


Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
| ||||||
| ||||||
| ||||||
| ||||||
Most robot-agent demos still operate in a "stop-and-go" mode: the robot moves, waits for the AI to think, and only then continues. This breaks continuous control and makes interactions feel unnatural.
While Vision-Language-Action (VLA) models attempt to solve this by mapping perception directly to actions, they often struggle with live conversation, interruption handling, and reliable failover. I wanted a "middle path": a live multimodal robot agent that keeps moving while the AI thinks, supporting both natural voice interaction and high-level task planning. This led me to build HALO — Hierarchical Adaptive LLM-Operated Robot.
HALO is open source — you can find the code at https://github.com/andrei-ace/HALO
The Stop-and-Go ProblemThe first prototype was humbling. I had a planner calling tools, a simulated arm, and the whole thing froze every time the LLM reasoned about what to do next. Three seconds of inference meant three seconds of a motionless robot. That's not how physical systems work.
Instead of a single prompt loop, we split HALO's intelligence into three asynchronous layers:
- The Live Agent: Built with the Agent Development Kit (ADK) Gemini Live API Toolkit (Bidi-streaming) to handle voice, narration, and "barge-in" interruptions.
- The Planner: An LLM agent using a Reason + Act (ReAct) loop via ADK to orchestrate skills asynchronously.
- The Perception Layer: A Vision-Language Model (VLM) that handles scene understanding off the critical path, ensuring vision latency never blocks motion.
This architecture allows perception and control to run machine-to-machine at up to 100 Hz, while the reasoning layers stay outside the timing-critical loop.
That separation shaped every design decision that followed.
The Perception Problem: VLM Inference vs. Real-Time TrackingOnce the architecture was in place, I hit the next wall: perception. A vision-language model can understand a scene — "there's a red cube near the center of the table" — but it takes hundreds of milliseconds. A robot approaching an object needs tracking updates every 30-50 ms.
My first attempt had the fast tracker waiting for VLM results. Terrible. The second attempt ran them in parallel but had a gap when the VLM finished — the new tracker started from scratch and lost a few hundred milliseconds of motion context.
The solution that worked best was frame-buffer replay. While the VLM runs asynchronously, a ring buffer captures every incoming camera frame. The existing tracker keeps publishing hints uninterrupted. When the VLM completes, a new tracker is initialized from the VLM result and the buffered frames are replayed through it, fast-forwarding it to the present. Only then does the service switch over. No gap, no stale hints.
I later split VLM inference into two concurrent paths — one for scene description, one for tracking — so an operator asking "what do you see?" doesn't block target acquisition. That came from a real debugging session where scene description and target tracking were fighting over the same VLM lock.
Giving the Robot a Voice with Gemini Live APIThe next big milestone was making HALO conversational. The Gemini Live API via Google ADK turned out to be a natural fit for the Live Agent — the conversational voice layer between the operator and the system. Native audio in and out as a single streaming session, with tool-calling built in. No separate ASR to LLM to TTS pipeline to stitch together.
Separately, the task-level PlannerService is implemented as an ADK ReAct agent with three core tools: start_skill, abort_skill, and describe_scene. The Live Agent and the planner are distinct: the Live Agent handles conversation and narration, while the planner handles skill orchestration and recovery. The Live Agent can forward operator intents to the planner, but they run independently.
There was a fundamental problem with the Live Agent, though. Gemini runs in the cloud. The robot state lives locally. By the time a tool result round-trips through the cloud, the arm may have moved, the skill may have advanced, the scene may have changed.
- The Proxy-Tool ArchitectureBecause Gemini runs in the cloud but the robot state exists locally, we built a proxy-tool architecture. Cloud agent calls are intercepted as stubs, serialized over WebSockets, and executed locally against the live 100 Hz hardware state.
- Reliable Failover with LeaseManager To ensure the robot never stops if Wi-Fi drops, HALO fails over to a local Ollama backend (running
gpt-oss:20bandqwen2.5vl:3b). To prevent "split-brain" scenarios—where late cloud commands collide with local ones—we implemented a LeaseManager. It stamps every command with an epoch token, instantly invalidating stale commands from the inactive backend.
This pattern also made barge-in straightforward — when Gemini detects the operator interrupting, the TUI clears the audio buffer instantly so the robot's response stops mid-sentence.
Deploying to Google Cloud (and Coming Back)Getting HALO's cloud service running on Cloud Run was straightforward — a FastAPI app with WebSocket support, containerized and deployed. Firestore stores planner session state so the system can recover after disconnects. Secret Manager keeps the Gemini API key out of the codebase. Terraform wraps all of it so a single command brings up the full stack.
The interesting engineering challenge was what happens when the cloud goes away.
Real robots can't stop when connectivity drops. So I built a Cognitive Switchboard that routes between Gemini 3.1 Flash-Lite (cloud) and Ollama with GPT-OSS 20B + Qwen2.5-VL 3B (local). The switchboard monitors health; after three consecutive cloud failures, it fails over to local. When cloud recovers, it fails back.
