. Hence we have the luxury to experiment with these blocks. The most accurate processing block that worked this project was Syntiant. For the time being it is only available for the Syntiant board. The next best algorithm that performed exceptionally well is MFE (Mel-filterbank energy). It performs well on audio data, mostly for non-voice recognition use cases when sounds to be classified can be distinguished by the human ear.
In order to filter out the heart and muscle artifact sounds, we need to create a digital filter. We can do that by tweaking the Mel-filterbank energy features parameters under the MFE tab under Impulse Design. Fix 300hz as the Low-frequency band and 1200hz as the high-frequency band, as the lung's sound lies within this range. To learn more about processing blocks visit this document by edge impulse.
The next step is to select a learning block. I chose Neural Network (Keras), as edge impulse suggests it for good audio use-cases. Head to the MFC/Spectrogram tab to generate features. You're free to mess around with MFE parameters in order to achieve the best accuracy. After computing the features, switch to the NN classifier tab and choose a suitable model architecture between 1D or 2D Conv and click start training. Once training is finished, a confusion matrix will be generated on the right side containing all the insights on the model performance. By tweaking the NN and MFE parameters, you can restrict the false positive value to minimum and accuracy to maximum. Once satisfied with the model performance you can move to the live testing or deployment stage.
As we are using PlatformIO with Arduino framework, we need to deploy the model as an Arduino library to integrate with our code. Edge Impulse has a variety of optimization options without much sacrificing on the accuracy. Head over to the optimizations tab to select the one that suits your model the best and download the library.
Once you have downloaded the model, we need to integrate it into our code. Adding an Arduino library in PlatformIO has a different process than adding in the Arduino IDE. The simplest way is to extract the library.zip file and drag-n-drop the folder into the lib directory of the project. Once the library is added to the project, all you need to do is add the library header file that is present in the root directory of the library folder for example "<digital_stethoscope_inference.h>". Now you have access the all the library functions that come along with the model. The firmware is quite simple as it based on the Arduino framework. We have the setup() function for initialization and loop for repetitive tasks. In the Setup function, we perform the following tasks:
- Initialize TFT drivers & Serial Communication,
- Define Analog input pin for the microphone, pinMode for button "A" and attach interrupt to it.
- Initialize the edge impulse classifier function, allocate memory to the audio buffer.
- Push start-up images to the TFT screen.
In the Loop function the following tasks are performed:
- Check if the Key "A" is pressed. If pressed, then start recording audio data using the analogRead function followed by a microsecond delay and filling up the audio buffer. Run the classifier and get the output results and display it on the TFT screen as well as push to the serial terminal.
- If key "A" not pressed display the instruction to start the inference.
The code is available on GitHub for your reference. Make sure to include the following build flags in the platformio.ini file or else you'll receive an empty array when printing results to the serial terminal.
The inference time of 1 second works fine for me. If you want to minimize the inference time you would probably need to incorporate double buffered DMA in your code. Shawn has put a great video implementing this. Blog on Continuous audio sampling by edge impulse might also help you get started.
Moment of Truth:So here is a video demonstrating the working of the project.
Future Scope:
- A better GUI: The Initial plan was to use LVGL alongside Edge Impulse, however, I gave up on it as more often than not the firmware would run into memory leak problems.
- Connection to Cloud: The idea is to use the wifi capabilities of wio terminal to send data, making it accessible to the doctors so that further diagnosis can be performed. ( Yet to start working on this)
- Integrating Record Functionality: On multiple occasions ran into the same memory leakage problem.
( Any kind of help on these is highly appreciated ).
P.S: The project more or less looks like a content curation blog. However, that's the beauty of open-source contributions, that you can leverage others' work to complete your jigsaw which in turn might act as a starting point for someone else.
Thanks to PeterMa, Dmitry Maslov, Shawn Hymel




{kind=link}
Comments