Split-Brain and How to Prevent It
The naive version had a serious problem: a slow Gemini response would arrive after failover and get executed by the command router alongside the local backend's commands. Two brains, one robot, and no reliable source of authority.
The fix was a LeaseManager that stamps every command with an epoch and token. On failover, the epoch increments and the old lease is revoked. The command router rejects any command from a stale epoch — even if it's a perfectly valid Gemini response that just arrived late. During switchover, the new backend is pre-warmed before the old lease is revoked, so there's no gap where neither backend is active.
Context Continuity Across Switches
Preventing split-brain was only half the problem. The other half was making the transition seamless.
The ContextStore maintains an append-only journal of decisions and events. On failover, the new backend gets a compacted summary so it can resume mid-task instead of starting cold. Both backends track a cursor so failback doesn't replay already-processed entries.
Session Compaction: When Context Windows Fill UpLong-running Gemini sessions hit another problem: the context window fills up. The Live Agent accumulates audio transcripts, tool calls, tool results, and conversation history. In longer sessions, context growth started to hurt responsiveness and overall session quality.
I built a compaction plugin using ADK's BasePlugin and EventCompaction primitives. After each agent turn, it checks if the session has grown past a threshold. If so, it finds a compaction boundary, summarizes everything older via LLM, and keeps a configurable overlap window of recent turns. The result is a compact summary that stays within budget without losing the task-level context the agent needs to continue.
The same compaction feeds into the cross-backend sync: when Gemini compacts a session, the summary propagates to the local backend's history through the ContextStore, so failover doesn't lose the conversation.
Adding Skills Without Rewiring the RuntimeOne design goal for HALO was that adding a new robot skill should not mean rewriting the runtime. I did not want every new behavior to require a custom control loop, a new orchestration path, or special-case planner logic.
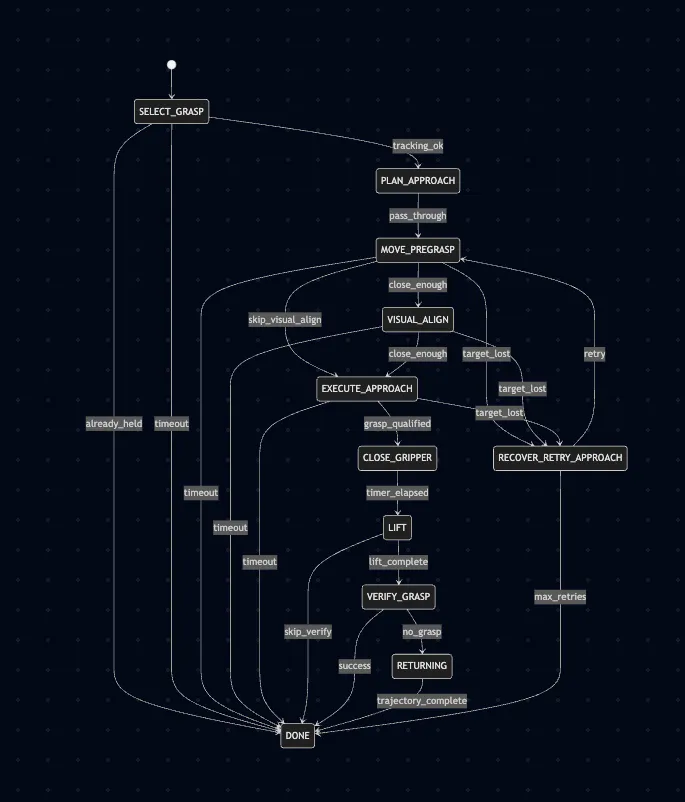
So skills in HALO are defined as state machines authored in Mermaid. Each skill such as pick, place, or track lives as a stateDiagram-v2 file, and the FSM engine parses that diagram into an executable graph at startup. The runtime does not care whether the graph came from a hand-written Python class or a diagram file; it only sees states, transitions, guards, and handlers.
That changes the development workflow in a useful way. To add a skill, I define the state topology visually, attach the relevant state handlers, and let the generic engine execute it. In practice, this means I can extend behavior by changing the skill definition rather than by modifying the orchestration core.
It also makes recovery behavior much easier to reason about. Instead of hiding retries and fallback logic inside imperative code, HALO keeps them explicit in the skill graph itself. For example, the pick flow includes recovery states and guarded transitions such as retrying the approach or re-grasping after a failed verification step. A deterministic check like “did the object actually move upward during lift?” stays inside the FSM and does not need an LLM decision. Only when the skill exhausts its built-in recovery options does control go back up to the planner.
The result is a system where skill logic is easier to inspect, easier to debug, and easier to extend. The runtime stays generic, while the behavior lives in diagrams that are readable by both humans and code.
The MuJoCo simulation with an SO-101 arm model is where everything comes together. I also wanted to generate demonstration episodes for future imitation learning, and that turned out to be harder than the runtime itself.
Early trajectories collided with the table, had jerky motion, or produced unreliable grasps. Over several iterations I built a pipeline that scores grasp candidates, generates keyframes, solves inverse kinematics with fallbacks, produces jerk-limited trajectory profiles, and validates every segment for clearance. The result is smooth, physically plausible demonstrations across randomized object placements.
Training PipelineWith the runtime backbone complete, the next milestone is closing the loop: turning sim demonstrations into learned policies that run on real hardware.
How Skills Are Added
Adding a new skill to HALO follows a repeatable pipeline:
1. Define the FSM — author a Mermaid stateDiagram-v2 diagram (e.g. configs/skills/pick/default.mmd). The FSM engine parses it directly — no code changes needed for new topologies.
2. Write a teacher — a MuJoCo solver that produces full trajectories using the 64-candidate grasp planner, damped least-squares IK, and jerk-limited Ruckig motion profiles. The teacher labels each timestep with the corresponding FSM phase_id.
3. Generate episodes — run the teacher across randomised scenes (make generate-episodes EPISODES=100). Each episode is an HDF5 file containing dual-camera RGB, joint states, end-effector poses, actions, and per-timestep phase labels — the same schema whether data comes from sim, teleoperation, or real hardware.
4. Train ACT — Action Chunking with Transformers learns to predict sequences of future joint-position targets from camera images and proprioception.
5. Build detectors — at runtime, sensor-based detectors replace the teacher's ground-truth phase signals to drive FSM transitions autonomously.
Episode Format
Every episode uses an identical HDF5 schema regardless of source:
ep_NNNNNN.hdf5
├── obs/
│ ├── rgb_scene (T, H, W, 3) — scene camera
│ ├── rgb_wrist (T, H, W, 3) — wrist camera
│ ├── qpos, qvel, gripper, ee_pose, joint_pos
│ ├── phase_id (T,) int32 — FSM state label per timestep
│ ├── object_pose (T, 7) — target object pose
│ └── bbox_xywh, tracker_ok, contacts/
├── action (T, 6) — joint-position targets
└── attrs: seed, env_name, robot, control_freq, ...
This schema invariant is critical: train/val/test splits are by episode seed and object placement (not by timestep), and recorded actions replayed in sim must reproduce the original episode before any training begins.
Phase Detectors
This is the piece that connects learned policies back to the FSM engine. During teacher episodes, phase_id is ground truth — the solver knows exactly what phase it's in. During ACT inference, that signal disappears. Detectors fill the gap by reading sensor data to determine FSM state transitions:
- Gripper position and current — gripping something, or closed on air?
- Wrist camera — object visible in frame? Grip looks successful?
- Joint state — reached target position within tolerance?
- Contact forces — touching the object? (sim initially, force-torque sensor on real hardware later)
Heuristic detectors come first. Learned detectors — trained on human-annotated episodes — come later.
VCR: Episode Replay & Annotation
VCR (planned) is a tool for scrubbing through recorded episodes frame-by-frame — scene camera, wrist camera, joint states, phase timeline — and annotating FSM phase boundaries on each timestep. Annotations go in a sidecar JSON file; the HDF5 stays immutable. This serves double duty: reviewing teacher label quality and creating training data for learned detectors.
Teleoperation
Teacher solvers produce optimal trajectories, but real manipulation needs messier, more diverse data. Teleoperation (planned) lets an operator drive the robot via keyboard or gamepad through the existing ZMQ bridge, recording episodes in the same HDF5 format. Phase labels are left blank during recording and annotated post-hoc with VCR. Mixing teacher and teleop data produces policies that are both performant and robust.
Closing the Loop
The end state: ACT predicts actions, detectors drive FSM transitions, the FSM engine orchestrates phase sequencing, and the existing safety guard clamps everything before it reaches the motors. The LLM planner stays exactly where it is — choosing which skill to run and what to target — while the entire control path from camera to joint command remains machine-to-machine with no LLM in the loop.
Three Takeaways from Building a Real-Time AgentIf I had to distill three weeks of HALO into advice:
Architecture matters more than model size. A fast, small planner that sees the right abstraction is better than a giant model drowning in raw telemetry. The planner never sees numeric target vectors or joint positions — it sees something like "distance: 0.12 m, confidence: 0.87, phase: EXECUTE_APPROACH" — and that's enough.
Design for failure from day one. Not just model failures — network failures, VLM timeouts, grasp failures, context overflow. Every boundary in the system has a fallback path. That's what makes it feel robust instead of fragile.
Keep the LLM out of the hot path. The moment you put inference in a timing-critical loop, you've built a demo, not a system. Let the LLM think asynchronously and let deterministic code handle real-time.
HALO is still early, but the architecture already works end to end — from voice to planning to real-time control — and I'm excited to keep pushing it toward real hardware.
Demo: https://www.youtube.com/watch?v=hIvHln6MW2w
Code: https://github.com/andrei-ace/HALO
Devpost: https://devpost.com/software/halo-kolu5w
Built for the Gemini Live Agent Challenge. This post was written as part of our entry to the hackathon.
#GeminiLiveAgentChallenge #Robotics #AI #GeminiAPI #GoogleCloud #MuJoCo #OpenSource






{kind=link}
{kind=link}
Comments